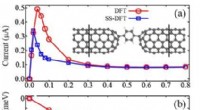
Usando um sistema de supercomputação, Os pesquisadores do MIT desenvolveram um modelo que captura a aparência do tráfego global da web em um determinado dia, incluindo links isolados anteriormente não vistos (à esquerda) que raramente se conectam, mas parecem impactar o tráfego da web principal (à direita). Crédito:MIT News
Usando um sistema de supercomputação, Os pesquisadores do MIT desenvolveram um modelo que captura a aparência do tráfego da web em todo o mundo em um determinado dia, que pode ser usado como uma ferramenta de medição para pesquisas na Internet e muitas outras aplicações.
Compreender os padrões de tráfego da web em grande escala, os pesquisadores dizem, é útil para informar a política de internet, identificando e evitando interrupções, defendendo-se contra ataques cibernéticos, e projetar uma infraestrutura de computação mais eficiente. Um artigo que descreve a abordagem foi apresentado na recente IEEE High Performance Extreme Computing Conference.
Por seu trabalho, os pesquisadores reuniram o maior conjunto de dados de tráfego da Internet disponível ao público, compreendendo 50 bilhões de pacotes de dados trocados em diferentes locais em todo o mundo ao longo de um período de vários anos.
Eles executaram os dados por meio de um novo pipeline de "rede neural" operando em 10, 000 processadores do MIT SuperCloud, um sistema que combina recursos de computação do MIT Lincoln Laboratory e de todo o Instituto. Esse pipeline treinou automaticamente um modelo que captura o relacionamento para todos os links no conjunto de dados - de pings comuns a gigantes como Google e Facebook, a links raros que se conectam apenas brevemente, mas parecem ter algum impacto no tráfego da web.
O modelo pode pegar qualquer conjunto de dados de rede massivo e gerar algumas medições estatísticas sobre como todas as conexões na rede afetam umas às outras. Isso pode ser usado para revelar insights sobre compartilhamento de arquivos ponto a ponto, endereços IP nefastos e comportamento de spam, a distribuição de ataques em setores críticos, e gargalos de tráfego para alocar melhor os recursos de computação e manter o fluxo de dados.
Em conceito, o trabalho é semelhante a medir a radiação cósmica de fundo do espaço, as ondas de rádio quase uniformes viajando ao redor de nosso universo e que têm sido uma importante fonte de informação para estudar fenômenos no espaço sideral. “Construímos um modelo preciso para medir o background do universo virtual da Internet, "diz Jeremy Kepner, pesquisador do MIT Lincoln Laboratory Supercomputing Center e astrônomo por formação. "Se você deseja detectar qualquer variação ou anomalia, você tem que ter um bom modelo de fundo. "
Juntando-se a Kepner no papel estão:Kenjiro Cho, da Internet Initiative Japan; KC Claffy, do Centro de Análise Aplicada de Dados da Internet da Universidade da Califórnia em San Diego; Vijay Gadepally e Peter Michaleas, do Centro de Supercomputação do Lincoln Laboratory; e Lauren Milechin, um pesquisador do Departamento da Terra do MIT, Ciências Atmosféricas e Planetárias.
Quebrando dados
Na pesquisa da internet, especialistas estudam anomalias no tráfego da web que podem indicar, por exemplo, ameaças cibernéticas. Para fazer isso, ajuda a entender primeiro como é o tráfego normal. Mas capturar isso continua sendo um desafio. Os modelos tradicionais de "análise de tráfego" podem analisar apenas pequenas amostras de pacotes de dados trocados entre origens e destinos limitados pela localização. Isso reduz a precisão do modelo.
Os pesquisadores não estavam procurando lidar especificamente com esse problema de análise de tráfego. Mas eles estavam desenvolvendo novas técnicas que poderiam ser usadas no MIT SuperCloud para processar matrizes de rede massivas. O tráfego da Internet foi o caso de teste perfeito.
As redes são geralmente estudadas na forma de gráficos, com atores representados por nós, e links que representam conexões entre os nós. Com o tráfego da Internet, os nós variam em tamanho e localização. Grandes supernós são hubs populares, como Google ou Facebook. Os nós folha se espalham a partir desse supernó e têm várias conexões entre si e com o supernó. Localizados fora desse "núcleo" de supernós e nós folha, estão nós e links isolados, que se conectam apenas raramente.
Capturar toda a extensão desses gráficos é inviável para modelos tradicionais. "Você não pode tocar nesses dados sem acesso a um supercomputador, "Kepner diz.
Em parceria com o projeto Widely Integrated Distributed Environment (WIDE), fundada por várias universidades japonesas, e o Center for Applied Internet Data Analysis (CAIDA), Em califórnia, os pesquisadores do MIT capturaram o maior conjunto de dados de captura de pacotes do mundo para o tráfego da Internet. O conjunto de dados anônimo contém quase 50 bilhões de pontos de dados de origem e destino exclusivos entre consumidores e vários aplicativos e serviços durante dias aleatórios em vários locais no Japão e nos EUA, datando de 2015.
Antes que eles pudessem treinar qualquer modelo nesses dados, eles precisavam fazer um pré-processamento extenso. Para fazer isso, eles utilizaram software que criaram anteriormente, chamado Modo de Dados Dimensionais Distribuídos Dinâmicos (D4M), que usa algumas técnicas de média para calcular e classificar com eficiência "dados hiperesparsos" que contêm muito mais espaço vazio do que pontos de dados. Os pesquisadores dividiram os dados em unidades de cerca de 100, 000 pacotes em 10, 000 processadores MIT SuperCloud. Isso gerou matrizes mais compactas de bilhões de linhas e colunas de interações entre origens e destinos.
Capturando outliers
Mas a grande maioria das células neste conjunto de dados hiperesparsos ainda estavam vazias. Para processar as matrizes, a equipe executou uma rede neural nas mesmas 10, 000 núcleos. Por trás das cenas, uma técnica de tentativa e erro começou a ajustar modelos para a totalidade dos dados, criando uma distribuição de probabilidade de modelos potencialmente precisos.
Então, ele usou uma técnica de correção de erros modificada para refinar ainda mais os parâmetros de cada modelo para capturar o máximo de dados possível. Tradicionalmente, técnicas de correção de erros em aprendizado de máquina tentarão reduzir a importância de quaisquer dados remotos, a fim de fazer o modelo se ajustar a uma distribuição de probabilidade normal, o que o torna mais preciso em geral. Mas os pesquisadores usaram alguns truques matemáticos para garantir que o modelo ainda visse todos os dados remotos - como links isolados - como significativos para as medições gerais.
No fim, a rede neural basicamente gera um modelo simples, com apenas dois parâmetros, que descreve o conjunto de dados de tráfego da Internet, "de nós realmente populares a nós isolados, e o espectro completo de tudo entre, "Kepner diz.
Os pesquisadores agora estão entrando em contato com a comunidade científica para encontrar sua próxima aplicação para o modelo. Especialistas, por exemplo, poderia examinar a importância dos links isolados que os pesquisadores encontraram em seus experimentos que são raros, mas parecem impactar o tráfego da web nos nós centrais.
Além da internet, o pipeline da rede neural pode ser usado para analisar qualquer rede hiperesparsa, como redes biológicas e sociais. "Agora oferecemos à comunidade científica uma ferramenta fantástica para pessoas que desejam construir redes mais robustas ou detectar anomalias de redes, "Kepner diz." Essas anomalias podem ser apenas comportamentos normais do que os usuários fazem, ou podem ser pessoas fazendo coisas que você não quer. "
Esta história foi republicada por cortesia do MIT News (web.mit.edu/newsoffice/), um site popular que cobre notícias sobre pesquisas do MIT, inovação e ensino.