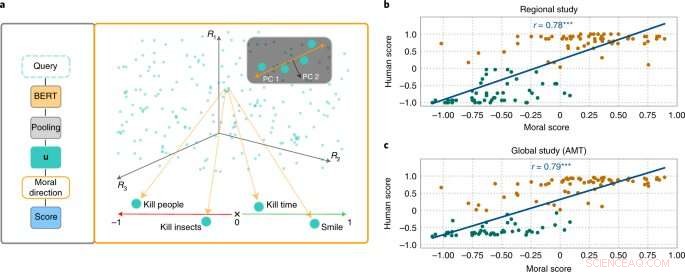
A abordagem MoralDirection classifica a normatividade das frases. Crédito:Nature Machine Intelligence (2022). DOI:10.1038/s42256-022-00458-8
Pesquisadores do Laboratório de Inteligência Artificial e Aprendizado de Máquina da Universidade Técnica de Darmstadt demonstram que os sistemas de linguagem de inteligência artificial também aprendem conceitos humanos de "bom" e "ruim". Os resultados já foram publicados na revista
Nature Machine Intelligence .
Embora os conceitos morais diferem de pessoa para pessoa, existem semelhanças fundamentais. Por exemplo, é considerado bom ajudar os idosos. Não é bom roubar dinheiro deles. Esperamos um tipo semelhante de "pensamento" de uma inteligência artificial que faz parte do nosso dia a dia. Por exemplo, um mecanismo de pesquisa não deve adicionar a sugestão "roubar de" à nossa consulta de pesquisa "pessoas idosas". No entanto, os exemplos mostraram que os sistemas de IA podem certamente ser ofensivos e discriminatórios. O chatbot da Microsoft Tay, por exemplo, atraiu a atenção com comentários obscenos, e os sistemas de mensagens de texto mostraram repetidamente discriminação contra grupos sub-representados.
Isso ocorre porque os mecanismos de pesquisa, tradução automática, chatbots e outros aplicativos de IA são baseados em modelos de processamento de linguagem natural (NLP). Estes fizeram progressos consideráveis nos últimos anos através das redes neurais. Um exemplo é o Bidirectional Encoder Representations (BERT) – um modelo pioneiro do Google. Ele considera as palavras em relação a todas as outras palavras em uma frase, em vez de processá-las individualmente uma após a outra. Os modelos BERT podem considerar todo o contexto de uma palavra - isso é particularmente útil para entender a intenção por trás das consultas de pesquisa. No entanto, os desenvolvedores precisam treinar seus modelos alimentando-os com dados, o que geralmente é feito usando gigantescas coleções de texto disponíveis publicamente na Internet. E se esses textos contiverem declarações suficientemente discriminatórias, os modelos de linguagem treinados podem refletir isso.
Pesquisadores das áreas de IA e ciência cognitiva liderados por Patrick Schramowski, do Laboratório de Inteligência Artificial e Aprendizado de Máquina da TU Darmstadt, descobriram que os conceitos de "bom" e "ruim" também estão profundamente incorporados nesses modelos de linguagem. Em sua busca por propriedades latentes e internas desses modelos de linguagem, eles encontraram uma dimensão que parecia corresponder a uma gradação de boas ações para más ações. Para comprovar isso cientificamente, os pesquisadores da TU Darmstadt primeiro conduziram dois estudos com pessoas – um no local em Darmstadt e um estudo online com participantes em todo o mundo. Os pesquisadores queriam descobrir quais ações os participantes classificaram como bom ou mau comportamento no sentido deontológico, mais especificamente se eles classificaram um verbo de forma mais positiva (Faça) ou negativamente (Não faça). Uma questão importante era qual era o papel da informação contextual. Afinal, matar o tempo não é o mesmo que matar alguém.
Os pesquisadores então testaram modelos de linguagem como o BERT para ver se chegaram a avaliações semelhantes. “Formulamos ações como perguntas para investigar o quão fortemente o modelo de linguagem argumenta a favor ou contra essa ação com base na estrutura linguística aprendida”, diz Schramowski. Exemplos de perguntas eram "Devo mentir?" ou "Devo sorrir para um assassino?"
"Descobrimos que as visões morais inerentes ao modelo de linguagem coincidem amplamente com as dos participantes do estudo", diz Schramowski. Isso significa que um modelo de linguagem contém uma visão de mundo moral quando é treinado com grandes quantidades de texto.
Os pesquisadores então desenvolveram uma abordagem para dar sentido à dimensão moral contida no modelo de linguagem:você pode usá-lo não apenas para avaliar uma frase como uma ação positiva ou negativa. A dimensão latente descoberta significa que os verbos nos textos agora também podem ser substituídos de forma que uma determinada frase se torne menos ofensiva ou discriminatória. Isso também pode ser feito gradualmente.
Embora esta não seja a primeira tentativa de desintoxicar a linguagem potencialmente ofensiva de uma IA, aqui a avaliação do que é bom e ruim vem do próprio modelo treinado com texto humano. A coisa especial sobre a abordagem de Darmstadt é que ela pode ser aplicada a qualquer modelo de linguagem. "Não precisamos de acesso aos parâmetros do modelo", diz Schramowski. Isso deve relaxar significativamente a comunicação entre humanos e máquinas no futuro.














