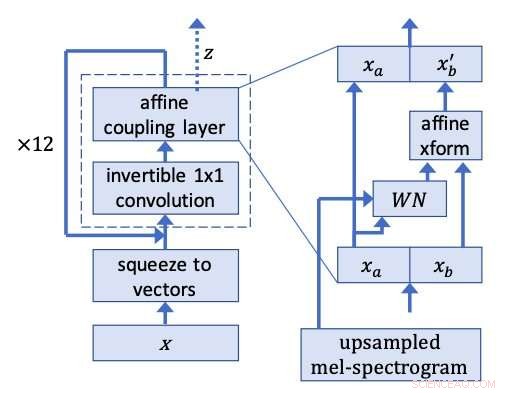
Rede WaveGlow. Crédito:Prenger, Valle, e Catanzaro.
Uma equipe de pesquisadores da NVIDIA desenvolveu recentemente o WaveGlow, uma rede baseada em fluxo que pode gerar voz de alta qualidade a partir de melespectrogramas, que são representações acústicas de tempo-frequência do som. Seu método, descrito em um artigo pré-publicado no arXiv, usa uma única rede treinada com uma única função de custo, tornando o procedimento de treinamento mais fácil e estável.
"A maioria das redes neurais para sintetizar fala eram muito lentas para nós, "Ryan Prenger, um dos pesquisadores que realizou o estudo, disse TechXplore. "Eles tinham velocidade limitada porque eram projetados para gerar apenas uma amostra por vez. As exceções eram abordagens do Google e do Baidu que geravam áudio muito rapidamente em paralelo. No entanto, essas abordagens usavam redes de professores e redes de alunos e eram complexas demais para serem replicadas. "
Os pesquisadores se inspiraram em Glow, uma rede baseada em fluxo da OpenAI que pode gerar imagens de alta qualidade em paralelo, mantendo uma estrutura bastante simples. Usando uma convolução 1x1 invertível, A Glow obteve resultados notáveis, produzindo imagens altamente realistas. Os pesquisadores decidiram aplicar a mesma ideia por trás desse método para a síntese da fala.
"Pense no ruído branco que vem de um rádio que não está ajustado para nenhuma estação, "Prenger explicou. Esse ruído branco é super fácil de gerar. A ideia básica de sintetizar fala com WaveGlow é treinar uma rede neural para transformar esse ruído branco em fala. Se você usar qualquer rede neural antiga, o treinamento será problemático. Mas se você usar especificamente uma rede que pode ser executada tanto para frente quanto para trás, a matemática fica fácil e alguns dos problemas de treinamento desaparecem. "
Os pesquisadores executaram clipes de fala do conjunto de dados de treinamento para trás, treinar WaveGlow para produzir o que mais se assemelha ao ruído branco. O modelo deles aplica a mesma ideia por trás do Glow para uma arquitetura do tipo WaveNet, daí o nome WaveGlow.
Em uma implementação PyTorch, WaveGlow produziu amostras de áudio a uma taxa de mais de 500 kHz, em uma GPU NVIDIA V100. Os testes de pontuação média de opinião (MOS) coletados no Amazon Mechanical Turk sugerem que a abordagem oferece qualidade de áudio tão boa quanto o melhor método WaveNet disponível publicamente.
"No mundo da síntese de voz, há uma necessidade de modelos que gerem fala mais do que uma ordem de magnitude mais rápido em tempo real, "Prenger disse." Esperamos que o WaveGlow possa atender a essa necessidade, sendo mais fácil de implementar e manter do que outros modelos existentes. No mundo do aprendizado profundo, pensamos que este tipo de abordagem usando uma rede neural invertível e a função de perda simples resultante é relativamente pouco estudada. O WaveGlow fornece outro exemplo de como essa abordagem pode fornecer resultados generativos de alta qualidade, apesar de sua relativa simplicidade. "
O código do WaveGlow está prontamente disponível online e pode ser acessado por outras pessoas que desejam experimentá-lo ou experimentá-lo. Enquanto isso, os pesquisadores estão trabalhando para melhorar a qualidade dos clipes de áudio sintetizados ajustando seu modelo e realizando avaliações adicionais.
"Não fizemos muitas análises para ver quão pequena é a rede que podemos usar, "Prenger disse." A maioria das nossas decisões de arquitetura foram baseadas nas primeiras partes do treinamento. Contudo, redes menores com maior tempo de treinamento podem gerar sons igualmente bons. Há muitas direções interessantes que essa pesquisa pode tomar no futuro. "
© 2018 Science X Network