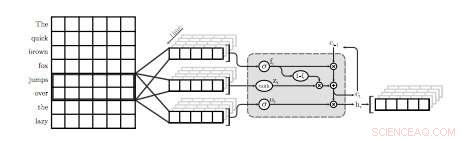
Uma ilustração da primeira camada QRNN para modelagem de linguagem. Nesta visualização, uma camada QRNN com um tamanho de janela de dois convolves e pools usando embeddings da entrada. Observe a ausência de pesos recorrentes. Crédito:Tang &Lin.
Uma equipe de pesquisadores da Universidade de Waterloo, no Canadá, realizou recentemente um estudo explorando as compensações entre precisão e eficiência de modelos de linguagem neural (NLMs) aplicados especificamente a dispositivos móveis. Em seu jornal, que foi pré-publicado no arXiv, os pesquisadores também propuseram uma técnica simples para recuperar algumas perplexidades, uma medida do desempenho de um modelo de linguagem, usando uma quantidade insignificante de memória.
NLMs são modelos de linguagem baseados em redes neurais por meio das quais algoritmos podem aprender a distribuição típica de sequências de palavras e fazer previsões sobre a próxima palavra em uma frase. Esses modelos têm várias aplicações úteis, por exemplo, habilitando teclados de software mais inteligentes para telefones celulares ou outros dispositivos.
"Os modelos de linguagem neural (NLMs) existem em um espaço de compensação entre precisão e eficiência, onde uma melhor perplexidade normalmente vem ao custo de uma maior complexidade de computação, "os pesquisadores escreveram em seu artigo." Em um aplicativo de teclado de software em dispositivos móveis, isso se traduz em maior consumo de energia e menor vida útil da bateria. "
Quando aplicado a teclados de software, Os NLMs podem levar a uma previsão mais precisa da palavra seguinte, permitindo que os usuários insiram a próxima palavra em uma determinada frase com um único toque. Dois aplicativos existentes que usam redes neurais para fornecer esse recurso são SwiftKey1 e Swype2. Contudo, esses aplicativos geralmente requerem muita energia para funcionar, drenando rapidamente as baterias de dispositivos móveis.
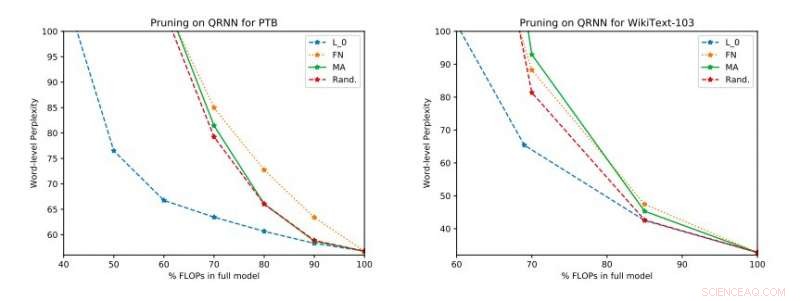
Resultados experimentais completos em Penn Treebank e WikiText-103. Ilustramos o espaço de troca perplexidade-eficiência no conjunto de teste obtido antes de aplicar a atualização de classificação única. Crédito:Tang &Lin.
"Com base em métricas padrão, como perplexidade, técnicas neurais representam um avanço no estado da arte da modelagem de linguagem, "os pesquisadores explicaram em seu artigo." Melhores modelos, Contudo, têm um custo em complexidade computacional, o que se traduz em maior consumo de energia. No contexto de dispositivos móveis, eficiência energética é, claro, um importante objetivo de otimização. "
De acordo com os pesquisadores, Até agora, os NLMs foram avaliados principalmente no contexto de reconhecimento de imagem e localização de palavras-chave, embora sua compensação entre precisão e eficiência em aplicativos de processamento de linguagem natural (PNL) ainda não tenha sido completamente investigada. Seu estudo se concentra nesta área de pesquisa inexplorada, realizando uma avaliação de NLMs e suas compensações precisão-eficiência em um Raspberry Pi.
"Nossas avaliações empíricas consideram a perplexidade, bem como o consumo de energia em um Raspberry Pi, onde demonstramos quais métodos fornecem o melhor ponto operacional de consumo de energia perplexidade, "disseram os pesquisadores." Em um ponto operacional, uma das técnicas é capaz de fornecer economia de energia de 40 por cento em relação aos [métodos] de última geração, com apenas um aumento relativo de 17 por cento na perplexidade. "
Em seu estudo, os pesquisadores também avaliaram uma série de técnicas de poda de tempo de inferência em redes neurais quase recorrentes (QRNNs). Estendendo a usabilidade dos métodos de poda de tempo de treinamento existentes para QRNNs em tempo de execução, eles alcançaram vários pontos operacionais dentro do espaço de troca precisão-eficiência. Para melhorar o desempenho usando uma pequena quantidade de memória, eles sugeriram treinar e armazenar atualizações de peso de classificação única nos pontos operacionais desejados.
© 2018 Tech Xplore