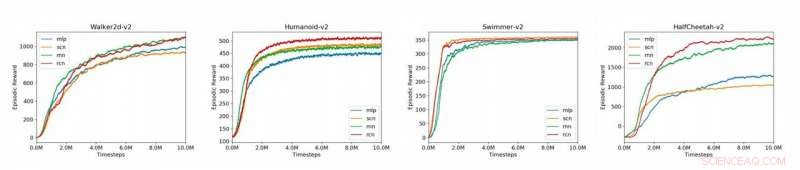
Representa a comparação dos modelos de linha de base (MLP, SCN, RNN, RCN) para os 4 ambientes MuJoCo apresentados no artigo (Humanoid-v2, HalfCheetah-v2, Walker2d-v2, Swimmer-v2). Crédito:Liu et al.
Geradores de padrão central (CPGs) são circuitos neurais biológicos que podem produzir saídas rítmicas coordenadas sem exigir entradas rítmicas. CPGs são responsáveis pela maioria dos movimentos rítmicos observados em organismos vivos, como caminhar, respirando ou nadando.
Ferramentas para modelar efetivamente saídas rítmicas quando fornecidas entradas arrítmicas podem ter aplicações importantes em uma variedade de campos, incluindo neurociência, robótica e medicina. Na aprendizagem por reforço, a maioria das redes existentes usadas para modelar tarefas de locomotivas, como modelos de linha de base perceptron multicamadas (MLP), falham em gerar saídas rítmicas na ausência de entradas rítmicas.
Estudos recentes têm proposto o uso de arquiteturas que podem dividir a política de uma rede em componentes lineares e não lineares, como redes de controle estruturadas (SCNs), que superaram as MLPs em uma variedade de ambientes. Um SCN compreende um modelo linear para controle local e um módulo não linear para controle global, cujas saídas são combinadas para produzir a ação política. Com base no trabalho anterior com redes neurais recorrentes (RNNs) e SCNs, uma equipe de pesquisadores da Universidade de Stanford desenvolveu recentemente uma nova abordagem para modelar CPGs na aprendizagem por reforço.
"CPGs são circuitos neurais biológicos capazes de produzir saídas rítmicas na ausência de entrada rítmica, "Ademi Adeniji, um dos pesquisadores que realizou o estudo, disse Tech Xplore. "As abordagens existentes para modelar CPGs na aprendizagem por reforço incluem o perceptron multicamadas (MLP), um simples, rede neural totalmente conectada, e a rede de controle estruturada (SCN), que possui módulos separados para controle local e global. Nosso objetivo de pesquisa era melhorar essas linhas de base, permitindo que o modelo capturasse observações anteriores, tornando-o menos sujeito a erros de ruído de entrada. "

Captura de tela do ambiente HalfCheetah. Crédito:Liu et al.
A rede de controle recorrente (RCN) desenvolvida por Adeniji e seus colegas adota a arquitetura de um SCN, mas usa um RNN vanilla para controle global. Isso permite que o modelo adquira local, controle global e dependente do tempo.
"Como SCN, nosso RCN divide o fluxo de informações em módulos lineares e não lineares, "Nathaniel Lee, um dos pesquisadores que realizou o estudo, disse TechXplore. "Intuitivamente, o módulo linear, efetivamente uma transformação linear, aprende as interações locais, enquanto o módulo não linear aprende interações globais. "
As abordagens SCN usam um MLP como módulo não linear, enquanto o RCN idealizado pelos pesquisadores substitui este módulo por um RNN. Como resultado, seu modelo adquire uma "memória" de observações anteriores, codificado pelo estado oculto do RNN, que ele então usa para gerar ações futuras.
Os pesquisadores avaliaram sua abordagem na plataforma OpenAI Gym, um ambiente de física para aprendizagem por reforço, bem como em dinâmica multiarticular com tarefas de contrato (Mu-JoCo). Seu RCN correspondeu ou superou outras MLPs e SCNs de linha de base em todos os ambientes testados, efetivamente aprendendo controle local e global enquanto adquire padrões de sequências anteriores.

Captura de tela do ambiente Humanóide. Crédito:Liu et al.
"Os CPGs são responsáveis por um grande número de padrões biológicos rítmicos, "Jason Zhao, outro pesquisador envolvido no estudo, disse. "A capacidade de modelar o comportamento do CPG pode ser aplicada com sucesso a campos como medicina e robótica. Também esperamos que nossa pesquisa destaque a eficácia do controle local / global, bem como arquiteturas recorrentes para modelagem de geração de padrão central na aprendizagem por reforço."
As descobertas coletadas pelos pesquisadores confirmam o potencial das estruturas do tipo SCN para modelar CPGs para aprendizagem por reforço. O estudo também sugere que os RNNs são particularmente eficazes para modelar tarefas de locomotivas e que a separação de módulos de controle linear e não linear pode melhorar significativamente o desempenho de um modelo.
"Até aqui, nós apenas treinamos nosso modelo usando estratégias evolutivas (ES), um otimizador fora do gradiente, "disse Vincent Liu, um dos pesquisadores envolvidos no estudo. "No futuro, planejamos explorar seu desempenho ao treiná-lo com otimização de política proximal (PPO), um otimizador em gradiente. Adicionalmente, avanços no processamento de linguagem natural mostraram que as redes neurais convolucionais são substitutos eficazes para as redes neurais recorrentes, tanto em desempenho quanto em computação. Poderíamos, portanto, considerar a experiência com uma arquitetura de rede neural de retardo de tempo, que aplica a convolução 1-D ao longo do eixo do tempo de observações anteriores. "
© 2019 Science X Network