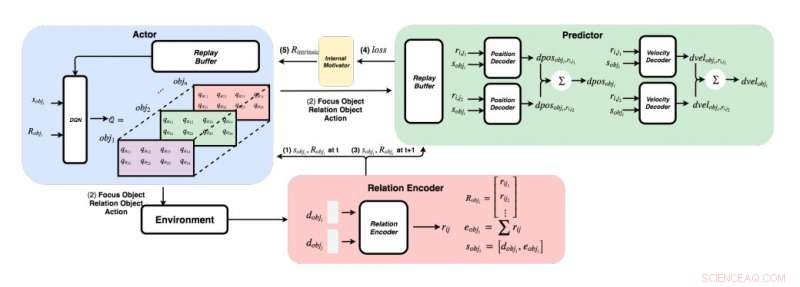
Um diagrama detalhado da abordagem desenvolvida pelos pesquisadores. (Embaixo à direita) Para cada par de objetos, os pesquisadores alimentam seus recursos em um codificador de relação para obter a relação rij e o estado sobji do objeto i. (Superior esquerdo) Usando o método ganancioso, para cada objeto, eles encontram o valor máximo de Q para obter nosso objeto de foco, objeto de relação, e ação. (Acima à direita) Depois de reunir seu objeto de foco e objeto de relação, eles alimentam seus estados e todas as suas relações com seus decodificadores para prever a mudança na posição e na velocidade. Crédito:Choi &Yoon.
Desde os primeiros anos de vida, os seres humanos têm a capacidade inata de aprender continuamente e construir modelos mentais do mundo, simplesmente observando e interagindo com coisas ou pessoas ao seu redor. Estudos de psicologia cognitiva sugerem que os humanos fazem uso extensivo desse conhecimento previamente adquirido, particularmente quando se deparam com novas situações ou ao tomar decisões.
Apesar dos avanços recentes significativos no campo da inteligência artificial (IA), a maioria dos agentes virtuais ainda requer centenas de horas de treinamento para atingir desempenho de nível humano em várias tarefas, enquanto os humanos podem aprender como completar essas tarefas em poucas horas ou menos. Estudos recentes destacaram dois contribuintes principais para a capacidade dos humanos de adquirir conhecimento tão rapidamente - a saber, física intuitiva e psicologia intuitiva.
Esses modelos de intuição, que foram observados em humanos desde os primeiros estágios de desenvolvimento, podem ser os principais facilitadores da aprendizagem futura. Com base nesta ideia, pesquisadores do Instituto Avançado de Ciência e Tecnologia da Coreia (KAIST) desenvolveram recentemente um método de normalização de recompensa intrínseca que permite aos agentes de IA selecionar ações que melhoram seus modelos de intuição. Em seu jornal, pré-publicado no arXiv, os pesquisadores propuseram especificamente uma rede de física gráfica integrada com aprendizagem por reforço profundo inspirada no comportamento de aprendizagem observado em bebês humanos.
"Imagine bebês humanos em uma sala com brinquedos espalhados a uma distância acessível, "os pesquisadores explicam em seu artigo." Eles estão constantemente agarrando, arremessar e realizar ações em objetos; as vezes, eles observam o resultado de suas ações, mas às vezes, eles perdem o interesse e passam para um objeto diferente. A visão da 'criança como um cientista' sugere que bebês humanos são intrinsecamente motivados para conduzir seus próprios experimentos, descubra mais informações, e eventualmente aprender a distinguir objetos diferentes e criar representações internas mais ricas deles. "
Estudos de psicologia sugerem que nos primeiros anos de vida, os humanos estão continuamente experimentando com seus arredores, e isso permite que eles formem uma compreensão-chave do mundo. Além disso, quando as crianças observam resultados que não atendem às suas expectativas anteriores, que é conhecido como violação de expectativa, muitas vezes, eles são incentivados a fazer mais experiências para compreender melhor a situação em que se encontram.
A equipe de pesquisadores do KAIST tentou reproduzir esses comportamentos em agentes de IA usando uma abordagem de aprendizado por reforço. Em seu estudo, eles primeiro introduziram uma rede de física gráfica que pode extrair relacionamentos físicos entre objetos e prever seus comportamentos subsequentes em um ambiente 3-D. Subseqüentemente, eles integraram esta rede com um modelo de aprendizagem de reforço profundo, introduzindo uma técnica de normalização de recompensa intrínseca que incentiva um agente de IA a explorar e identificar ações que irão melhorar continuamente seu modelo de intuição.
Usando um motor de física 3-D, os pesquisadores demonstraram que sua rede de física gráfica pode inferir com eficiência as posições e velocidades de diferentes objetos. Eles também descobriram que sua abordagem permitiu que a rede de aprendizagem por reforço profundo melhorasse continuamente seu modelo de intuição, encorajando-o a interagir com objetos apenas com base na motivação intrínseca.
Em uma série de avaliações, a nova técnica desenvolvida por esta equipe de pesquisadores alcançou notável precisão, com o agente AI realizando um número maior de ações exploratórias diferentes. No futuro, pode informar o desenvolvimento de ferramentas de aprendizado de máquina que podem aprender com suas experiências anteriores de forma mais rápida e eficaz.
"Testamos nossa rede em problemas estacionários e não estacionários em várias cenas com objetos esféricos com massas e raios variados, "Os pesquisadores explicam em seu artigo." Nossa esperança é que esses modelos de intuição pré-treinados sejam posteriormente usados como um conhecimento prévio para outras tarefas orientadas a objetivos, como jogos ATARI ou previsão de vídeo. "
© 2019 Science X Network