Os pesquisadores do Berkeley Lab descobriram que a mineração de texto de resumos da ciência de materiais poderia revelar novos materiais termoelétricos. Crédito:Berkeley Lab
Certo, computadores podem ser usados para jogar xadrez em nível de grande mestre (chess_computer), mas eles podem fazer descobertas científicas? Pesquisadores do Laboratório Nacional Lawrence Berkeley do Departamento de Energia dos EUA (Berkeley Lab) mostraram que um algoritmo sem treinamento em ciência dos materiais pode digitalizar o texto de milhões de artigos e descobrir novos conhecimentos científicos.
Uma equipe liderada por Anubhav Jain, um cientista da Divisão de Armazenamento de Energia e Recursos Distribuídos do Berkeley Lab, coletou 3,3 milhões de resumos de artigos científicos de materiais publicados e os alimentou em um algoritmo chamado Word2vec. Ao analisar as relações entre as palavras, o algoritmo foi capaz de prever descobertas de novos materiais termoelétricos com anos de antecedência e sugerir materiais ainda desconhecidos como candidatos a materiais termoelétricos.
"Sem contar nada sobre ciência de materiais, aprendeu conceitos como a tabela periódica e a estrutura cristalina dos metais, "disse Jain." Isso indicava o potencial da técnica. Mas provavelmente a coisa mais interessante que descobrimos é, você pode usar este algoritmo para resolver lacunas na pesquisa de materiais, coisas que as pessoas deveriam estudar, mas não estudaram até agora. "
As descobertas foram publicadas em 3 de julho na revista Natureza . O principal autor do estudo, "Unsupervised Word Embeddings Capture Latent Knowledge from Materials Science Literature, "é Vahe Tshitoyan, um pós-doutorado do Berkeley Lab agora trabalhando no Google. Junto com Jain, Os cientistas do Berkeley Lab, Kristin Persson e Gerbrand Ceder, ajudaram a conduzir o estudo.
"O artigo estabelece que a mineração de texto da literatura científica pode revelar conhecimento oculto, e que a extração baseada em texto puro pode estabelecer o conhecimento científico básico, "disse Ceder, que também tem um cargo no Departamento de Ciência e Engenharia de Materiais da UC Berkeley.
Tshitoyan disse que o projeto foi motivado pela dificuldade de dar sentido à grande quantidade de estudos publicados. "Em cada campo de pesquisa, há 100 anos de literatura de pesquisa anterior, e todas as semanas saem dezenas de estudos, "ele disse." Um pesquisador pode acessar apenas uma fração disso. Nós pensamos, O aprendizado de máquina pode fazer algo para usar todo esse conhecimento coletivo de uma maneira não supervisionada - sem precisar da orientação de pesquisadores humanos? "
'Rei - rainha + homem =?'
A equipe coletou 3,3 milhões de resumos de artigos publicados em mais de 1, 000 periódicos entre 1922 e 2018. Word2vec levou cada um dos cerca de 500, 000 palavras distintas nesses resumos e transformaram cada uma em um vetor de 200 dimensões, ou uma matriz de 200 números.
"O que é importante não é cada número, mas usando os números para ver como as palavras estão relacionadas entre si, "disse Jain, que lidera um grupo que trabalha na descoberta e design de novos materiais para aplicações de energia usando uma mistura de teoria, computação, e mineração de dados. "Por exemplo, você pode subtrair vetores usando matemática vetorial padrão. Outros pesquisadores mostraram que se você treinar o algoritmo em fontes de texto não científicas e pegar o vetor que resulta de 'rei menos rainha, 'você obtém o mesmo resultado que' homem sem mulher '. Ele descobre o relacionamento sem que você diga nada. "
De forma similar, quando treinado em texto de ciência de materiais, o algoritmo foi capaz de aprender o significado de termos científicos e conceitos, como a estrutura cristalina dos metais, com base simplesmente nas posições das palavras nos resumos e sua coocorrência com outras palavras. Por exemplo, assim como poderia resolver a equação "rei - rainha + homem, "ele poderia descobrir que, para a equação" ferromagnético - NiFe + IrMn ", a resposta seria" antiferromagnético ".
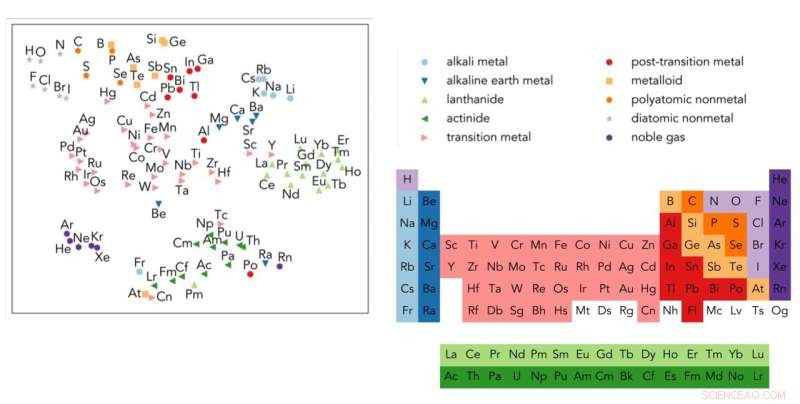
A tabela periódica de Mendeleev está à direita. Representação dos elementos do Word2vec, projetado em duas dimensões, Está à esquerda. Crédito:Berkeley Lab
O Word2vec foi capaz até de aprender as relações entre os elementos da tabela periódica quando o vetor de cada elemento químico foi projetado em duas dimensões.
Prevendo descobertas com anos de antecedência
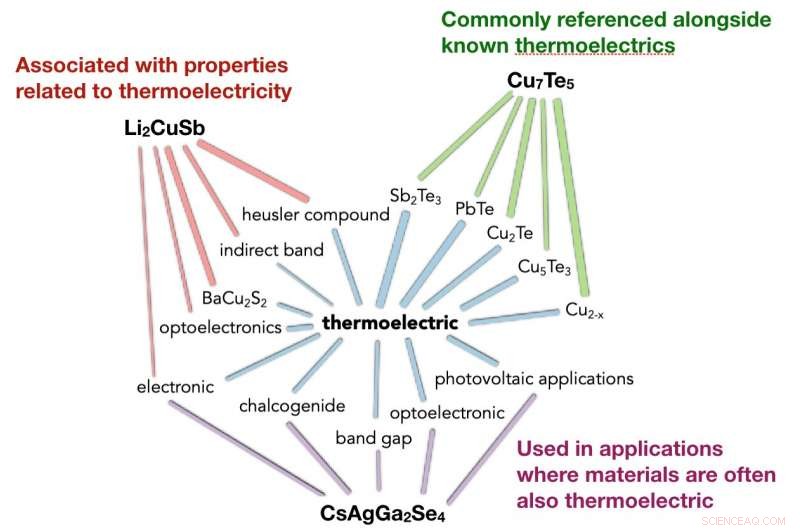
Então, se o Word2vec é tão inteligente, poderia prever novos materiais termoelétricos? Um bom material termoelétrico pode converter calor em eletricidade de forma eficiente e é feito de materiais seguros, abundante e fácil de produzir.
A equipe do Berkeley Lab escolheu os principais candidatos termelétricos sugeridos pelo algoritmo, que classificou cada composto pela semelhança de seu vetor de palavras com o da palavra "termoelétrica". Em seguida, eles executaram cálculos para verificar as previsões do algoritmo.
Das 10 principais previsões, eles descobriram que todos tinham fatores de potência computados ligeiramente superiores à média das termelétricas conhecidas; os três primeiros candidatos tinham fatores de potência acima do percentil 95 das termelétricas conhecidas.
Em seguida, eles testaram se o algoritmo poderia realizar experimentos "no passado", fornecendo resumos apenas até, dizer, o ano de 2000. Novamente, das principais previsões, um número significativo apareceu em estudos posteriores - quatro vezes mais do que se os materiais tivessem sido escolhidos aleatoriamente. Por exemplo, três das cinco principais previsões treinadas usando dados até o ano de 2008 já foram descobertas e as duas restantes contêm elementos raros ou tóxicos.
Os resultados foram surpreendentes. "Sinceramente, não esperava que o algoritmo previsse tanto resultados futuros, "Jain disse." Eu pensei que talvez o algoritmo pudesse descrever o que as pessoas fizeram antes, mas não chegar a essas diferentes conexões. Fiquei muito surpreso quando vi não apenas as previsões, mas também o raciocínio por trás das previsões, coisas como a estrutura de meio-Heusler, que é uma estrutura de cristal muito quente para termoelétricas nos dias de hoje. "
Ele acrescentou:"Este estudo mostra que se este algoritmo existisse anteriormente, alguns materiais poderiam ter sido descobertos com anos de antecedência. "Junto com o estudo, os pesquisadores estão lançando os 50 principais materiais termoelétricos previstos pelo algoritmo. Eles também lançarão a palavra embeddings necessários para que as pessoas façam seus próprios aplicativos, se quiserem para pesquisar, dizer, um melhor material isolante topológico.
A seguir, Jain disse que a equipe está trabalhando em um sistema mais inteligente, mecanismo de pesquisa mais poderoso, permitindo que os pesquisadores pesquisem resumos de uma forma mais útil.
O estudo foi financiado pelo Toyota Research Institute. Outros co-autores do estudo são os pesquisadores do Berkeley Lab, John Dagdelen, Leigh Weston, Alexander Dunn, e Ziqin Rong, e a pesquisadora da UC Berkeley, Olga Kononova.














