Partículas emergindo de colisões de prótons no Grande Colisor de Hádrons do CERN viajam através deste instrumento de muitas camadas, o detector CMS. Em 2026, o LHC produzirá 20 vezes os dados que produz atualmente, e o CMS está atualmente passando por atualizações para ler e processar o dilúvio de dados. Crédito:Maximilien Brice, CERN
Cada colisão de prótons no Grande Colisor de Hádrons é diferente, mas apenas alguns são especiais. As colisões especiais geram partículas em padrões incomuns - possíveis manifestações de novos, quebra de regras da física - ou ajuda a preencher nossa imagem incompleta do universo.
Encontrar essas colisões é mais difícil do que a proverbial busca pela agulha no palheiro. Mas a ajuda para mudar o jogo está a caminho. Os cientistas do Fermilab e outros colaboradores testaram com sucesso um protótipo de tecnologia de aprendizado de máquina que acelera o processamento em 30 a 175 vezes em comparação com os métodos tradicionais.
Enfrentando 40 milhões de colisões a cada segundo, os cientistas do LHC usam poderosos, computadores ágeis para colher as joias - seja uma partícula de Higgs ou indícios de matéria escura - da vasta estática das colisões comuns.
Vasculhando os dados simulados de colisão do LHC, a tecnologia de aprendizado de máquina aprendeu com sucesso a identificar um padrão de pós-colisão específico - um spray específico de partículas voando através de um detector - conforme ele passava por impressionantes 600 imagens por segundo. Os métodos tradicionais processam menos de uma imagem por segundo.
A tecnologia pode até ser oferecida como um serviço em computadores externos. Usar este modelo de descarregamento permitiria aos pesquisadores analisar mais dados mais rapidamente e deixar mais espaço de computação do LHC disponível para fazer outro trabalho.
É um vislumbre promissor de como os serviços de aprendizado de máquina estão apoiando um campo no qual enormes quantidades de dados só vão aumentar.
O desafio:mais dados, mais poder de computação
Os pesquisadores estão atualmente atualizando o LHC para destruir prótons a uma taxa cinco vezes maior que a atual. Em 2026, a máquina subterrânea circular de 17 milhas no laboratório europeu CERN produzirá 20 vezes mais dados do que agora.
CMS é um dos detectores de partículas do Large Hadron Collider, e os colaboradores do CMS estão passando por algumas atualizações próprias, permitindo o intrincado, instrumento de histórias para tirar fotos mais sofisticadas das colisões de partículas do LHC. O Fermilab é o laboratório líder nos EUA para o experimento CMS.
Se os cientistas do LHC quisessem salvar todos os dados brutos de colisão que coletariam em um ano do LHC de alta luminosidade, eles teriam que encontrar uma maneira de armazenar cerca de 1 exabyte (cerca de 1 trilhão de discos rígidos externos pessoais), dos quais apenas uma lasca pode revelar novos fenômenos. Os computadores do LHC são programados para selecionar esta pequena fração, tomar decisões em frações de segundo sobre quais dados são valiosos o suficiente para serem enviados para um estudo posterior.
Atualmente, o sistema de computação do LHC mantém cerca de um em cada 100, 000 eventos de partículas. Mas os protocolos de armazenamento atuais não serão capazes de acompanhar a futura inundação de dados, que vai se acumular ao longo de décadas de coleta de dados. E as imagens de alta resolução capturadas pelo detector CMS atualizado não tornarão o trabalho mais fácil. Tudo isso se traduz na necessidade de mais de 10 vezes mais recursos de computação do que o LHC agora.

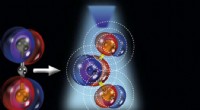
Os físicos de partículas estão explorando o uso de computadores com recursos de aprendizado de máquina para processar imagens de colisões de partículas no CMS, ensinando-os a identificar rapidamente vários padrões de colisão. Crédito:Eamonn Maguire / Antarctic Design
O recente teste de protótipo mostra que, com avanços em aprendizado de máquina e hardware de computação, os pesquisadores esperam poder filtrar os dados emergentes do próximo High-Luminosity LHC quando estiver online.
"A esperança aqui é que você possa fazer coisas muito sofisticadas com o aprendizado de máquina e também mais rápido, "disse Nhan Tran, um cientista do Fermilab no experimento CMS e um dos líderes no teste recente. "Isso é importante, uma vez que nossos dados ficarão cada vez mais complexos com detectores atualizados e ambientes de colisão mais ocupados. "
Aprendizado de máquina para o resgate:a diferença de inferência
O aprendizado de máquina em física de partículas não é novo. Os físicos usam o aprendizado de máquina para cada estágio do processamento de dados em um experimento de colisor.
Mas com a tecnologia de aprendizado de máquina que pode mastigar os dados do LHC até 175 vezes mais rápido do que os métodos tradicionais, os físicos de partículas estão subindo um degrau revolucionário no curso de computação de colisão.
As taxas rápidas são graças ao hardware habilmente projetado na plataforma, Azure ML da Microsoft, o que acelera um processo chamado inferência.
Para entender a inferência, Considere um algoritmo que foi treinado para reconhecer a imagem de uma motocicleta:o objeto tem duas rodas e duas alças presas a um corpo de metal maior. O algoritmo é inteligente o suficiente para saber que um carrinho de mão, que tem atributos semelhantes, não é uma motocicleta. À medida que o sistema varre novas imagens de outras rodas, objetos de duas mãos, ele prevê - ou infere - quais são as motocicletas. E à medida que os erros de previsão do algoritmo são corrigidos, torna-se bastante hábil em identificá-los. Um bilhão de varreduras depois, está em seu jogo de inferência.
A maioria das plataformas de aprendizado de máquina são construídas para entender como classificar imagens, mas não imagens específicas da física. Os físicos têm que ensinar-lhes a parte da física, como o reconhecimento de trilhas criadas pelo bóson de Higgs ou a busca por indícios de matéria escura.
Pesquisadores do Fermilab, CERN, MIT, a Universidade de Washington e outros colaboradores treinaram o Azure ML para identificar imagens de quarks top - uma partícula elementar de vida curta que é cerca de 180 vezes mais pesada que um próton - a partir de dados simulados de CMS. Especificamente, Azure deveria procurar imagens dos principais jatos de quark, nuvens de partículas retiradas do vácuo por um único quark top zinging longe da colisão.
"Enviamos as imagens, treiná-lo em dados de física, "disse o cientista do Fermilab Burt Holzman, uma liderança no projeto. "E exibiu um desempenho de última geração. Foi muito rápido. Isso significa que podemos canalizar um grande número dessas coisas. Em geral, essas técnicas são muito boas. "
Uma das técnicas por trás da aceleração de inferência é combinar processadores tradicionais com especializados, um casamento conhecido como arquitetura de computação heterogênea.

Os dados de experimentos de física de partículas são armazenados em fazendas de computação como esta, o Grid Computing Center do Fermilab. Organizações externas oferecem suas fazendas de computação como um serviço para experimentos de física de partículas, disponibilizando mais espaço nos servidores dos experimentos. Crédito:Reidar Hahn
Plataformas diferentes usam arquiteturas diferentes. Os processadores tradicionais são CPUs (unidades de processamento central). Os processadores especializados mais conhecidos são GPUs (unidades de processamento gráfico) e FPGAs (matrizes de portas programáveis em campo). O Azure ML combina CPUs e FPGAs.
"A razão pela qual esses processos precisam ser acelerados é que se trata de grandes cálculos. Você está falando de 25 bilhões de operações, "Tran disse." Colocando isso em um FPGA, mapeando isso, e fazê-lo em um período de tempo razoável é uma verdadeira conquista. "
E está começando a ser oferecido como um serviço, também. O teste foi a primeira vez que alguém demonstrou como esse tipo de heterogêneo, a arquitetura como serviço pode ser usada para física fundamental.
No mundo da computação, usar algo "como serviço" tem um significado específico. Uma organização externa fornece recursos - aprendizado de máquina ou hardware - como um serviço, e os usuários - cientistas - utilizam esses recursos quando necessário. É semelhante a como sua empresa de streaming de vídeo fornece horas de TV como um serviço. Você não precisa ter seus próprios DVDs e DVD player. Em vez disso, você usa a biblioteca e a interface deles.
Os dados do Large Hadron Collider são normalmente armazenados e processados em servidores de computador no CERN e em instituições parceiras, como o Fermilab. Com o aprendizado de máquina oferecido tão facilmente quanto qualquer outro serviço da web, cálculos intensivos podem ser realizados em qualquer lugar em que o serviço seja oferecido - incluindo fora do local. Isso reforça as capacidades dos laboratórios com poder de computação e recursos adicionais, evitando que tenham que fornecer seus próprios servidores.
"A ideia de fazer computação acelerada existe há décadas, mas o modelo tradicional era comprar um cluster de computador com GPUs e instalá-lo localmente no laboratório, "Holzman disse." A ideia de transferir o trabalho para uma fazenda fora do local com hardware especializado, fornecendo aprendizado de máquina como um serviço, que funcionou conforme anunciado. "
O farm do Azure ML está na Virgínia. Leva apenas 100 milissegundos para computadores no Fermilab perto de Chicago, Illinois, para enviar uma imagem de um evento de partícula para a nuvem Azure, processe, e devolvê-lo. Isso é um 2, 500 quilômetros, viagem densa de dados em um piscar de olhos.
"O encanamento que acompanha tudo isso é outra conquista, "Tran disse." O conceito de abstrair esses dados como uma coisa que você acabou de enviar para outro lugar, e simplesmente volta, foi a coisa mais agradavelmente surpreendente sobre este projeto. Não precisamos substituir tudo em nosso próprio centro de computação por um monte de coisas novas. Nós mantemos tudo isso, envie os cálculos difíceis e faça com que volte mais tarde. "
Os cientistas estão ansiosos para expandir a tecnologia para enfrentar outros desafios de big data no LHC. Eles também planejam testar outras plataformas, como Amazon AWS, Google Cloud e IBM Cloud, à medida que exploram o que mais pode ser realizado por meio do aprendizado de máquina, que teve uma evolução rápida nos últimos anos.
"Os modelos de última geração em 2015 são padrão hoje, "Tran disse.
Como uma ferramenta, o aprendizado de máquina continua a dar à física de partículas novas maneiras de vislumbrar o universo. Também é impressionante por si só.
"Que podemos pegar algo que é treinado para discriminar entre fotos de animais e pessoas, fazer alguns cálculos de quantias modestas, e ele me diz a diferença entre um jato de quark superior e o plano de fundo? ", disse Holzman." Isso é algo que me deixa espantado. "