Crédito:Gupta et al.
O aprendizado por reforço (RL) é uma técnica de aprendizado de máquina amplamente usada que envolve o treinamento de agentes de IA ou robôs usando um sistema de recompensa e punição. Até aqui, pesquisadores no campo da robótica têm aplicado principalmente técnicas de RL em tarefas que são concluídas em períodos de tempo relativamente curtos, como mover-se para frente ou agarrar objetos.
Uma equipe de pesquisadores do Google e da Berkeley AI Research desenvolveu recentemente uma nova abordagem que combina RL com aprendizagem por imitação, um processo denominado aprendizado de política de retransmissão. Esta abordagem, apresentado em um artigo pré-publicado no arXiv e apresentado na Conferência sobre Aprendizado de Robôs (CoRL) 2019 em Osaka, pode ser usado para treinar agentes artificiais para lidar com tarefas de múltiplos estágios e de longo prazo, como tarefas de manipulação de objetos que se estendem por longos períodos de tempo.
"Nossa pesquisa se originou de muitos, principalmente malsucedido, experimentos com tarefas muito longas usando aprendizagem por reforço (RL), "Abhishek Gupta, um dos pesquisadores que realizou o estudo, disse TechXplore. "Hoje, RL em robótica é principalmente aplicado em tarefas que podem ser realizadas em um curto espaço de tempo, como agarrar, empurrando objetos, caminhando para frente, etc. Embora esses aplicativos tenham muito valor, nosso objetivo era aplicar a aprendizagem por reforço a tarefas que requerem múltiplos sub-objetivos e operam em escalas de tempo muito mais longas, como pôr uma mesa ou limpar uma cozinha. "
Antes de começarem a desenvolver sua abordagem, Gupta e seus colegas revisaram a literatura anterior para tentar determinar por que tarefas mais longas são particularmente difíceis de lidar com as técnicas atuais de RL. Em seu jornal, eles sugerem que geralmente há duas razões principais para isso.
Primeiro, é difícil para um robô identificar soluções ótimas para resolver tarefas longas e complexas por conta própria. Segundo, é difícil para o agente enfrentar com êxito uma tarefa longa, para a qual o feedback é fornecido apenas no final de uma longa sequência. Aprendizagem de políticas de retransmissão, a nova abordagem de aprendizagem que eles apresentaram, foi projetado para enfrentar esses dois desafios de frente.
Crédito:Gupta et al.
"Para enfrentar o desafio de fazer com que robôs resolvam tarefas de longo prazo por conta própria, decidimos simplificar o problema e usar demonstrações fornecidas por humanos, "Gupta disse." Resolver tarefas longas é difícil porque é extremamente difícil fazer um robô descobrir um comportamento interessante por conta própria - demonstrações fornecidas por humanos podem ser usadas como um guia para coisas interessantes a serem feitas em um ambiente. "
A abordagem para aprendizagem de robôs proposta por Gupta e seus colegas tem duas etapas distintas, um em que um agente aprende imitando humanos e outro com base em RL. No estágio de aprendizagem por imitação, um robô é alimentado com demonstrações humanas de como completar uma tarefa e produz políticas hierárquicas condicionadas a metas.
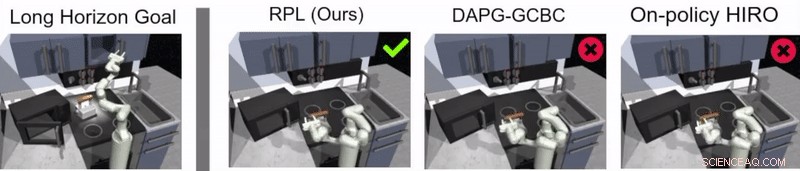
Em seu estudo, os pesquisadores usaram sua abordagem para treinar um agente artificial chamado Franka em tarefas de manipulação de múltiplos estágios e de longo prazo em um ambiente de cozinha simulado, que foi modelado usando a plataforma do simulador de física MuJoCo. Este ambiente consistia em uma cozinha com micro-ondas que pode ser aberto, quatro queimadores de forno, um interruptor de luz de forno, uma chaleira, dois armários com dobradiças e uma porta deslizante do armário.

Crédito:Gupta et al.
"Importante, aprender apenas com as demonstrações não é suficiente para resolver as tarefas desafiadoras em nosso ambiente de cozinha simulado, "Karol Hausman, outro pesquisador envolvido no estudo, disse TechXplore. "Para melhorar esta solução inicial, permitimos que os robôs pratiquem as tarefas por conta própria para refinar ainda mais seus comportamentos. "
Essencialmente, usando o método de aprendizagem de política de retransmissão proposto pelos pesquisadores, um agente aprende inicialmente por meio do processamento de demonstrações humanas de como concluir uma determinada tarefa e, em seguida, continua aprendendo por conta própria por meio de RL. Para facilitar o processo de aprendizagem de políticas de longo prazo, a equipe usou um novo algoritmo de reetiquetagem de dados que permite a um agente aprender políticas hierárquicas condicionadas a metas.
"Para enfrentar o desafio do feedback esparso, usamos uma estrutura hierárquica para nossas políticas de controle:a política de alto nível propõe objetivos que a política de baixo nível tenta realizar, por exemplo, feche um armário, desligue o queimador, etc, "Explicou Hausman." Por aqui, a tarefa pode ser facilmente decomposta em subproblemas menores que podem ser resolvidos com o aprendizado de reforço inicializado a partir de demonstrações fornecidas por humanos. "

Crédito:Gupta et al.
Guppta, Hausman e seus colegas avaliaram a eficácia do aprendizado de política de retransmissão para o treinamento de robôs em tarefas de longo prazo dentro do ambiente de cozinha simulado que eles criaram, alcançando resultados muito promissores. Eles descobriram que, com a estrutura de política certa e os dados de demonstração, sua abordagem permitiu que os robôs lidassem com tarefas de horizontes muito mais longos do que eles inicialmente pensaram ser possível.
"Esperamos que nossas descobertas possam abrir novos caminhos para combinar a pesquisa de aprendizagem de imitação e reforço e nos dar uma direção potencial que pode permitir que os robôs tenham um desempenho longo, tarefas complexas, "Disse Hausman.
No futuro, a abordagem de aprendizagem de política de retransmissão introduzida por Gupta, Hausman e seus colegas poderiam ser usados para treinar robôs em uma ampla gama de tarefas de longo prazo. Os pesquisadores até agora testaram sua técnica apenas em um ambiente simulado; portanto, seria interessante avaliá-lo em configurações do mundo real e ver se atinge resultados igualmente promissores.
"Como próximo passo, gostaríamos de examinar o problema da generalização além dos dados de demonstração, "Disse Hausman." Eventualmente, também gostaríamos de melhorar ainda mais a eficiência de dados de nosso método, mude para observações de pixels e possibilite o aprendizado no mundo real em um robô físico. "
© 2019 Science X Network