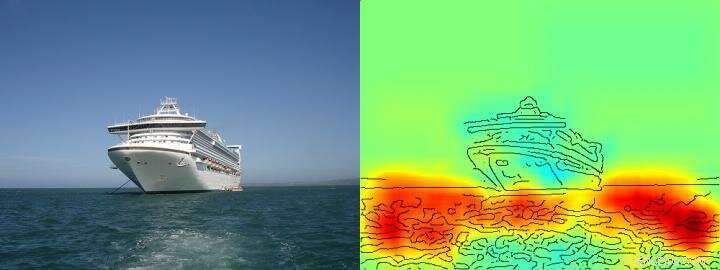
O mapa de calor mostra claramente que o algoritmo toma sua decisão de enviar / não enviar com base nos pixels que representam a água e não com base nos pixels que representam a nave. Crédito: Nature Communications , CC BY Lizenz
Inteligência artificial (IA) e arquiteturas de aprendizado de máquina, como aprendizado profundo, tornaram-se partes integrantes de nossas vidas diárias - elas permitem assistentes de fala digital ou serviços de tradução, melhoram os diagnósticos médicos e são uma parte indispensável das tecnologias futuras, como a direção autônoma. Com base em uma quantidade cada vez maior de dados e novas arquiteturas de computador poderosas, algoritmos de aprendizagem aparentemente se aproximam das capacidades humanas, às vezes até superando-os. Até aqui, Contudo, frequentemente permanece desconhecido para os usuários como exatamente os sistemas de IA chegam às suas conclusões. Portanto, muitas vezes pode não ficar claro se o comportamento de tomada de decisão da IA é realmente inteligente ou se os procedimentos são apenas medianamente bem-sucedidos.
Pesquisadores da TU Berlin, O Fraunhofer Heinrich Hertz Institute HHI e a Singapore University of Technology and Design (SUTD) abordaram essa questão e forneceram um vislumbre do diversificado espectro de "inteligência" observado nos sistemas de IA atuais, analisar especificamente esses sistemas de IA com uma nova tecnologia que permite análise e quantificação automatizadas.
O pré-requisito mais importante para esta nova tecnologia é um método desenvolvido anteriormente pela TU Berlin e Fraunhofer HHI, o algoritmo denominado Layer-wise Relevance Propagation (LRP), que permite visualizar de acordo com quais variáveis de entrada os sistemas AI tomam suas decisões. Estendendo LRP, a nova análise de relevância espectral (SpRAy) pode identificar e quantificar um amplo espectro de comportamentos de tomada de decisão aprendidos. Desta forma, agora se tornou possível detectar tomadas de decisão indesejáveis, mesmo em conjuntos de dados muito grandes.
Esta chamada 'IA explicável' tem sido uma das etapas mais importantes para uma aplicação prática da IA, de acordo com o Dr. Klaus-Robert Müller, professor de aprendizado de máquina na TU Berlin. "Especificamente em diagnósticos médicos ou em sistemas críticos para a segurança, nenhum sistema de IA que empregue estratégias de resolução de problemas instáveis ou mesmo trapaceiras deve ser usado. "
Usando seus algoritmos recém-desenvolvidos, os pesquisadores são finalmente capazes de testar qualquer sistema de IA existente e também derivar informações quantitativas sobre eles:todo um espectro a partir de um comportamento ingênuo de resolução de problemas, para enganar estratégias até soluções estratégicas "inteligentes" altamente elaboradas é observado.
Dr. Wojciech Samek, O líder do grupo Fraunhofer HHI disse:"Ficamos muito surpresos com a ampla gama de estratégias de resolução de problemas aprendidas. Mesmo os sistemas modernos de IA nem sempre encontraram uma solução que pareça significativa do ponto de vista humano, mas às vezes usava as chamadas Estratégias de Hans Clever. "
Clever Hans era um cavalo que supostamente sabia contar e foi considerado uma sensação científica durante os anos 1900. Como foi descoberto mais tarde, Hans não dominava matemática, mas em cerca de 90 por cento dos casos, ele foi capaz de derivar a resposta correta da reação do questionador.
A equipe em torno de Klaus-Robert Müller e Wojciech Samek também descobriu estratégias semelhantes de "Hans Inteligente" em vários sistemas de IA. Por exemplo, um sistema de IA que ganhou vários concursos internacionais de classificação de imagens há alguns anos perseguiu uma estratégia que pode ser considerada ingênua do ponto de vista humano. Classificou as imagens principalmente com base no contexto. As imagens foram atribuídas à categoria "navio" quando havia muita água na foto. Outras imagens foram classificadas como "trem" se trilhos estivessem presentes. Ainda outras fotos foram atribuídas à categoria correta por sua marca d'água de direitos autorais. A verdadeira tarefa, nomeadamente para detectar os conceitos de navios ou comboios, não foi, portanto, resolvido por este sistema de IA - mesmo que tenha classificado a maioria das imagens corretamente.
Os pesquisadores também foram capazes de encontrar esses tipos de estratégias de resolução de problemas defeituosos em alguns dos algoritmos de IA de última geração, as chamadas redes neurais profundas - algoritmos considerados imunes a tais lapsos. Essas redes basearam suas decisões de classificação em parte em artefatos que foram criados durante a preparação das imagens e nada têm a ver com o conteúdo real da imagem.
"Esses sistemas de IA não são úteis na prática. Seu uso em diagnósticos médicos ou em áreas críticas para a segurança envolveria até enormes perigos, "disse Klaus-Robert Müller." É bastante concebível que cerca de metade dos sistemas de IA atualmente em uso implícita ou explicitamente dependem dessas estratégias do Clever Hans. É hora de verificar sistematicamente isso para que sistemas de IA seguros possam ser desenvolvidos. "
Com sua nova tecnologia, os pesquisadores também identificaram sistemas de IA que aprenderam inesperadamente estratégias "inteligentes". Os exemplos incluem sistemas que aprenderam a jogar os jogos Breakout e Pinball da Atari. "Aqui, a IA entendeu claramente o conceito do jogo, e descobri uma maneira inteligente de coletar muitos pontos de maneira direcionada e de baixo risco. O sistema às vezes até intervém de maneiras que um jogador real não faria, "disse Wojciech Samek.
"Além de entender as estratégias de IA, nosso trabalho estabelece a usabilidade de IA explicável para design de conjunto de dados iterativo, ou seja, para remover artefatos em um conjunto de dados que faria com que uma IA aprendesse estratégias falhas, além de ajudar a decidir quais exemplos não rotulados precisam ser anotados e adicionados para que as falhas de um sistema de IA possam ser reduzidas, "disse o professor assistente do SUTD Alexander Binder.
"Nossa tecnologia automatizada é de código aberto e está disponível para todos os cientistas. Vemos nosso trabalho como um primeiro passo importante para tornar os sistemas de IA mais robustos, explicável e seguro no futuro, e mais terá que seguir. Este é um pré-requisito essencial para o uso geral de IA, "disse Klaus-Robert Müller.