Um milhão de processos são mapeados para os pixels de um esboço em preto e branco de 1000 × 1000 pixels de Alan Turing. Os pixels são ligados e desligados de acordo com os valores binários instantâneos dos processos. Crédito:Nature Communications
"Computação na memória" ou "memória computacional" é um conceito emergente que usa as propriedades físicas dos dispositivos de memória para armazenar e processar informações. Isso é contrário aos sistemas e dispositivos atuais de von Neumann, como computadores desktop padrão, laptops e até mesmo celulares, que transporta dados de um lado para outro entre a memória e a unidade de computação, tornando-os mais lentos e menos eficientes em termos de energia.
Hoje, A IBM Research está anunciando que seus cientistas demonstraram que um algoritmo de aprendizado de máquina não supervisionado, rodando em um milhão de dispositivos de memória de mudança de fase (PCM), encontrou correlações temporais com sucesso em fluxos de dados desconhecidos. Quando comparados a computadores clássicos de última geração, espera-se que esta tecnologia de protótipo produza melhorias 200x em velocidade e eficiência energética, tornando-o altamente adequado para permitir ultra-denso, baixo consumo de energia, e sistemas de computação massivamente paralelos para aplicações em IA.
Os pesquisadores usaram dispositivos PCM feitos de liga de telureto de germânio e antimônio, que é empilhado e ensanduichado entre dois eletrodos. Quando os cientistas aplicam uma minúscula corrente elétrica ao material, eles aquecem, que altera seu estado de amorfo (com um arranjo atômico desordenado) para cristalino (com uma configuração atômica ordenada). Os pesquisadores da IBM usaram a dinâmica de cristalização para realizar cálculos no local.
"Este é um passo importante em nossa pesquisa da física da IA, que explora novos materiais de hardware, dispositivos e arquiteturas, "diz o Dr. Evangelos Eleftheriou, um IBM Fellow e co-autor do artigo. "À medida que as leis de escala do CMOS são quebradas devido aos limites tecnológicos, um afastamento radical da dicotomia processador-memória é necessário para contornar as limitações dos computadores de hoje. Dada a simplicidade, alta velocidade e baixa energia de nossa abordagem de computação in-memory, é notável que nossos resultados sejam tão semelhantes à nossa abordagem clássica de referência executada em um computador Von Neumann. "
Os detalhes são explicados em seu artigo publicado hoje no jornal de revisão por pares Nature Communications . Para demonstrar a tecnologia, os autores escolheram dois exemplos baseados em tempo e compararam seus resultados com métodos tradicionais de aprendizado de máquina, como cluster k-means:
"Até agora, a memória tem sido vista como um lugar onde simplesmente armazenamos informações. Mas, neste trabalho, nós mostramos conclusivamente como podemos explorar a física desses dispositivos de memória para também realizar um primitivo computacional de alto nível. O resultado da computação também é armazenado nos dispositivos de memória, e, nesse sentido, o conceito é vagamente inspirado em como o cérebro calcula ", disse o Dr. Abu Sebastian, memória exploratória e cientista de tecnologias cognitivas, IBM Research e principal autor do artigo.
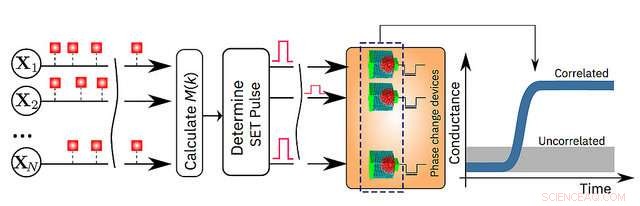
Uma ilustração esquemática do algoritmo de computação em memória. Crédito:IBM Research