Por anos, pesquisadores do MIT e da Brown University têm desenvolvido um sistema interativo que permite aos usuários arrastar e soltar e manipular dados em qualquer tela sensível ao toque, incluindo smartphones e quadros interativos. Agora, eles incluíram uma ferramenta que gera instantaneamente e automaticamente modelos de aprendizado de máquina para executar tarefas de predição nesses dados. Crédito:Melanie Gonick
No Homem de Ferro filmes, Tony Stark usa um computador holográfico para projetar dados 3D no ar, manipule-os com as mãos, e encontrar soluções para seus problemas de super-heróis. Na mesma veia, pesquisadores do MIT e da Brown University desenvolveram agora um sistema de análise de dados interativa que roda em telas sensíveis ao toque e permite que todos - não apenas gênios, bilionário, filantropos playboy - lidem com questões do mundo real.
Por anos, os pesquisadores têm desenvolvido um sistema interativo de ciência de dados chamado Northstar, que roda na nuvem, mas tem uma interface compatível com qualquer dispositivo touchscreen, incluindo smartphones e grandes quadros brancos interativos. Os usuários alimentam os conjuntos de dados do sistema, e manipular, combinar, e extrair recursos em uma interface amigável, usando os dedos ou uma caneta digital, para descobrir tendências e padrões.
Em um artigo apresentado na conferência ACM SIGMOD, os pesquisadores detalham um novo componente do Northstar, chamado VDS para "cientista de dados virtual, "que gera instantaneamente modelos de aprendizado de máquina para executar tarefas de predição em seus conjuntos de dados. Médicos, por exemplo, pode usar o sistema para ajudar a prever quais pacientes são mais propensos a ter certas doenças, enquanto os proprietários de empresas podem querer fazer previsões de vendas. Se estiver usando um quadro interativo, todos também podem colaborar em tempo real.
O objetivo é democratizar a ciência de dados, tornando mais fácil fazer análises complexas, com rapidez e precisão.
"Mesmo o dono de uma cafeteria que não conhece ciência de dados deve ser capaz de prever suas vendas nas próximas semanas para descobrir quanto café comprar, "diz o co-autor e líder do projeto Northstar de longa data Tim Kraska, professor associado de engenharia elétrica e ciência da computação no Laboratório de Ciência da Computação e Inteligência Artificial do MIT (CSAIL) e co-diretor fundador do novo Data System and AI Lab (DSAIL). "Em empresas que têm cientistas de dados, há muitas idas e vindas entre cientistas de dados e não especialistas, para que também possamos colocá-los em uma sala para fazer análises juntos. "
O VDS é baseado em uma técnica cada vez mais popular em inteligência artificial chamada aprendizado de máquina automatizado (AutoML), que permite que pessoas com conhecimento limitado de ciência de dados treinem modelos de IA para fazer previsões com base em seus conjuntos de dados. Atualmente, a ferramenta lidera a competição DARPA D3M Automatic Machine Learning, que a cada seis meses decide sobre a ferramenta AutoML de melhor desempenho.
Juntando-se a Kraska no papel estão:primeiro autor Zeyuan Shang, um estudante de graduação, e Emanuel Zgraggen, um pós-doutorado e principal contribuidor da Northstar, ambos da EECS, CSAIL, e DSAIL; Benedetto Buratti, Yeounoh Chung, Philipp Eichmann, e Eli Upfal, tudo em Brown; e Carsten Binnig, que recentemente se mudou de Brown para a Universidade Técnica de Darmstadt, na Alemanha.

Crédito:Melanie Gonick
Uma "tela ilimitada" para análises
O novo trabalho se baseia em anos de colaboração na Northstar entre pesquisadores do MIT e Brown. Mais de quatro anos, os pesquisadores publicaram vários artigos detalhando os componentes do Northstar, incluindo a interface interativa, operações em várias plataformas, resultados acelerados, e estudos sobre o comportamento do usuário.
Northstar começa em branco, interface branca. Os usuários carregam conjuntos de dados no sistema, que aparecem em uma caixa de "conjuntos de dados" à esquerda. Quaisquer rótulos de dados preencherão automaticamente uma caixa de "atributos" separada abaixo. Há também uma caixa de "operadores" que contém vários algoritmos, bem como a nova ferramenta AutoML. Todos os dados são armazenados e analisados na nuvem.
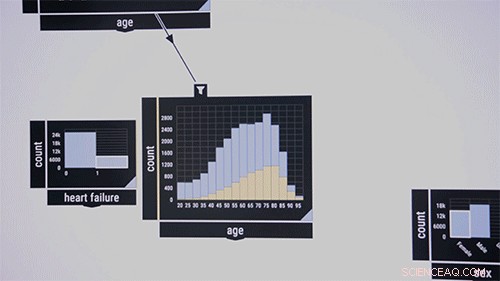
Os pesquisadores gostam de demonstrar o sistema em um conjunto de dados público que contém informações sobre pacientes em unidades de terapia intensiva. Considere os pesquisadores médicos que desejam examinar as co-ocorrências de certas doenças em certas faixas etárias. Eles arrastam e soltam no meio da interface um algoritmo de verificação de padrões, que à primeira vista aparece como uma caixa em branco. Como entrada, eles se movem para os recursos de doença da caixa rotulados, dizer, "sangue, " "infeccioso, "e" metabólica ". As porcentagens dessas doenças no conjunto de dados aparecem na caixa. Em seguida, eles arrastam o recurso "idade" para a interface, que exibe um gráfico de barras da distribuição da idade do paciente. Desenhar uma linha entre as duas caixas liga-as. Circulando as faixas etárias, o algoritmo calcula imediatamente a coocorrência das três doenças na faixa etária.
"É como um grande, tela ilimitada onde você pode definir como deseja tudo, "diz Zgraggen, quem é o principal inventor da interface interativa do Northstar. "Então, você pode vincular coisas para criar questões mais complexas sobre seus dados. "
Aproximando AutoML
Com VDS, os usuários agora também podem executar análises preditivas nesses dados, obtendo modelos personalizados para suas tarefas, como previsão de dados, classificação de imagem, ou analisar estruturas de gráfico complexas.
Usando o exemplo acima, dizem que os pesquisadores médicos desejam prever quais pacientes podem ter doenças no sangue com base em todos os recursos do conjunto de dados. Eles arrastam e soltam "AutoML" da lista de algoritmos. Primeiro produzirá uma caixa em branco, mas com uma guia "alvo", sob o qual eles colocariam o recurso "sangue". O sistema encontrará automaticamente os pipelines de aprendizado de máquina de melhor desempenho, apresentados como guias com porcentagens de precisão constantemente atualizadas. Os usuários podem interromper o processo a qualquer momento, refine a pesquisa, e examinar as taxas de erros de cada modelo, estrutura, cálculos, e outras coisas.
Crédito:Melanie Gonick
De acordo com os pesquisadores, VDS é a ferramenta AutoML interativa mais rápida até hoje, obrigado, em parte, para seu "mecanismo de estimativa" personalizado. O mecanismo fica entre a interface e o armazenamento em nuvem. O mecanismo cria automaticamente várias amostras representativas de um conjunto de dados que podem ser processadas progressivamente para produzir resultados de alta qualidade em segundos.
"Junto com meus co-autores, passei dois anos projetando VDS para imitar como um cientista de dados pensa, "Shang diz, o que significa que identifica instantaneamente quais modelos e etapas de pré-processamento devem ou não ser executados em certas tarefas, com base em várias regras codificadas. Ele primeiro escolhe em uma grande lista desses possíveis pipelines de aprendizado de máquina e executa simulações no conjunto de amostra. Ao fazer isso, ele lembra os resultados e refina sua seleção. Depois de entregar resultados aproximados rapidamente, o sistema refina os resultados no back end. Mas os números finais geralmente estão muito próximos da primeira aproximação.
"Para usar um preditor, você não quer esperar quatro horas para obter os primeiros resultados de volta. Você já quer ver o que está acontecendo e, se você detectar um erro, você pode corrigi-lo imediatamente. Isso normalmente não é possível em qualquer outro sistema, "Kraska diz. O estudo anterior dos pesquisadores com usuários, na verdade, "mostram que, no momento em que você atrasa o fornecimento de resultados aos usuários, eles começam a perder o engajamento com o sistema. "
Os pesquisadores avaliaram a ferramenta em 300 conjuntos de dados do mundo real. Em comparação com outros sistemas AutoML de última geração, As aproximações do VDS foram tão precisas, mas foram gerados em segundos, que é muito mais rápido do que outras ferramentas, que operam em minutos a horas.
Próximo, os pesquisadores estão procurando adicionar um recurso que alerte os usuários sobre possíveis distorções ou erros de dados. Por exemplo, para proteger a privacidade do paciente, sometimes researchers will label medical datasets with patients aged 0 (if they do not know the age) and 200 (if a patient is over 95 years old). But novices may not recognize such errors, which could completely throw off their analytics.
"If you're a new user, you may get results and think they're great, " Kraska says. "But we can warn people that there, na verdade, may be some outliers in the dataset that may indicate a problem."
Esta história foi republicada por cortesia do MIT News (web.mit.edu/newsoffice/), um site popular que cobre notícias sobre pesquisas do MIT, inovação e ensino.