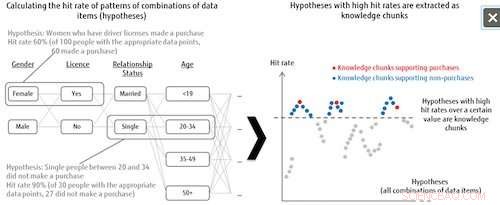
Figura 1:Lista de hipóteses e extração de bloco de conhecimento. Crédito:Fujitsu
Fujitsu Laboratories Ltd. anunciou hoje o desenvolvimento de "Wide Learning, "uma tecnologia de aprendizado de máquina capaz de julgamentos precisos, mesmo quando os operadores não podem obter o volume de dados necessário para o treinamento. AI agora é frequentemente usada para aproveitar dados em uma variedade de campos, mas a precisão da IA pode ser afetada nos casos em que o volume de dados a ser analisado é pequeno ou desequilibrado. A tecnologia Wide Learning da Fujitsu permite que os julgamentos sejam alcançados com mais precisão do que era possível anteriormente, e a aprendizagem é alcançada de maneira uniforme, não importa qual hipótese é examinada, mesmo quando os dados estão desequilibrados. Ele consegue isso extraindo primeiro hipóteses com um alto grau de importância, tendo feito um grande conjunto de hipóteses formadas por todas as combinações de itens de dados, e então controlando o grau de impacto de cada hipótese respectiva com base nas relações de sobreposição das hipóteses. Além disso, porque as hipóteses são registradas como expressões lógicas, os humanos também podem entender o raciocínio por trás de um julgamento. A nova tecnologia Wide Learning da Fujitsu permite o uso de IA mesmo em áreas como saúde e marketing, onde os dados necessários para fazer julgamentos são escassos, apoiando as operações e promovendo a automatização dos processos de trabalho por meio de IA.
Nos últimos anos, A tecnologia de IA começou a ser usada em uma variedade de campos, incluindo saúde, marketing, e finanças. As expectativas estão aumentando para o uso de tomada de decisão de IA no suporte de operações e tarefas de automação nessas áreas. Um desafio que permanece para perceber o potencial dessas tecnologias, Contudo, é que os dados podem estar desequilibrados. Especificamente, dependendo do setor, pode ser difícil obter dados suficientes para treinar IA nos alvos sobre os quais deve fazer julgamentos. Esse, na verdade, deixa muitas dessas tecnologias incapazes de produzir resultados com precisão suficiente para uso prático. Além disso, a principal razão pela qual a implantação de IA carece de progresso é que, mesmo quando uma IA fornece reconhecimento suficientemente preciso ou desempenho de classificação, especialistas e até mesmo os próprios desenvolvedores muitas vezes não conseguem explicar por que a IA produziu uma determinada resposta, e se eles não puderem cumprir sua responsabilidade de explicar os resultados para as linhas de frente da indústria, a IA não pode ser implantada.
As tecnologias de IA baseadas em aprendizagem profunda convencionalmente fazem julgamentos altamente precisos sendo treinadas em grandes volumes de dados, incluindo amplos dados do alvo a serem julgados. Em cenários do mundo real, Contudo, há muitos casos em que os dados são insuficientes, com extremamente poucos dados de destino. Nesses casos, quando confrontado com dados desconhecidos, torna-se difícil para a tecnologia de IA fornecer julgamentos altamente precisos. Além disso, o modelo de aprendizado de máquina para IA existente com base no aprendizado profundo é um modelo de caixa preta que não pode explicar as razões por trás dos julgamentos que a IA faz, criando um problema de transparência. Como tal, no futuro, será necessário desenvolver uma nova tecnologia de IA que realize julgamentos altamente precisos a partir de dados desequilibrados, e que também seja transparente para resolver diversos problemas da sociedade.
Tendo esses desafios em mente, Fujitsu Laboratories desenvolveu Wide Learning, uma tecnologia de aprendizado de máquina capaz de fazer julgamentos altamente precisos, mesmo nos casos em que os dados estão desequilibrados. Os recursos da tecnologia Wide Learning incluem os dois pontos a seguir.
1. Cria combinações de itens de dados para extrair grandes volumes de hipóteses
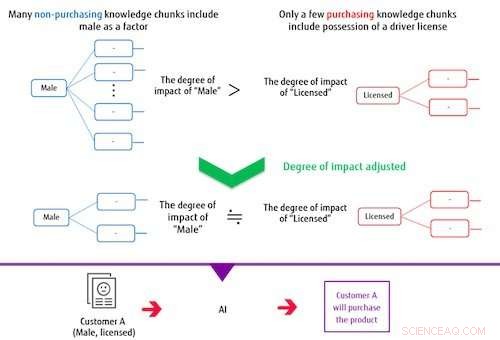
Figura 2:Ao fazer um modelo de classificação, os blocos de conhecimento impactam o ajuste. Crédito:Fujitsu
Esta tecnologia trata todos os padrões de combinação de itens de dados como hipóteses, e, em seguida, determina o grau de importância de cada hipótese com base na taxa de acerto para a categoria de rótulo. Por exemplo, ao analisar tendências de quem compra determinados produtos, o sistema combina todos os tipos de padrões dos itens de dados para aqueles que fizeram ou não compras (o rótulo da categoria), como mulheres solteiras entre 20-34 anos que têm carteira de motorista, e, em seguida, analisa quantos acertos obtém nos dados de quem realmente fez compras quando esses padrões de combinação são tomados como hipóteses. As hipóteses que alcançam uma taxa de acerto acima de um determinado nível são definidas como hipóteses importantes, chamados de "blocos de conhecimento". Isso significa que mesmo quando os dados de destino são insuficientes, o sistema pode extrair todas as hipóteses que vale a pena examinar, o que também pode contribuir para a descoberta de explicações anteriormente não consideradas.
2. Ajusta o grau de impacto dos blocos de conhecimento para construir um modelo de classificação preciso
O sistema constrói um modelo de classificação com base em vários blocos de conhecimento extraídos e no rótulo de destino. Nesse processo, se os itens que compõem um bloco de conhecimento freqüentemente se sobrepõem aos itens que constituem outros blocos de conhecimento, o sistema controla seu grau de impacto de forma a reduzir o peso de sua influência no modelo de classificação. Desta maneira, o sistema pode treinar um modelo capaz de classificações precisas mesmo quando o rótulo de destino ou os dados marcados como corretos estiverem desequilibrados. Por exemplo, em um caso em que os homens que não fizeram uma compra constituem a grande maioria do conjunto de dados de compra de um item, se a IA for treinada sem controlar o grau de impacto, em seguida, o bloco de conhecimento que inclui se uma pessoa tem ou não uma licença, independente do gênero, não terá muita influência na classificação. Com este método recentemente desenvolvido, o grau de impacto dos blocos de conhecimento, incluindo o masculino como um fator, é limitado devido à sobreposição deste item, enquanto o impacto do menor número de blocos de conhecimento que incluem se uma pessoa tem uma licença torna-se relativamente maior no treinamento, construir um modelo que possa categorizar corretamente os homens e a posse de uma licença.
Fujitsu Laboratories conduziu um teste desta tecnologia, aplicá-lo a dados em áreas como marketing digital e saúde. Em um teste usando dados de benchmark nas áreas de marketing e saúde do UC Irvine Machine Learning Repository, esta tecnologia melhorou a precisão em cerca de 10-20% em comparação com o aprendizado profundo. Ele reduziu com sucesso a probabilidade de o sistema ignorar os clientes que provavelmente assinariam um serviço ou pacientes com uma condição em cerca de 20-50%. Nos dados de marketing, de aproximadamente 5, 000 entradas de dados do cliente usadas no teste, apenas cerca de 230 eram para clientes compradores, fazendo para um conjunto desequilibrado. Essa tecnologia reduziu o número de clientes em potencial excluídos das promoções de vendas de 120, o resultado da análise de aprendizagem profunda, a 74. Além disso, como os blocos de conhecimento que formam a base para esta tecnologia têm um formato de expressão lógico, a capacidade de explicar o raciocínio por trás de um julgamento também é útil na implementação dessa tecnologia na sociedade. Mesmo quando é determinado que as correções em um modelo são necessárias, com base nos resultados de novos dados, é possível fazer revisões mais adequadas, porque os usuários podem entender os motivos dos resultados.
A Fujitsu Laboratories continuará a aplicar esta tecnologia a tarefas que exigem o raciocínio por trás dos julgamentos de IA, como em transações financeiras e diagnósticos médicos, e para tarefas que lidam com fenômenos de baixa frequência, como fraude e avarias de equipamento, com o objetivo de comercializá-lo como uma nova tecnologia de aprendizado de máquina para apoiar a Fujitsu Human Centric AI Zinrai da Fujitsu Limited no ano fiscal de 2019. A Fujitsu Laboratories também fará uso eficaz da capacidade característica desta tecnologia para explicação, pesquisa e desenvolvimento contínuos em tópicos como suporte aprimorado para fazer julgamentos e tomar decisões nas tarefas às quais é aplicado, e no design geral do sistema, incluindo colaboração com humanos.