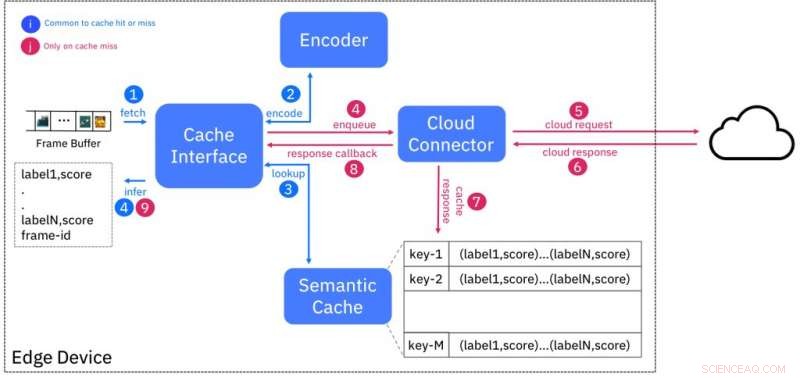
Diagrama de blocos do serviço de cache semântico. Crédito:IBM
A disponibilidade de alta resolução, sensores baratos aumentaram exponencialmente a quantidade de dados sendo produzidos, o que pode sobrecarregar a Internet existente. Isso levou à necessidade de capacidade de computação para processar os dados perto de onde são gerados, nas bordas da rede, em vez de enviá-lo para datacenters em nuvem. Computação de ponta, como isso é conhecido, não apenas reduz a pressão sobre a largura de banda, mas também reduz a latência de obtenção de inteligência de dados brutos. Contudo, a disponibilidade de recursos no limite é limitada devido à falta de economias de escala que tornam a infraestrutura em nuvem econômica para gerenciar e oferecer.
O potencial da computação de ponta não é mais óbvio do que com a análise de vídeo. Câmeras de vídeo de alta definição (1080p) estão se tornando comuns em domínios como vigilância e, dependendo da taxa de quadros e compressão de dados, pode produzir 4-12 megabits de dados por segundo. As câmeras mais recentes de resolução 4K produzem dados brutos da ordem de gigabits por segundo. O requisito de insights em tempo real sobre esses fluxos de vídeo está levando ao uso de técnicas de IA, como redes neurais profundas para tarefas, incluindo classificação, detecção e extração de objetos, e detecção de anomalias.
Em nosso Hot Edge 2018 Conference Paper "Shadow Puppets:Cloud-level Accurate AI Inference na velocidade e economia do Edge, "nossa equipe na IBM Research - Irlanda avaliou experimentalmente o desempenho de uma dessas cargas de trabalho de IA, classificação de objetos, usando serviços hospedados em nuvem disponíveis comercialmente. O melhor resultado que conseguimos foi uma saída de classificação de 2 quadros por segundo, que está muito abaixo da taxa de produção de vídeo padrão de 24 quadros por segundo. A execução de um experimento semelhante em um dispositivo de borda representativo (NVIDIA Jetson TK1) atingiu os requisitos de latência, mas usou a maioria dos recursos disponíveis no dispositivo neste processo.
Quebramos essa dualidade propondo o Cache Semântico, uma abordagem que combina a baixa latência de implantações de borda com os recursos quase infinitos disponíveis na nuvem. Usamos a técnica bem conhecida de armazenamento em cache para mascarar a latência, executando a inferência de IA para uma determinada entrada (por exemplo, quadro de vídeo) na nuvem e armazenando os resultados na borda contra uma "impressão digital", ou um código hash, com base em recursos extraídos da entrada.
Este esquema é projetado de modo que as entradas sendo semanticamente semelhantes (por exemplo, pertencentes à mesma classe) terão impressões digitais que estão "próximas" umas das outras, de acordo com alguma medida de distância. A Figura 1 mostra o design do cache. O codificador cria a impressão digital de um quadro de vídeo de entrada e procura no cache por impressões digitais dentro de uma distância específica. Se houver uma correspondência, então, os resultados da inferência são fornecidos a partir do cache, evitando assim a necessidade de consultar o serviço de IA em execução na nuvem.
Encontramos as impressões digitais análogas aos fantoches de sombra, projeções bidimensionais de figuras em uma tela criada por uma luz de fundo. Quem já usou os dedos para criar fantoches de sombra atestará que a ausência de detalhes nessas figuras não restringe sua capacidade de ser a base para uma boa narrativa. As impressões digitais são projeções da entrada real que podem ser usadas para aplicações ricas de IA, mesmo na ausência de detalhes originais.
Desenvolvemos uma implementação completa de prova de conceito do cache semântico, seguindo uma abordagem de design "como serviço", e expor o serviço a usuários de dispositivo / gateway de ponta por meio de uma interface REST. Nossas avaliações em uma variedade de dispositivos periféricos (Raspberry Pi 3 / NVIDIA Jetson TK1 / TX1 / TX2) demonstraram que a latência de inferência foi reduzida em 3 vezes e o uso de largura de banda em pelo menos 50 por cento quando comparado a uma nuvem única solução.
A avaliação inicial de um primeiro protótipo de implementação de nossa abordagem mostra seu potencial. Continuamos amadurecendo a abordagem inicial, priorizando a experimentação de técnicas alternativas de codificação para melhorar a precisão, ao mesmo tempo em que estende a avaliação para outros conjuntos de dados e tarefas de IA.
Prevemos que essa tecnologia tenha aplicações no varejo, manutenção preditiva para instalações industriais, e vigilância por vídeo, entre outros. Por exemplo, o cache semântico pode ser usado para armazenar impressões digitais de imagens de produtos em caixas. Isso pode ser usado para evitar perdas de armazenamento devido a roubo ou digitalização incorreta. Nossa abordagem serve como um exemplo de alternar perfeitamente entre a nuvem e os serviços de ponta para fornecer as melhores soluções de IA na ponta.
Esta história foi republicada por cortesia da IBM Research. Leia a história original aqui.














