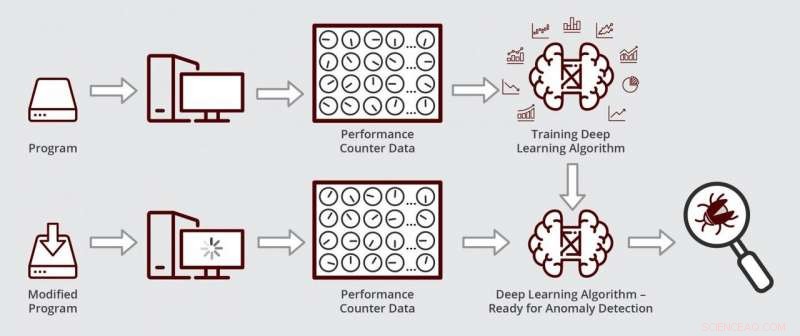
Esquema ilustrando como funciona o algoritmo de aprendizagem profunda de Muzahid. O algoritmo está pronto para detecção de anomalias depois de ser treinado pela primeira vez nos dados do contador de desempenho de uma versão livre de erros de um programa. Crédito:Texas A&M Engineering
Todos nós compartilhamos a frustração - as atualizações de software destinadas a fazer nossos aplicativos rodarem mais rápido inadvertidamente acabam fazendo exatamente o oposto. Esses bugs, apelidado no campo da ciência da computação como regressões de desempenho, consomem tempo para consertar, pois a localização de erros de software normalmente requer intervenção humana substancial.
Para superar esse obstáculo, pesquisadores da Texas A&M University, em colaboração com cientistas da computação da Intel Labs, agora desenvolveram uma forma totalmente automatizada de identificar a origem dos erros causados por atualizações de software. Seu algoritmo, com base em uma forma especializada de aprendizado de máquina chamada aprendizado profundo, não é só chave na mão, mas também rápido, encontrar bugs de desempenho em questão de algumas horas em vez de dias.
"A atualização de software às vezes pode ligar você quando os erros aparecem e causam lentidão. Esse problema é ainda mais exagerado para empresas que usam sistemas de software em grande escala que estão em constante evolução, "disse o Dr. Abdullah Muzahid, professor assistente do Departamento de Ciência da Computação e Engenharia. "Projetamos uma ferramenta conveniente para diagnosticar regressões de desempenho que é compatível com uma ampla gama de softwares e linguagens de programação, expandindo sua utilidade tremendamente. "
Os pesquisadores descreveram suas descobertas na 32ª edição do Advances in Neural Information Processing Systems dos anais da conferência Neural Information Processing Systems em dezembro.
Para identificar a origem dos erros no software, os depuradores geralmente verificam o status dos contadores de desempenho na unidade de processamento central. Esses contadores são linhas de código que monitoram como o programa está sendo executado no hardware do computador na memória, por exemplo. Então, quando o software é executado, contadores controlam o número de vezes que acessa certos locais de memória, o tempo que fica lá e quando sai, entre outras coisas. Portanto, quando o comportamento do software dá errado, os contadores são novamente usados para diagnósticos.
"Os contadores de desempenho dão uma ideia da integridade da execução do programa, "disse Muzahid." Então, se algum programa não estiver funcionando como deveria, esses contadores geralmente terão o sinal revelador de comportamento anômalo. "
Contudo, desktops e servidores mais recentes têm centenas de contadores de desempenho, tornando virtualmente impossível acompanhar todos os seus status manualmente e, em seguida, procurar padrões aberrantes que sejam indicativos de um erro de desempenho. É aí que entra o aprendizado de máquina de Muzahid.
Usando o aprendizado profundo, os pesquisadores foram capazes de monitorar dados provenientes de um grande número de contadores simultaneamente, reduzindo o tamanho dos dados, o que é semelhante a compactar uma imagem de alta resolução em uma fração de seu tamanho original, alterando seu formato. Nos dados dimensionais inferiores, seu algoritmo pode então procurar padrões que se desviem do normal.
Quando seu algoritmo estava pronto, os pesquisadores testaram se ele poderia encontrar e diagnosticar um bug de desempenho em um software de gerenciamento de dados disponível comercialmente usado por empresas para controlar seus números e números. Primeiro, eles treinaram seu algoritmo para reconhecer dados de contadores normais, executando um mais antigo, versão sem falhas do software de gerenciamento de dados. Próximo, eles executaram seu algoritmo em uma versão atualizada do software com a regressão de desempenho. Eles descobriram que seu algoritmo localizou e diagnosticou o bug em poucas horas. Muzahid disse que esse tipo de análise pode levar um tempo considerável se for feito manualmente.
Além de diagnosticar regressões de desempenho no software, Muzahid observou que seu algoritmo de aprendizagem profunda também tem usos potenciais em outras áreas de pesquisa, como o desenvolvimento da tecnologia necessária para uma direção autônoma.
"A ideia básica é mais uma vez a mesma, que é ser capaz de detectar um padrão anômalo, "disse Muzahid." Os carros que dirigem sozinhos devem ser capazes de detectar se um carro ou um humano está na frente deles e agir de acordo. Então, é novamente uma forma de detecção de anomalias e a boa notícia é que nosso algoritmo já foi projetado para fazer. "
Outros contribuintes da pesquisa incluem o Dr. Mejbah Alam, Dr. Justin Gottschlich, Dr. Nesime Tatbul, Dr. Javier Turek e Dr. Timothy Mattson da Intel Labs.