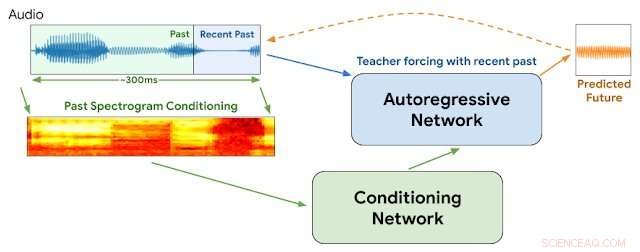
Arquitetura WaveNetEQ. Durante a inferência, nós "aquecemos" a rede autoregressiva forçando o professor com o áudio mais recente. Após, o modelo é fornecido com sua própria saída como entrada para a próxima etapa. Um espectrograma MEL de uma parte de áudio mais longa é usado como entrada para a rede de condicionamento. Crédito:Google
"É bom ouvir a sua voz, você sabe que faz tanto tempo
Se eu não receber suas ligações, então tudo dá errado ...
Sua voz através da linha me dá uma sensação estranha "
- loiro, "Pendurado no telefone"
Em 1978, Debbie Harry impulsionou sua banda new wave Blondie para o topo das paradas com uma lamentosa história de desejo de ouvir a voz de seu namorado de longe e insistindo para que ele não a deixasse "pendurada no telefone".
Mas surge a pergunta:e se fosse 2020 e ela estivesse falando por VOIP com perdas intermitentes de pacotes, jitter de áudio, atrasos na rede e transmissões de pacotes fora de seqüência?
Nunca saberemos.
Mas o Google anunciou esta semana os detalhes de uma nova tecnologia para seu popular aplicativo de voz e vídeo Duo que ajudará a garantir transmissões de voz mais suaves e reduzir as lacunas momentâneas que às vezes prejudicam as conexões baseadas na internet. Gostaríamos de pensar que Debbie aprovaria.
Todos nós já experimentamos jitter de áudio na Internet. Ocorre quando um ou mais pacotes de instruções compreendendo um fluxo de instruções de áudio são atrasados ou embaralhados fora de ordem entre o chamador e o ouvinte. Métodos que empregam buffers de pacote de voz e inteligência artificial geralmente podem suavizar o jitter de 20 milissegundos ou menos. Mas as interrupções se tornam mais perceptíveis quando os pacotes ausentes somam 60 milissegundos ou mais.
O Google diz que praticamente todas as chamadas sofrem alguma perda de pacote de dados:um quinto de todas as chamadas perdem 3% do áudio e um décimo perde 8%.
Esta semana, Os pesquisadores do Google na divisão DeepMind relataram que começaram a usar um programa chamado WaveNetEQ para resolver esses problemas. O algoritmo é excelente em preencher lacunas momentâneas de som com elementos de voz sintetizados, mas de som natural. Contando com uma biblioteca volumosa de dados de fala, WaveNetEQ preenche lacunas de som de até 120 milissegundos. Essas trocas de bits de som são chamadas de ocultação de perda de pacote (PLC).
"WaveNetEQ é um modelo generativo baseado na tecnologia WaveRNN da DeepMind, "AI Blog do Google relatou em 1º de abril, "que é treinado usando um grande corpus de dados de fala para continuar realisticamente segmentos de fala curtos, permitindo sintetizar totalmente a forma de onda bruta da fala perdida."
O programa analisou sons de 100 falantes em 48 idiomas, concentrando-se nas "características da fala humana em geral, em vez das propriedades de um idioma específico, "explica o relatório.
Além disso, a análise de som foi testada em ambientes que oferecem uma ampla variedade de ruídos de fundo para ajudar a garantir o reconhecimento preciso por alto-falantes em calçadas movimentadas da cidade, estações de trem ou lanchonetes.
Todo o processamento do WaveNetEQ deve ser executado no telefone do receptor para que os serviços de criptografia não sejam comprometidos. Mas a demanda extra na velocidade de processamento é mínima, Google afirma. WaveNetEQ é "rápido o suficiente para ser executado em um telefone, ao mesmo tempo em que oferece qualidade de áudio de última geração e PLC de som mais natural do que outros sistemas atualmente em uso. "
Amostras de sons que ilustram jitter de áudio e melhorias com WabeNetEQ são publicadas no relatório do Google Blog.
© 2020 Science X Network