A iniciativa Mozilla ajuda os jogadores de tecnologia de voz através de um conjunto de dados multilíngue
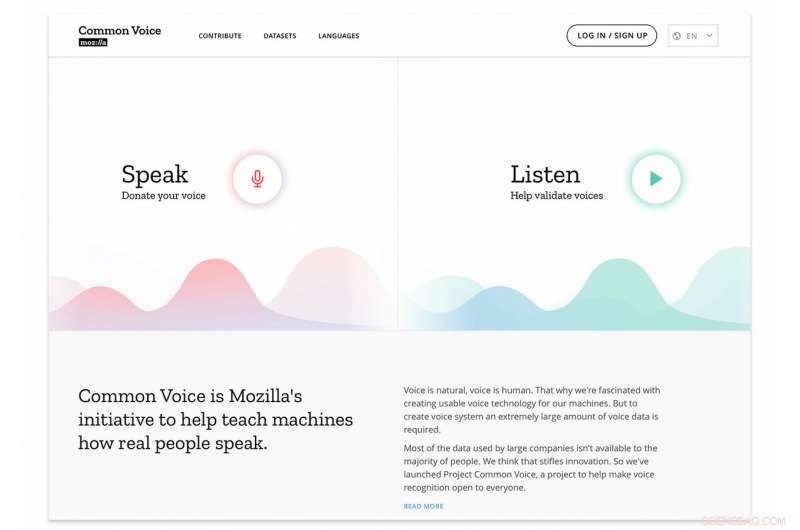
p Isso pode soar como um bocado, mas realmente significa muito. A Mozilla está falando sobre o "maior conjunto de dados de voz transcritos de domínio público". Tradução:Mais de 14, 000 pessoas. Em 18 idiomas. De quase 1, 400 horas (1, 368 para ser exato) de voz gravada. Bem-vindo a uma iniciativa chamada Common Voice. p Isso é o que dizia o anúncio da Mozilla, na forma de um blog na quinta-feira de George Roter.
p "Hoje, estamos entusiasmados em compartilhar nosso primeiro conjunto de dados multilíngue com 18 idiomas representados, incluindo inglês, Francês, Alemão e chinês mandarim (tradicional), mas também, por exemplo, galês e cabila. Completamente, o novo conjunto de dados inclui aproximadamente 1, 400 horas de clipes de voz de mais de 42, 000 pessoas. "
p Os contribuintes do projeto têm especialidades profissionais que vão desde candidatos a doutorado em reconhecimento de fala a cientistas do aprendizado de máquina e professor de lingüística computacional. Como tal, o esforço representa uma comunidade global de contribuidores de voz junto com o que a Mozilla credita como "voluntários apaixonados".
p O objetivo do Common Voice é ajudar a ensinar às máquinas como as pessoas reais falam. Em resumo, ele evoluiu para uma enorme coleção de clipes de voz em dezenas de idiomas. O que vem a seguir:o conjunto de dados completo estará disponível para download no site Common Voice.
p Parece que os colaboradores da equipe da Mozilla também resolveram os inevitáveis pontos problemáticos. O blog mencionou esses pontos. "As pessoas que contribuem não veem apenas o progresso por idioma na gravação e validação, mas também melhorou prompts que variam de clipe para clipe; nova funcionalidade para revisar, regravar, e pular clipes como parte integrante da experiência; a capacidade de mover-se rapidamente entre falar e ouvir; bem como uma função para cancelar o uso da palavra durante uma sessão. "
p Parece divertido ou uma caixa de areia acadêmica, mas na verdade existem aspirações mais sólidas entre aqueles que contribuíram para a construção de seu corpus.
p Em 2019, Mariella Moon em
Engadget percebeu que a variedade de idiomas agora inclui o holandês, Hakha-Chin, Esperanto, Farsi, Basco, Espanhol, Francês, Alemão, Chinês mandarim (tradicional), Galês e Kabyle.
p
TechRadar Olivia Tambini, disse, "Ao fornecer gratuitamente uma enorme biblioteca de vozes humanas em uma variedade de idiomas, A Mozilla pode estar abrindo as portas para empresas que não têm os recursos da Apple, Amazonas, e Google, para desenvolver seus próprios assistentes de voz. "
p Outro benefício envolve o próprio Mozilla. Mariella Moon em
Engadget disse, "A própria organização planeja usar os clipes que coleta para melhorar seu Speech-to-Text, Mecanismos de conversão de texto em fala e DeepSpeech. "
p Roter disse, claro e simples, "Nosso objetivo é lançar produtos habilitados para voz nós mesmos, ao mesmo tempo que apoia pesquisadores e jogadores menores. "
p Observe que o direito de se gabar pertence ao fato de ser o maior, não o único, conjunto de dados desse tipo. A Mozilla queria que os visitantes do site soubessem que era o maior, não o único, e também disse que, com o tempo, os visitantes do site podem "olhar para esta página como um centro de referência para outros conjuntos de dados de voz de código aberto".
p Se você visitar o site Common Voice, receberá a mensagem sobre sua grande ambição. "Estamos construindo, "disse a Mozilla. E o que eles estão construindo? Um" código aberto, conjunto de dados de vozes em vários idiomas que qualquer pessoa pode usar para treinar aplicativos habilitados para fala. "
p Os contribuidores podem optar por fornecer metadados como sua idade, sexo, e sotaque. Os clipes de voz, por sua vez, são marcados com informações úteis no treinamento de mecanismos de fala. p © 2019 Science X Network