Os computadores são ótimos para categorizar imagens pelos objetos encontrados com eles, mas eles são surpreendentemente ruins em descobrir quando dois objetos em uma única imagem são iguais ou diferentes um do outro. Novas pesquisas ajudam a mostrar por que essa tarefa é tão difícil para os algoritmos modernos de visão por computador. Crédito:Serre lab / Brown University
Os algoritmos de visão computacional evoluíram muito na última década. Eles se mostraram tão bons ou melhores do que as pessoas em tarefas como categorizar raças de cães ou gatos, e eles têm a notável capacidade de identificar rostos específicos em um mar de milhões.
Mas pesquisas feitas por cientistas da Brown University mostram que os computadores falham miseravelmente em uma classe de tarefas que nem mesmo as crianças têm problemas:determinar se dois objetos em uma imagem são iguais ou diferentes. Em um artigo apresentado na semana passada na reunião anual da Cognitive Science Society, a equipe de Brown esclarece por que os computadores são tão ruins nesses tipos de tarefas e sugere caminhos para sistemas de visão computacional mais inteligentes.
"Há muito entusiasmo sobre o que a visão computacional foi capaz de alcançar, e eu compartilho muito disso, "disse Thomas Serre, professor associado de cognitiva, ciências linguísticas e psicológicas na Brown e o autor sênior do artigo. "Mas pensamos que, trabalhando para entender as limitações dos sistemas de visão computacional atuais, como fizemos aqui, podemos realmente nos mover em direção ao novo, sistemas muito mais avançados, em vez de simplesmente ajustar os sistemas que já temos. "
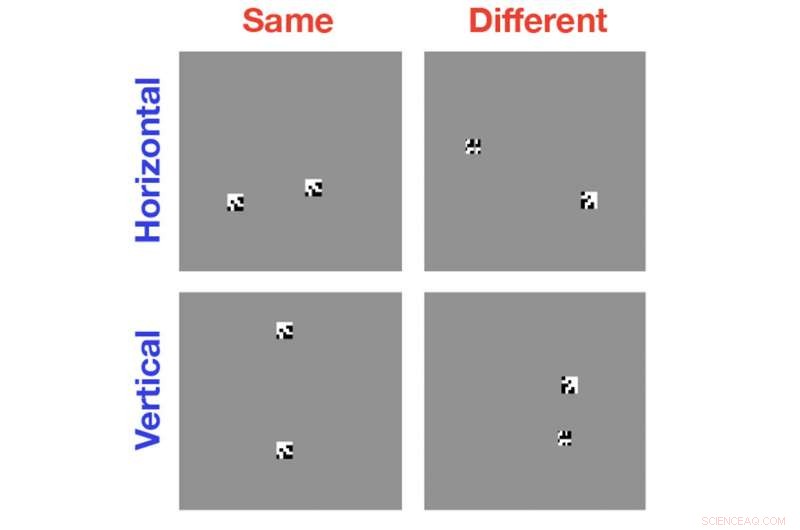
Para o estudo, Serre e seus colegas usaram algoritmos de visão computacional de última geração para analisar imagens em preto e branco simples contendo duas ou mais formas geradas aleatoriamente. Em alguns casos, os objetos eram idênticos; às vezes eram iguais, mas com um objeto girado em relação ao outro; às vezes os objetos eram completamente diferentes. O computador foi solicitado a identificar a relação igual ou diferente.
O estudo mostrou que, mesmo depois de centenas de milhares de exemplos de treinamento, os algoritmos não eram melhores do que a chance de reconhecer a relação apropriada. A questão, então, foi por isso que esses sistemas são tão ruins nessa tarefa.
Serre e seus colegas suspeitavam que isso tivesse algo a ver com a incapacidade desses algoritmos de visão computacional de individualizar objetos. Quando os computadores olham para uma imagem, eles não podem realmente dizer onde um objeto na imagem para e o fundo, ou outro objeto, começa. Eles apenas veem uma coleção de pixels com padrões semelhantes a coleções de pixels que aprenderam a associar a certos rótulos. Isso funciona bem para problemas de identificação ou categorização, mas desmorona ao tentar comparar dois objetos.
Para mostrar que era realmente por isso que os algoritmos estavam quebrando, Serre e sua equipe realizaram experimentos que dispensaram o computador de individualizar objetos por conta própria. Em vez de mostrar ao computador dois objetos na mesma imagem, os pesquisadores mostraram ao computador os objetos um de cada vez em imagens separadas. Os experimentos mostraram que os algoritmos não tinham problemas para aprender a relação igual ou diferente, desde que não tivessem que ver os dois objetos na mesma imagem.
A fonte do problema na individuação de objetos, Serre diz, é a arquitetura dos sistemas de aprendizado de máquina que alimentam os algoritmos. Os algoritmos usam redes neurais convolucionais - camadas de unidades de processamento conectadas que imitam vagamente redes de neurônios no cérebro. Uma diferença fundamental em relação ao cérebro é que as redes artificiais são exclusivamente "feed-forward" - o que significa que a informação tem um fluxo unilateral através das camadas da rede. Não é assim que o sistema visual em humanos funciona, de acordo com Serre.
"Se você olhar para a anatomia de nosso próprio sistema visual, você descobre que há muitas conexões recorrentes, onde a informação vai de uma área visual superior para uma área visual inferior e vice-versa, "Disse Serre.
Embora não esteja claro exatamente o que esses feedbacks fazem, Serre diz, é provável que tenham algo a ver com nossa capacidade de prestar atenção a certas partes de nosso campo visual e fazer representações mentais de objetos em nossas mentes.
"Presumivelmente, as pessoas atendem a um objeto, construir uma representação de recurso que está ligada a esse objeto em sua memória de trabalho, "Serre disse." Então eles mudam sua atenção para outro objeto. Quando ambos os objetos são representados na memória de trabalho, seu sistema visual é capaz de fazer comparações como igual ou diferente. "
Serre e seus colegas levantam a hipótese de que a razão pela qual os computadores não podem fazer nada parecido é porque as redes neurais feed-forward não permitem o tipo de processamento recorrente necessário para essa individuação e representação mental de objetos. Poderia ser, Serre diz, que tornar a visão computacional mais inteligente exigirá redes neurais que se aproximem mais da natureza recorrente do processamento visual humano.














