Encontrando, e medir o discurso de ódio à islamofobia nas redes sociais. Crédito:John Gomez / Shutterstock
Em um movimento marcante, um grupo de parlamentares publicou recentemente uma definição prática do termo islamofobia. Eles o definiram como "enraizado no racismo", e como "um tipo de racismo que visa as expressões do muçulmano ou o que é percebido como muçulmano".
Em nosso último documento de trabalho, queríamos entender melhor a prevalência e a gravidade desse discurso de ódio islamofóbico nas redes sociais. Tal discurso prejudica as vítimas visadas, cria um sentimento de medo entre as comunidades muçulmanas, e viola os princípios fundamentais de justiça. Mas enfrentamos um desafio importante:embora extremamente prejudicial, O discurso de ódio islamofóbico é bastante raro.
Bilhões de postagens são enviadas nas redes sociais todos os dias, e apenas um pequeno número deles contém algum tipo de ódio. Então, começamos a criar uma ferramenta de classificação usando aprendizado de máquina que detecta automaticamente se os tweets contêm ou não islamofobia.
Detectando discurso de ódio islamofóbico
Grandes avanços foram feitos no uso de aprendizado de máquina para classificar o discurso de ódio mais geral de maneira robusta, em escala e em tempo hábil. Em particular, muito progresso foi feito para categorizar o conteúdo com base no fato de ser odioso ou não.
Mas o discurso de ódio islamofóbico é muito mais matizado e complexo do que isso. Ele vai desde o ataque verbal, abusar e insultar muçulmanos para ignorá-los; de destacar como eles são percebidos como "diferentes" para sugerir que eles não são membros legítimos da sociedade; da agressão à demissão. Queríamos levar essa nuance em consideração com nossa ferramenta para que pudéssemos categorizar se o conteúdo é islamofóbico ou não e se a islamofobia é forte ou fraca.
Definimos discurso de ódio islamofóbico como "qualquer conteúdo produzido ou compartilhado que expresse negatividade indiscriminada contra o Islã ou os muçulmanos". Isso difere, mas está bem alinhado com a definição de trabalho dos parlamentares de islamofobia, descrito acima. De acordo com nossas definições, islamofobia forte inclui declarações como "todos os muçulmanos são bárbaros", enquanto a islamofobia fraca inclui expressões mais sutis, como "os muçulmanos comem comida tão estranha".
Ser capaz de distinguir entre a islamofobia forte e fraca não só nos ajudará a detectar e remover melhor o ódio, mas também para entender a dinâmica da islamofobia, investigar processos de radicalização em que uma pessoa se torna progressivamente mais islamofóbica, e fornecer melhor apoio às vítimas.
Crédito:Vidgen e Yasseri
Configurando os parâmetros
A ferramenta que criamos é chamada de classificador de aprendizado de máquina supervisionado. O primeiro passo para criar um é criar um conjunto de dados de treinamento ou teste - é assim que a ferramenta aprende a atribuir tweets a cada uma das classes:islamofobia fraca, forte islamofobia e nenhuma islamofobia. A criação deste conjunto de dados é um processo difícil e demorado, pois cada tweet deve ser rotulado manualmente, portanto, a máquina tem uma base para aprender. Outro problema é que detectar discurso de ódio é inerentemente subjetivo. O que considero fortemente islamofóbico, você pode pensar que é fraco, e vice versa.
Fizemos duas coisas para mitigar isso. Primeiro, passamos muito tempo criando diretrizes para rotular os tweets. Segundo, três especialistas rotularam cada tweet, e utilizou testes estatísticos para verificar o quanto eles concordaram. Começamos com 4, 000 tweets, amostrados a partir de um conjunto de dados de 140 milhões de tweets que coletamos de março de 2016 a agosto de 2018. A maioria dos 4, 000 tweets não expressam qualquer islamofobia, então removemos muitos deles para criar um conjunto de dados balanceado, consistindo em 410 fortes, 484 fraco, e 447 nenhum (no total, 1, 341 tweets).
A segunda etapa foi construir e ajustar o classificador por meio de recursos de engenharia e seleção de um algoritmo. Recursos são o que o classificador usa para realmente atribuir cada tweet à classe certa. Nossa principal característica era um modelo de embeddings de palavras, um modelo de aprendizagem profunda que representa palavras individuais como um vetor de números, que pode então ser usado para estudar similaridade e uso de palavras. Também identificamos alguns outros recursos dos tweets, como a unidade gramatical, sentimento e o número de menções de mesquitas.
Depois de construir nosso classificador, a etapa final foi avaliá-lo, o que fizemos aplicando-o a um novo conjunto de dados de tweets completamente invisíveis. Selecionamos 100 tweets atribuídos a cada uma das três classes, então 300 no total, e nossos três programadores especialistas os renomearam. Isso nos permite avaliar o desempenho do classificador, comparando os rótulos atribuídos por nosso classificador com os rótulos reais.
A principal limitação do classificador era que ele lutava para identificar tuítes islamofóbicos fracos, já que muitas vezes se sobrepunham a tuítes islamofóbicos fortes e não islamofóbicos. Dito isto, geral, seu desempenho foi forte. A precisão (o número de tweets identificados corretamente) foi de 77% e a precisão de 78%. Devido ao nosso rigoroso processo de design e teste, podemos confiar que o classificador provavelmente terá um desempenho semelhante quando usado em escala "in the wild" em dados invisíveis do Twitter.
Usando nosso classificador
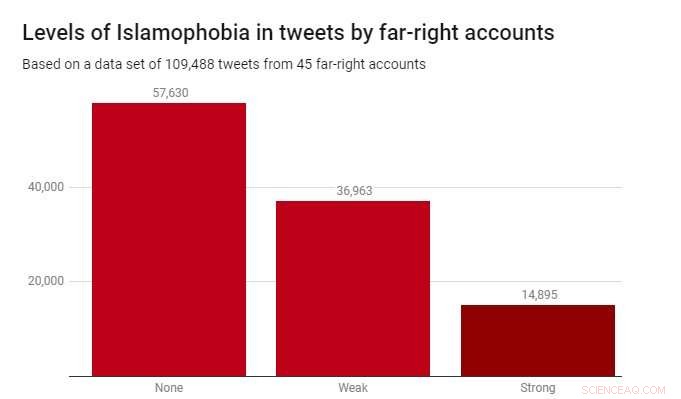
Aplicamos o classificador a um conjunto de dados de 109, 488 tweets produzidos por 45 contas de extrema direita durante 2017. Eles foram identificados pela instituição de caridade Hope Not Hate em seus relatórios State of Hate de 2015 e 2017. O gráfico abaixo mostra os resultados.
Embora a maioria dos tweets - 52,6% - não fosse islamofóbica, a islamofobia fraca foi consideravelmente mais prevalente (33,8%) do que a islamofobia forte (13,6%). Isso sugere que a maior parte da islamofobia nesses relatos de extrema direita é sutil e indireta, em vez de agressivo ou aberto.
Detectar o discurso de ódio islamofóbico é um desafio real e urgente para os governos, empresas de tecnologia e acadêmicos. Tristemente, este é um problema que não vai embora - e não existem soluções simples. Mas se levarmos a sério a remoção do discurso de ódio e do extremismo dos espaços online, e tornar as plataformas de mídia social seguras para todos que as usam, então precisamos começar com as ferramentas adequadas. Nosso trabalho mostra que é inteiramente possível fazer essas ferramentas - não apenas para detectar automaticamente o conteúdo odioso, mas também fazê-lo de uma maneira diferenciada e refinada.
Este artigo foi republicado de The Conversation sob uma licença Creative Commons. Leia o artigo original.