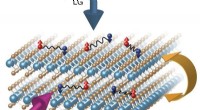
Figura 1. Esquema de célula unitária de uma matriz de ponto cruzado baseada em capacitor. Crédito:IBM
A IBM está indo além das tecnologias digitais com uma matriz de cross-point baseada em capacitor para redes neurais analógicas, exibindo potenciais melhorias de ordens de magnitude em cálculos de aprendizado profundo. As arquiteturas de computação analógica exploram a capacidade de armazenamento e os atributos físicos de certos dispositivos de memória não apenas para armazenar informações, mas também para realizar cálculos. Isso tem o potencial de reduzir significativamente o tempo e a energia exigidos pelos computadores, porque os dados não precisam ser transferidos entre a memória e o processador. A desvantagem pode ser uma redução na precisão computacional, mas para sistemas que não requerem alta precisão, é a compensação certa.
Em redes neurais analógicas (NN), Matrizes de ponto cruzado baseadas em memória não volátil (NVM) alcançaram resultados promissores para tarefas de inferência. Contudo, treinar NNs com alta precisão é difícil para dispositivos NVM, uma vez que o treinamento bem-sucedido depende de manter as mudanças incrementais no peso do NN pequenas (exigindo cerca de 1, 000 estados de atualização) e simétricos (para que as atualizações positivas e negativas balancem em média). Esses problemas podem ser resolvidos usando capacitores. Uma vez que a carga pode ser adicionada ou subtraída continuamente se o número de elétrons for alto, a atualização de peso analógico e simétrico pode ser alcançada. Apresentamos uma matriz de ponto cruzado baseada em capacitor para redes neurais analógicas no Simpósio de Tecnologia VLSI 2018. A nova arquitetura alcançou simetria e linearidade recordes para atualização de peso.
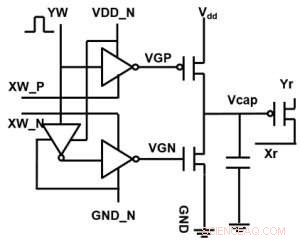
A Figura 1 mostra o esquema de célula unitária de uma matriz de ponto cruzado com base em capacitor. O componente principal é o capacitor que é conectado a um transistor de efeito de campo de leitura (FET). A carga no capacitor representa o peso sináptico e o capacitor é carregado e descarregado com duas fontes de corrente FETs. A Figura 2 mostra a mudança medida na condutância da leitura FET de uma única célula, e a tensão do capacitor correspondente, respectivamente, aplicando dez ciclos de 400 atualizações positivas seguidas por 400 atualizações negativas. A Figura 3 compara os fatores experimentais de atualização de não linearidade para nossa sinapse analógica baseada em capacitor com outras tecnologias NVM. A célula unitária baseada em capacitor fornece a melhor simetria e linearidade demonstrada até o momento. A Figura 4 demonstra a atualização de peso paralela em uma matriz 2 × 2.
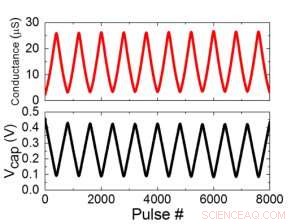
Figura 2. (a) Resultados experimentais para atualização de célula única com 8.000 pulsos. (b) Mudança de tensão do capacitor correspondente. Largura de pulso 50 ns, período:500 ns. Crédito:IBM
Mesmo que os capacitores sejam voláteis, o vazamento pode ser compensado durante a atualização do peso. Como o treinamento avança repetidamente, ciclos de atualização para trás e peso, os pesos após a decadência no ciclo anterior são usados no treinamento para o próximo ciclo e são atualizados. Portanto, nenhum ciclo de atualização intencional é necessário. Testamos o efeito do tempo de retenção no treinamento, usando uma rede totalmente conectada. Tem uma camada de entrada, duas camadas ocultas, e uma camada de saída (Figura 5) e foi treinada no conjunto de dados MNIST por descida gradiente estocástica e retropropagação. Assumindo que a duração do ciclo de treinamento por camada (para frente + para trás + atualização) é de 200 ns e o peso sináptico decai com a constante de tempo RC τ, descobrimos que a penalidade na precisão do treinamento devido à perda de carga do capacitor torna-se insignificante quando τ> 106 × a duração do ciclo de treinamento (Figura 6). Também testamos o requisito de tempo de retenção para uma rede convolucional. Nossa rede de teste tem duas camadas convolucionais com duas camadas de pooling e duas camadas totalmente conectadas (Figura 7). Devido ao compartilhamento de peso (reutilização) em camadas convolucionais, os requisitos de retenção para uma rede neural convolucional (CNN) são cerca de 600 maiores (Figura 8).
Estimamos a escalabilidade dessa matriz baseada em capacitor como uma função de vazamento para redes neurais totalmente conectadas e convolucionais (Figura 9). Os pontos de dados do círculo mostram que o capacitor escala linearmente com o vazamento do transistor de passagem. Os pontos de dados quadrados mostram que quando o vazamento é grande, a área da célula é dominada pelos capacitores; quando a corrente de fuga é pequena, a área será dominada por FETs na célula. Para a tecnologia DRAM com vazamento de 1 fA / célula requer capacitor <1fF / célula para rede neural totalmente conectada e ~ 100 fF / célula para CNN. A escalabilidade para uma entrada maior e mais camadas precisa de um estudo mais aprofundado. Mesmo que precise de um capacitor maior quando a entrada fica maior, nossos resultados preliminares (a serem publicados) mostram que a otimização da rede / algoritmo pode reduzir a necessidade de capacitores.
A IBM está trabalhando agora em uma nova memória ideal com comportamento analógico otimizado. Esses capacitores permitirão que o núcleo de AI analógico seja implementado em um cronograma acelerado, uma vez que a tecnologia e o processo estão disponíveis.
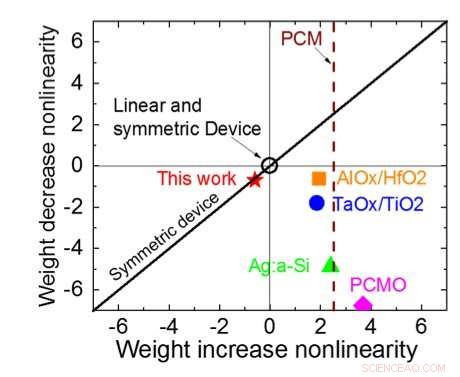
Figura 3. Não linearidade de condutância deste trabalho em comparação com outras tecnologias NVM. Crédito:IBM
Além de nossa abordagem de capacitor, A IBM está explorando outros novos elementos para memória analógica e computação, como memória de mudança de fase (PCM) e RAM resistiva (RRAM). Esses elementos variam em termos de áreas de células, retenção, simetria, e maturidade. Os aceleradores analógicos são um componente do pipeline de aceleradores de hardware de AI do IBM Research AI. O pipeline começa com a obtenção do máximo dos aceleradores de GPU existentes, seguido por inovadores núcleos de IA digital que exploram computação aproximada.
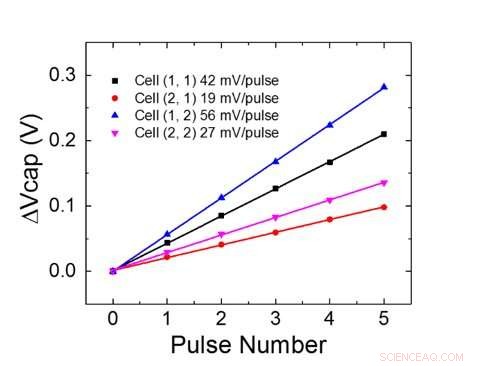
Figura 4. Atualização de peso paralelo em uma matriz 2 × 2. Crédito:IBM
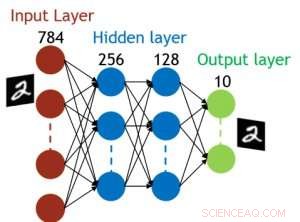
Figura 5. Estrutura simulada para rede neural totalmente conectada. Crédito:IBM
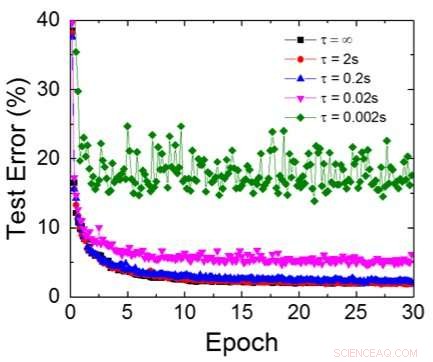
Figura 6. Erro de teste simulado do conjunto de dados MNIST, assumindo que os pesos decaem continuamente com diferentes constantes de tempo RC τ, Duração do ciclo de treinamento de 200ns. Crédito:IBM
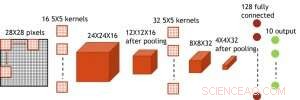
Figura 7. Estrutura simulada para rede neural convolucional. Crédito:IBM
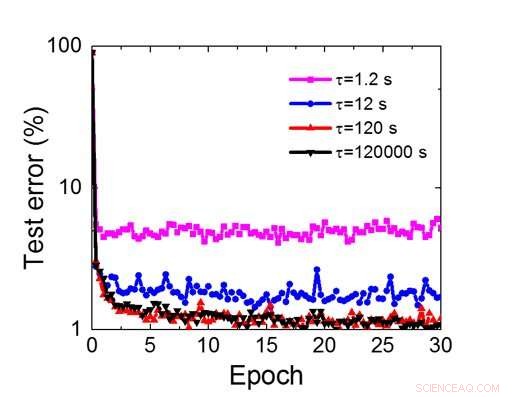
Figura 8. Requisito de tempo de retenção simulado para esta matriz baseada em capacitor para treinar a rede neural convolucional. Crédito:IBM
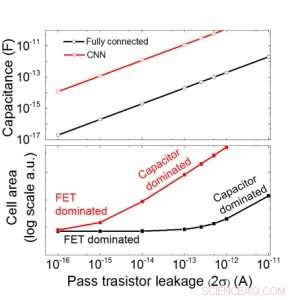
Figura 9. Escalabilidade desta matriz baseada em capacitor como uma função de vazamento para redes neurais totalmente conectadas e convolucionais. Crédito:IBM