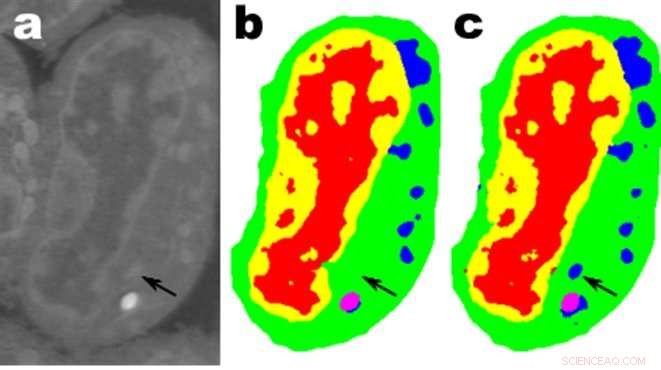
Imagens de uma fatia de células linfoblastóides de camundongo; uma. são os dados brutos, b é a segmentação manual correspondente ec é a saída de uma rede MS-D com 100 camadas. Crédito:Dados de A. Ekman e C. Larabell, Centro Nacional de Tomografia de Raios-X.
Matemáticos do Laboratório Nacional Lawrence Berkeley do Departamento de Energia (Berkeley Lab) desenvolveram uma nova abordagem de aprendizado de máquina voltada para dados de imagem experimental. Em vez de confiar nas dezenas ou centenas de milhares de imagens usadas por métodos típicos de aprendizado de máquina, esta nova abordagem "aprende" muito mais rapidamente e requer muito menos imagens.
Daniël Pelt e James Sethian, do Centro de Matemática Avançada para Aplicações de Pesquisa de Energia (CAMERA) do Berkeley Lab, mudaram a perspectiva do aprendizado de máquina usual desenvolvendo o que eles chamam de "Rede Neural de Convolução Densa de Escala Mista (MS-D)" que requer muito menos parâmetros do que os métodos tradicionais, converge rapidamente, e tem a capacidade de "aprender" com um conjunto de treinamento incrivelmente pequeno. A abordagem deles já está sendo usada para extrair estrutura biológica de imagens de células, e está preparada para fornecer uma nova ferramenta computacional importante para analisar dados em uma ampla gama de áreas de pesquisa.
Como as instalações experimentais geram imagens de alta resolução em velocidades mais altas, os cientistas podem se esforçar para gerenciar e analisar os dados resultantes, o que muitas vezes é feito cuidadosamente à mão. Em 2014, Sethian estabeleceu a CAMERA no Berkeley Lab como uma empresa integrada, centro interdisciplinar para desenvolver e entregar nova matemática fundamental necessária para capitalizar em investigações experimentais nas instalações do usuário do DOE Office of Science. CAMERA faz parte da Divisão de Pesquisa Computacional do laboratório.
"Em muitas aplicações científicas, um tremendo trabalho manual é necessário para anotar e marcar imagens - pode levar semanas para produzir um punhado de imagens cuidadosamente delineadas, "disse Sethian, que também é professor de matemática na Universidade da Califórnia, Berkeley. "Nosso objetivo era desenvolver uma técnica que aprenda com um conjunto de dados muito pequeno."
Os detalhes do algoritmo foram publicados em 26 de dezembro, 2017 em um artigo no Proceedings of the National Academy of Sciences .
"A descoberta resultou da compreensão de que a redução e a ampliação usuais de recursos de captura em várias escalas de imagem poderiam ser substituídas por convoluções matemáticas que lidam com várias escalas em uma única camada, "disse Pelt, que também é membro do Grupo de Imagens Computacionais do Centrum Wiskunde &Informatica, o instituto nacional de pesquisa para matemática e ciência da computação na Holanda.
Para tornar o algoritmo acessível a um amplo conjunto de pesquisadores, uma equipe de Berkeley liderada por Olivia Jain e Simon Mo construiu um portal da web "Segmenting Labeled Image Data Engine (SlideCAM)" como parte do conjunto de ferramentas CAMERA para instalações experimentais DOE.

Imagens tomográficas de um mini-compósito reforçado com fibra, reconstruída usando 1024 projeções (a) e 120 projeções (b). Em (c), a saída de uma rede MS-D com a imagem (b) como entrada é mostrada. Uma pequena região indicada por um quadrado vermelho é mostrada ampliada no canto inferior direito de cada imagem. Crédito:Daniël Pelt e James Sethian, Berkeley Lab
Uma aplicação promissora é a compreensão da estrutura interna das células biológicas e um projeto no qual o método MS-D de Pelt e Sethian precisava apenas de dados de sete células para determinar a estrutura celular.
"Em nosso laboratório, estamos trabalhando para entender como a estrutura e morfologia celular influencia ou controla o comportamento celular. Passamos incontáveis horas segmentando células manualmente para extrair estrutura, e identificar, por exemplo, diferenças entre células saudáveis e células doentes, "disse Carolyn Larabell, Diretor do Centro Nacional de Tomografia de Raios-X e Professor da Escola de Medicina da Universidade da Califórnia em São Francisco. "Esta nova abordagem tem o potencial de transformar radicalmente nossa capacidade de entender as doenças, e é uma ferramenta fundamental em nosso novo projeto patrocinado por Chan-Zuckerberg para estabelecer um Atlas de células humanas, uma colaboração global para mapear e caracterizar todas as células de um corpo humano saudável. "
Obtendo mais ciência com menos dados
As imagens estão por toda parte. Smartphones e sensores produziram um tesouro de fotos, muitos marcados com informações pertinentes que identificam o conteúdo. Usando este vasto banco de dados de imagens com referências cruzadas, As redes neurais convolucionais e outros métodos de aprendizado de máquina revolucionaram nossa capacidade de identificar rapidamente imagens naturais que se parecem com as vistas e catalogadas anteriormente.
Esses métodos "aprendem" ajustando um conjunto incrivelmente grande de parâmetros internos ocultos, guiado por milhões de imagens marcadas, e exigindo muito tempo do supercomputador. Mas e se você não tiver tantas imagens marcadas? Em muitos campos, tal banco de dados é um luxo inatingível. Os biólogos gravam imagens de células e delineiam meticulosamente as bordas e a estrutura à mão:não é incomum que uma pessoa passe semanas criando uma única imagem totalmente tridimensional. Os cientistas de materiais usam a reconstrução tomográfica para observar o interior de rochas e materiais, e, em seguida, arregaçar as mangas para rotular diferentes regiões, identificando rachaduras, fraturas, e vazios com a mão. Os contrastes entre estruturas diferentes, mas importantes, costumam ser muito pequenos e o "ruído" nos dados pode mascarar recursos e confundir o melhor dos algoritmos (e os humanos).
Essas imagens preciosas selecionadas à mão estão longe de ser suficientes para os métodos tradicionais de aprendizado de máquina. Para enfrentar este desafio, matemáticos da CAMERA atacaram o problema do aprendizado de máquina com quantidades muito limitadas de dados. Tentando fazer "mais com menos, "seu objetivo era descobrir como construir um conjunto eficiente de" operadores "matemáticos que pudesse reduzir muito o número de parâmetros. Esses operadores matemáticos podem naturalmente incorporar restrições-chave para ajudar na identificação, por exemplo, incluindo requisitos em formas e padrões cientificamente plausíveis.
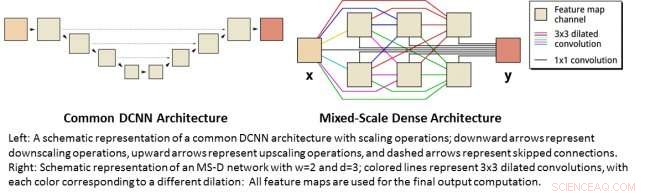
Esquerda:uma representação esquemática de uma arquitetura DCNN comum com operações de dimensionamento; setas para baixo representam operações de redução de escala, as setas para cima representam as operações de aumento e as setas tracejadas representam as conexões ignoradas. À direita:Representação esquemática de uma rede MS-D com w =2 e d =3; linhas coloridas representam convoluções dilatadas 3x3, com cada cor correspondendo a uma dilatação diferente:Todos os mapas de recursos são usados para o cálculo de saída final. Crédito:Daniël Pelt e James Sethian, Berkeley Lab
Redes Neurais de Convolução Densa em Escala Mista
Muitas aplicações de aprendizado de máquina para problemas de imagem usam redes neurais convolucionais profundas (DCNNs), em que a imagem de entrada e as imagens intermediárias são convolvidas em um grande número de camadas sucessivas, permitindo que a rede aprenda recursos altamente não lineares. Para obter resultados precisos para problemas difíceis de processamento de imagem, DCNNs normalmente dependem de combinações de operações e conexões adicionais, incluindo, por exemplo, operações de downscaling e upscaling para capturar recursos em várias escalas de imagem. Para treinar redes mais profundas e poderosas, tipos de camada e conexões adicionais são frequentemente necessários. Finalmente, DCNNs normalmente usam um grande número de imagens intermediárias e parâmetros treináveis, frequentemente mais de 100 milhões, para obter resultados para problemas difíceis.
Em vez de, a nova arquitetura de rede "Mixed-Scale Dense" evita muitas dessas complicações e calcula convoluções dilatadas como um substituto para operações de escalonamento para capturar recursos em vários intervalos espaciais, empregando várias escalas em uma única camada, e conectando densamente todas as imagens intermediárias. O novo algoritmo atinge resultados precisos com poucas imagens e parâmetros intermediários, eliminando a necessidade de ajustar hiperparâmetros e camadas ou conexões adicionais para permitir o treinamento.
Obtendo ciência de alta resolução a partir de dados de baixa resolução
Um desafio diferente é produzir imagens de alta resolução a partir de entrada de baixa resolução. Como qualquer pessoa que tentou ampliar uma foto pequena e descobriu que só fica pior à medida que fica maior, isso parece quase impossível. Mas um pequeno conjunto de imagens de treinamento processadas com uma rede densa de escala mista pode fornecer avanços reais. Como um exemplo, imagine tentar diminuir o ruído de reconstruções tomográficas de um minicomposto de material reforçado com fibra. Em um experimento descrito no artigo, as imagens foram reconstruídas usando 1, 024 adquiriu projeções de raios-X para obter imagens com quantidades relativamente baixas de ruído. Imagens ruidosas do mesmo objeto foram obtidas reconstruindo-se usando 128 projeções. As entradas de treinamento eram imagens barulhentas, com imagens sem ruído correspondentes usadas como saída de destino durante o treinamento. A rede treinada foi então capaz de efetivamente pegar dados de entrada com ruído e reconstruir imagens de resolução mais alta.
Novos aplicativos
Pelt e Sethian estão abordando uma série de novas áreas, como a análise rápida em tempo real de imagens provenientes de fontes de luz síncrotron e problemas de reconstrução na reconstrução biológica, como para células e mapeamento do cérebro.
"Essas novas abordagens são realmente empolgantes, uma vez que permitirão a aplicação de aprendizado de máquina a uma variedade muito maior de problemas de imagem do que é possível atualmente, "Pelt disse." Ao reduzir a quantidade de imagens de treinamento necessárias e aumentar o tamanho das imagens que podem ser processadas, a nova arquitetura pode ser usada para responder a questões importantes em muitos campos de pesquisa. "