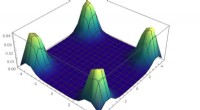
 p Como funciona o método:as observações são adicionadas à memória, a recompensa é calculada com base na distância entre nossa observação atual e a observação mais semelhante na memória. O agente recebe mais recompensa por ver observações que ainda não estão representadas na memória. Crédito:Savinov et al.
p Como funciona o método:as observações são adicionadas à memória, a recompensa é calculada com base na distância entre nossa observação atual e a observação mais semelhante na memória. O agente recebe mais recompensa por ver observações que ainda não estão representadas na memória. Crédito:Savinov et al.
p Várias tarefas do mundo real têm recompensas esparsas e isso apresenta desafios para o desenvolvimento de algoritmos de aprendizagem por reforço (RL). Uma solução para este problema é permitir que um agente crie autonomamente uma recompensa para si mesmo, tornando as recompensas mais densas e mais adequadas para o aprendizado. p Por exemplo, inspirado pelo comportamento curioso com o qual os animais exploram seu ambiente, a observação de algo novo por um algoritmo RL pode ser recompensada com um bônus. Este bônus, resumido com a recompensa da tarefa real, permitiria então que algoritmos RL aprendessem com uma recompensa combinada.
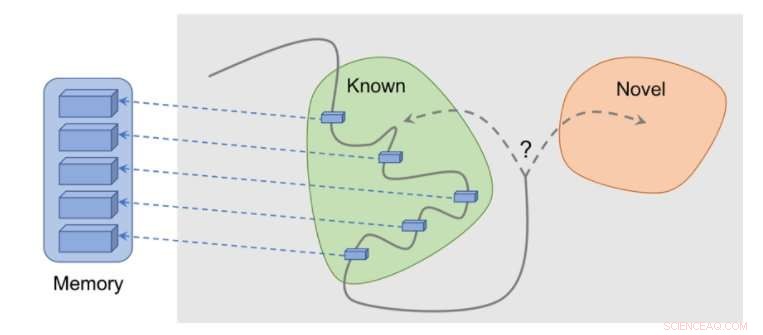
p Pesquisadores da DeepMind, O Google Brain e a ETH Zurich desenvolveram recentemente um novo método de curiosidade que usa a memória episódica para formar esse bônus de novidade. Este bônus é determinado comparando as observações atuais e as observações armazenadas na memória.
p "O principal objetivo do nosso trabalho foi investigar novas formas baseadas na memória de imbuir agentes de aprendizagem por reforço (RL) com 'curiosidade, 'com o que queremos dizer um impulso para explorar o ambiente, mesmo na completa ausência de recompensas, "Tim Lillicrap da DeepMind e Nikolay Savinov do Google Brain disseram à TechXplore por e-mail." A curiosidade foi abordada de várias maneiras pela comunidade de pesquisa, mas sentimos que várias ideias poderiam se beneficiar de uma exploração posterior. "
p As idéias-chave exploradas neste artigo recente baseiam-se em um estudo anterior realizado por Savinov, que propôs uma nova arquitetura de memória inspirada na navegação dos mamíferos. Essa arquitetura permite que os agentes repitam uma rota através de um ambiente usando apenas uma passagem visual. O novo método desenvolvido pelos pesquisadores dá um passo adiante, tentando alcançar uma boa exploração movida pela curiosidade.
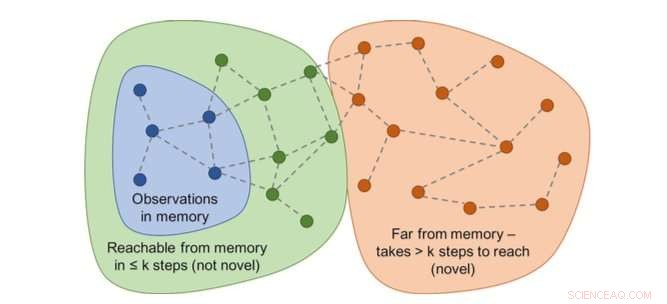 p O gráfico de acessibilidades determinaria a novidade. Na prática, este gráfico não está disponível - portanto, um aproximador de rede neural é treinado para estimar uma série de etapas entre as observações. Crédito:Savinov et al.
p O gráfico de acessibilidades determinaria a novidade. Na prática, este gráfico não está disponível - portanto, um aproximador de rede neural é treinado para estimar uma série de etapas entre as observações. Crédito:Savinov et al.
p "Enquanto atua, o agente armazena instâncias de representações de observação em sua memória episódica, "Lillicrap e Savinov disseram." Para determinar se a observação atual é nova ou não, é comparado com aqueles na memória. Se nada semelhante for encontrado, a observação atual é considerada nova e o agente é recompensado, caso contrário, recebe uma recompensa negativa. Isso incentiva o agente a explorar um território desconhecido, semelhante a ser curioso. "
p Os pesquisadores descobriram que comparar pares de observações pode ser complicado, pois a verificação de uma correspondência exata não tem sentido em ambientes realistas. Isso ocorre porque em situações do mundo real, um agente raramente observa a mesma coisa duas vezes.
p "Em vez de, treinamos uma rede neural para prever se o agente pode alcançar a observação atual daqueles que estão na memória realizando menos ações do que um limite fixo; dizer, cinco ações, "Lillicrap e Savinov explicaram." As observações dentro dessas cinco ações são consideradas semelhantes, enquanto aqueles que exigem mais ações para fazer uma transição são considerados diferentes. "
p Lillicrap, Savinov e seus colegas testaram sua abordagem em VizDoom e DMLab, dois ambientes 3D visualmente ricos. No VizDoom, o agente aprendeu a navegar com sucesso para um objetivo distante pelo menos duas vezes mais rápido do que o método de curiosidade de última geração ICM. No DMLab, o algoritmo foi bem generalizado para novo, níveis do jogo gerados processualmente, atingir seu objetivo desejado pelo menos duas vezes mais frequentemente do que ICM em labirintos de teste com recompensas muito escassas.
 p Método baseado em surpresa (ICM) é persistentemente marcar paredes com um gadget de ficção científica semelhante a laser em vez de explorar o labirinto. Este comportamento é semelhante à mudança de canal descrita antes:embora o resultado da marcação seja teoricamente previsível, não é fácil e aparentemente requer um conhecimento profundo de física que não é fácil de adquirir para um agente geral. Crédito:Savinov et al.
p Método baseado em surpresa (ICM) é persistentemente marcar paredes com um gadget de ficção científica semelhante a laser em vez de explorar o labirinto. Este comportamento é semelhante à mudança de canal descrita antes:embora o resultado da marcação seja teoricamente previsível, não é fácil e aparentemente requer um conhecimento profundo de física que não é fácil de adquirir para um agente geral. Crédito:Savinov et al.
p "Percebemos uma desvantagem interessante em um dos métodos mais populares para imbuir os agentes de curiosidade, "Lillicrap e Savinov disseram." Descobrimos que este método, com base na surpresa que é calculada por um modelo de mudança lenta que tenta prever o que acontecerá a seguir, pode resultar em uma resposta de gratificação instantânea do agente:em vez de resolver a tarefa em mãos, vai explorar ações que levam a consequências imprevisíveis para obter recompensa imediata. "
p Esta ocorrência peculiar, também conhecidos como problemas "viciados em sofá", implica que um agente encontre maneiras de se gratificar instantaneamente, explorando ações que levam a consequências imprevisíveis. Por exemplo, quando dado um controle remoto de TV, o agente não pode fazer nada além de mudar de canal, mesmo que sua tarefa original fosse totalmente diferente, como procurar um objetivo em um labirinto.
p "Essa deficiência pode ser aliviada usando a memória episódica junto com uma medida razoável de semelhança de observação, qual é a nossa contribuição, "Lillicrap e Savinov disseram." Isso abre um caminho para uma exploração mais inteligente. "
 p Nosso método mostra uma exploração razoável. Crédito:Savinov et al.
p Nosso método mostra uma exploração razoável. Crédito:Savinov et al.
p O novo método de curiosidade desenvolvido por Lillicrap, Savinov, e seus colegas podem ajudar a replicar habilidades de curiosidade em algoritmos RL, permitindo-lhes criar recompensas para si próprios de forma autônoma. No futuro, os pesquisadores gostariam de usar a memória episódica não apenas para conceder recompensas, mas também para o planejamento de ações.
p "Por exemplo, o conteúdo recuperado da memória pode ser usado para pensar sobre para onde ir a seguir? ", disseram Lillicrap e Savinov." Este é atualmente um grande desafio científico:se resolvido, os agentes seriam capazes de adaptar rapidamente as estratégias de exploração a novos ambientes, permitindo que o aprendizado aconteça em um ritmo muito mais rápido. " p © 2018 Tech Xplore