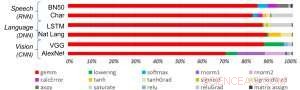
Figura 1. Algoritmos de aprendizado profundo são compostos por um espectro de operações. Embora a multiplicação da matriz seja dominante, otimizar a eficiência do desempenho enquanto mantém a precisão requer que a arquitetura central suporte de forma eficiente todas as funções auxiliares. Crédito:IBM
Avanços recentes em aprendizado profundo e crescimento exponencial no uso de aprendizado de máquina em domínios de aplicativos tornaram a aceleração de IA extremamente importante. A IBM Research está construindo um pipeline de aceleradores de hardware de IA para atender a essa necessidade. No Simpósio de Circuitos VLSI 2018, apresentamos um bloco de construção principal do acelerador multi-TeraOPS que pode ser dimensionado em uma ampla gama de sistemas de hardware de IA. Este núcleo de AI digital apresenta uma arquitetura paralela que garante uma utilização muito alta e mecanismos de computação eficientes que alavancam cuidadosamente a precisão reduzida.
A computação aproximada é um princípio central de nossa abordagem para aproveitar "a física da IA", em que ganhos de computação com alta eficiência energética são alcançados por arquiteturas construídas de propósito, inicialmente usando computações digitais e posteriormente incluindo computação analógica e in-memory.
Historicamente, a computação baseou-se na aritmética de ponto flutuante de 64 e 32 bits de alta precisão. Esta abordagem oferece cálculos precisos até a enésima casa decimal, um nível de precisão crítico para tarefas de computação científica, como simular o coração humano ou calcular trajetórias de ônibus espaciais. Mas precisamos desse nível de precisão para tarefas comuns de aprendizado profundo? Nosso cérebro requer uma imagem de alta resolução para reconhecer um membro da família, ou um gato? Quando entramos em um tópico de texto para pesquisa, exigimos precisão na classificação relativa dos 50, 002ª resposta mais útil vs 50, 003? A resposta é que muitas tarefas, incluindo esses exemplos, podem ser realizadas com computação aproximada.
Uma vez que a precisão total raramente é necessária para cargas de trabalho de aprendizado profundo comuns, a precisão reduzida é uma direção natural. Os blocos de construção computacional com motores de precisão de 16 bits são 4x menores do que blocos comparáveis com precisão de 32 bits; esse ganho na eficiência da área torna-se um aumento no desempenho e na eficiência energética tanto para treinamento de IA quanto para inferência de cargas de trabalho. Dito de forma simples, em computação aproximada, podemos trocar precisão numérica por eficiência computacional, desde que também desenvolvamos melhorias algorítmicas para manter a precisão do modelo. Esta abordagem também complementa outras técnicas de computação aproximadas, incluindo trabalhos recentes que descreveram novas abordagens de compressão de treinamento para reduzir a sobrecarga de comunicação, levando a uma aceleração de 40-200x em relação aos métodos existentes.
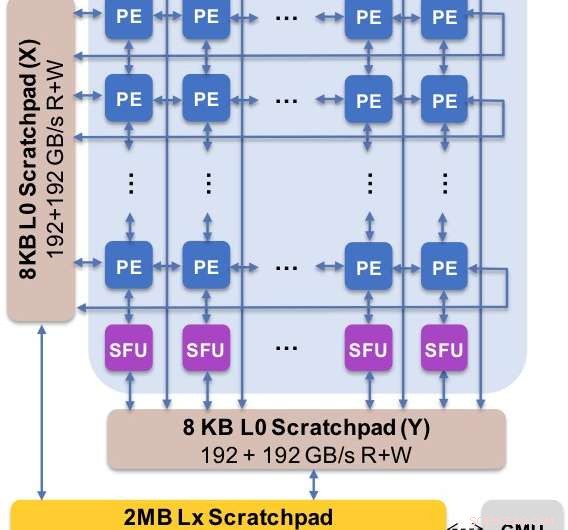
Figura 2. A arquitetura central captura o fluxo de dados customizado com hierarquia de rascunho. O elemento de processamento (PE) explora precisão reduzida para operações de multiplicação de matriz e algumas funções de ativação, enquanto as unidades de função especial (SFU) retêm a precisão de ponto flutuante de 32 bits para as operações de vetor restantes. Crédito:IBM
Apresentamos resultados experimentais de nosso núcleo digital de IA no Simpósio de Circuitos VLSI de 2018. O design de nosso novo núcleo foi regido por quatro objetivos:
Nossa nova arquitetura foi otimizada não apenas para multiplicação de matrizes e núcleos convolucionais, que tendem a dominar os cálculos de aprendizado profundo, mas também um espectro de funções de ativação que fazem parte da carga de trabalho computacional de aprendizado profundo. Além disso, nossa arquitetura oferece suporte para operações convolucionais nativas, permitindo treinamento de aprendizado profundo e tarefas de inferência em imagens e dados de fala para serem executados com eficiência excepcional no núcleo.
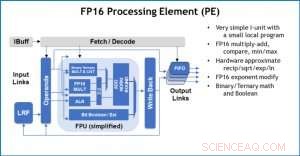
Figura 3. Elemento de processamento (PE) com recursos de ponto flutuante de 16 bits (FP16) para operações de multiplicação de matriz, matemática binária e ternária, funções de ativação e operações booleanas. Crédito:IBM
Como ilustração de como a arquitetura central foi otimizada para uma variedade de funções de aprendizado profundo, A Figura 1 mostra a divisão dos tipos de operação em algoritmos de aprendizado profundo em um espectro de domínios de aplicativo. Os componentes de multiplicação de matriz dominante são calculados na arquitetura central usando uma organização de fluxo de dados customizada dos Elementos de Processamento mostrados nas Figuras 2 e 3, onde cálculos de precisão reduzida podem ser explorados de forma eficiente, enquanto as funções vetoriais restantes (todas as barras não vermelhas na Figura 1) são executadas nos Elementos de Processamento ou nas Unidades de Função Especiais mostradas nas Figuras 3 ou 4, dependendo das necessidades de precisão da função específica.
No Simpósio, mostramos resultados de hardware confirmando que esta abordagem de arquitetura única é capaz de treinamento e inferência e oferece suporte a modelos em vários domínios (por exemplo, Fala, visão, processamento de linguagem natural). Enquanto outros grupos apontam para o "desempenho máximo" de seus chips especializados de IA, mas têm níveis de desempenho sustentados em uma pequena fração do pico, nos concentramos em maximizar o desempenho e a utilização sustentáveis, já que o desempenho sustentado se traduz diretamente na experiência do usuário e nos tempos de resposta.
Nosso chip de teste é mostrado na Figura 5. Usando este chip de teste, construído em tecnologia 14LPP, demonstramos com sucesso o treinamento e a inferência, em uma ampla biblioteca de aprendizado profundo, exercitar todas as operações comumente usadas em tarefas de aprendizagem profunda, incluindo multiplicações de matrizes, convoluções e várias funções de ativação não linear.
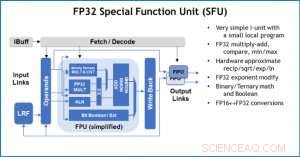
Figura 4. Unidade de função especial (SFU) com ponto flutuante de 32 bits (FP32) para determinados cálculos de vetor. Crédito:IBM
Destacamos a flexibilidade e capacidade multiuso do núcleo digital AI e suporte nativo para múltiplos fluxos de dados no papel VLSI, mas essa abordagem é totalmente modular. Este núcleo de IA pode ser integrado em SoCs, CPUs, ou microcontroladores e usados para treinamento, inferência, ou ambos. Os chips que usam o núcleo podem ser implantados no data center ou na extremidade.
Orientado por um entendimento fundamental de algoritmos de aprendizado profundo na IBM Research, Esperamos que os requisitos de precisão para treinamento e inferência continuem a crescer - o que conduzirá a melhorias de eficiência quântica nas arquiteturas de hardware necessárias para IA. Fique ligado para mais pesquisas de nossa equipe.
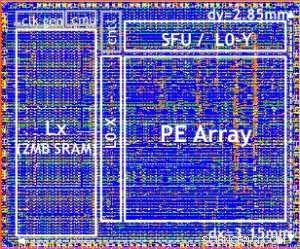
Figura 5. Chip de teste Digital AI Core, com base na tecnologia 14LPP, incluindo portas de 5,75M, 1,00 flip-flops, 16 KB L0 e 16 KB de registros locais PE. Este chip foi usado para demonstrar treinamento e inferência, across a wide range of AI workloads. Crédito:IBM














