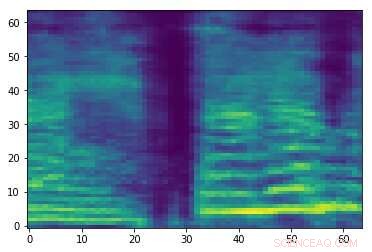
Espectrograma de um sinal de áudio aleatório. Crédito:Esmailpour, Cardinal e Lemeiras Koerich.
Ataques adversários de áudio são pequenas perturbações que não são perceptíveis por humanos e são intencionalmente adicionadas aos sinais de áudio para prejudicar o desempenho dos modelos de aprendizado de máquina (ML). Esses ataques levantam sérias preocupações sobre a segurança dos modelos de ML, pois podem fazer com que cometam erros e, em última análise, gerem previsões erradas.
Pesquisadores da École de Technologie Supérieure, parte da Universidade de Quebec, no Canadá, desenvolveu recentemente uma nova abordagem que pode ajudar a proteger as ferramentas de classificação de áudio contra ataques adversários. Em seu jornal, pré-publicado no arXiv, eles analisam alguns dos ataques adversários mais fortes existentes e seu impacto no desempenho de modelos comuns de ML, em seguida, proponha uma abordagem que possa neutralizar esses ataques.
"No momento, existem muitos classificadores fortes e rápidos (em tempo de execução) em termos de precisão, a saber, classificadores de aprendizagem profunda (por exemplo, redes neurais convolucionais), que pode até superar o nível humano da mídia (por exemplo, fala, imagem, vídeo, animação, texto, etc.) reconhecimento e regressão, "Mohammad Esmaeilpour, um dos pesquisadores que realizou o estudo, disse TechXplore. "O calcanhar de Aquiles desses algoritmos avançados é sua vulnerabilidade a entradas que contêm perturbações cuidadosamente elaboradas, conhecidos como ataques adversários. "
Ataques adversários funcionam produzindo amostras que se assemelham a amostras de treinamento legítimas, mas isso na verdade leva um modelo ou modelos de ML a gerar rótulos errados com altos níveis de confiança. Na pesquisa de ML, se houver dados suficientes para treinar um classificador, o principal desafio não é mais melhorar a precisão do reconhecimento, mas garantindo sua resiliência contra ataques adversários.
"Ataques adversários são ameaças ativas para todos os algoritmos baseados em dados, mesmo aqueles treinados em pequenos conjuntos de dados, "Esmaeilpour disse." Isso despertou nosso interesse em estudar a ameaça de ataques adversários para aplicativos de reconhecimento de áudio e voz, uma vez que todos os smartphones agora estão equipados com um assistente de fala virtual, como Siri, Assistente do Google e Cortana. "
Em seu estudo, Esmaeilpour e seus colegas realizaram experimentos envolvendo conjuntos de dados de áudio ambientais, em vez de conjuntos de dados de fala. Apesar disso, no futuro, sua abordagem também pode ser potencialmente estendida ao reconhecimento de voz, o que ajudaria a proteger os assistentes de voz contra ataques adversários.
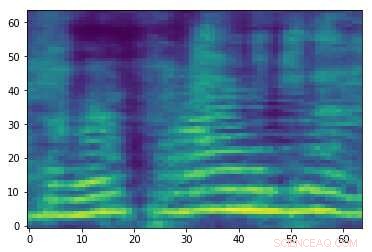
Espectrograma adversarial elaborado associado ao sinal de áudio na primeira imagem. Embora as duas imagens sejam semelhantes, eles têm rótulos diferentes, sugerindo que um ataque está ocorrendo. Crédito:Esmailpour, Cardinal e Lemeiras Koerich.
"Nosso principal objetivo neste artigo foi estudar a ameaça de ataques adversários para classificadores de áudio de aprendizado profundo e convencionais e, idealmente, propor um algoritmo mais confiável em termos de resiliência contra alguns ataques comuns como base para uma classificação de áudio robusta real, "Esmaeilpour explicou." Queríamos fazer um equilíbrio justo para os classificadores na precisão do reconhecimento, complexidade computacional, e robustez contra ataques adversários. "
Geralmente, classificadores que são mais robustos contra ataques adversários obtêm menor precisão de reconhecimento, e vice versa. Em seu estudo, os pesquisadores se concentraram na reciclagem do adversário, uma das técnicas de defesa existentes mais válidas que não ofusca as informações do gradiente. Apesar de seus benefícios, esta estratégia de defesa em particular é cara (como ataques fortes são caros, o retreinamento adversarial usando esses ataques será mais caro) e pode afetar negativamente o desempenho de reconhecimento de um classificador.
"O caso ideal para nós seria propor um classificador de áudio livre de ofuscação gradiente e livre de retreinamento adversário que inerentemente aprende 'recursos robustos', "Esmaeilpour disse." Nosso cenário de classificação inclui várias etapas, principalmente aprimoramento de espectrograma (representação 2D para sinais de áudio), redução de dimensionalidade usando uma técnica de decomposição algébrica, e suavização, utilizando um autoencoder de ruídos convolucional, onde as duas últimas etapas (empilhadas juntas) mostraram impactos positivos na remoção de pequenas perturbações adversas em potencial desconhecidas. "
Depois de analisar alguns dos ataques adversários mais fortes por aí e seus efeitos no desempenho dos modelos de ML, os pesquisadores extraíram características dos espectrogramas processados pelos modelos, organizou-os em um livro de código e treinou um algoritmo de máquina de vetor de suporte (SVM) neste livro de código. Em seu pipeline de treinamento, eles não implementaram nenhuma técnica pró-ativa ou reativa de detecção de ataques adversários ou algoritmos de defesa.
"Nosso objetivo principal era 'aprender vetores de recursos robustos' sem qualquer sobrecarga de pré ou pós-processamento para detectar amostras adversas em potencial, "Esmaeilpour explicou." Nossos resultados mostram que nosso classificador proposto supera o aprendizado profundo de última geração e algoritmos convencionais contra cinco tipos de ataques adversários fortes para alguns conjuntos de dados de áudio ambientais práticos. "
Esmaeilpour e seus colegas provaram estatisticamente a vulnerabilidade dos classificadores convencionais (ou seja, classificadores que aprendem com o espaço de recursos) e algoritmos de aprendizado profundo (ou seja, algoritmos que aprendem com dados brutos) contra ataques adversários. De acordo com os pesquisadores, atualmente não há algoritmo orientado a dados confiável para classificação de áudio que também seja robusto contra ataques adversários. Entre os modelos existentes, abordagens baseadas em aprendizagem profunda parecem ser as menos seguras contra esses ataques, mesmo que eles normalmente atinjam a maior precisão de reconhecimento.
"O cenário de classificação que propomos em nosso artigo usa um SVM com kernel polinomial como um classificador final, "Esmaeilpour disse." No entanto, aplicar um autoencoder de ruídos convolucional no topo da decomposição de valor singular seguido por um agrupamento não supervisionado de vetores de recursos robustos acelerados extraídos pode ajudar a aprender mais componentes estruturais e provavelmente recursos robustos, o que poderia nos permitir atingir um equilíbrio razoável entre a precisão do reconhecimento (comparável ao desempenho de última geração) e a robustez contra cinco fortes ataques adversários comuns. "
Embora os resultados coletados pelos pesquisadores sejam muito promissores, eles podem variar de acordo com o conjunto de dados usado ou a aplicação específica de um classificador, portanto, eles ainda não são generalizáveis. No futuro, seu estudo pode informar o desenvolvimento de outros classificadores que estão mais bem equipados contra ataques adversários, sem apresentar perdas substanciais no desempenho (ou seja, precisão de reconhecimento).
"Aprender recursos robustos é um problema em aberto e ainda não temos uma ideia clara de como abordá-lo adequadamente; está sendo estudado por nossa equipe de pesquisa e alguns resultados serão lançados em breve, "Esmaeilpour disse." Enquanto isso, estamos trabalhando em um novo, técnica de ataque adversário forte e rápida que visa utilizar este ataque para treinar adversamente o modelo de aprendizagem (o que melhora sua robustez) e também salvar o desempenho de reconhecimento do modelo antes de treiná-lo. "
© 2019 Science X Network