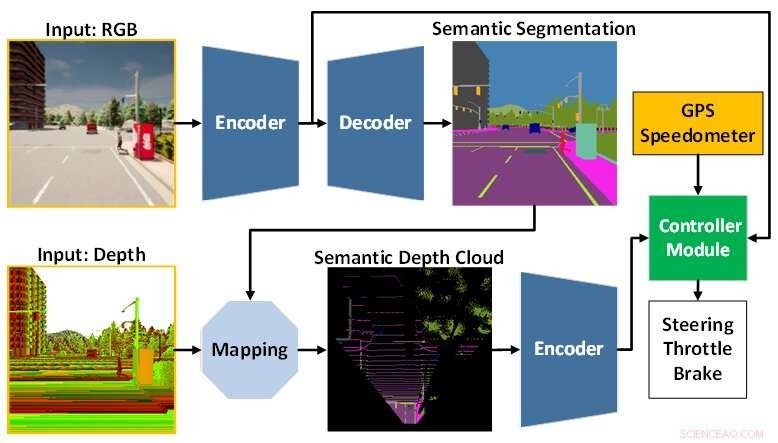
A arquitetura do modelo de IA é composta pelo módulo de percepção (azul) e pelo módulo controlador (verde). O módulo de percepção é responsável por perceber o ambiente com base nos dados de observação fornecidos por uma câmera RGBD. Enquanto isso, o módulo controlador é responsável por decodificar as informações extraídas para estimar o grau de direção, aceleração e frenagem. Crédito:Universidade de Tecnologia de Toyohashi
Uma equipe de pesquisa composta por Oskar Natan, Ph.D. estudante e seu supervisor, o professor Jun Miura, afiliado ao Laboratório de Sistemas Inteligentes Ativos (AISL), Departamento de Engenharia de Ciência da Computação da Universidade de Tecnologia de Toyohashi, desenvolveu um modelo de IA que pode lidar com percepção e controle simultaneamente para uma condução autônoma veículo.
O modelo de IA percebe o ambiente concluindo várias tarefas de visão enquanto dirige o veículo seguindo uma sequência de pontos de rota. Além disso, o modelo de IA pode conduzir o veículo com segurança em diversas condições ambientais em vários cenários. Avaliado em tarefas de navegação ponto a ponto, o modelo de IA alcança a melhor dirigibilidade de determinados modelos recentes em um ambiente de simulação padrão.
A direção autônoma é um sistema complexo que consiste em vários subsistemas que lidam com múltiplas tarefas de percepção e controle. No entanto, a implantação de vários módulos específicos de tarefas é cara e ineficiente, pois ainda são necessárias várias configurações para formar um sistema modular integrado.
Além disso, o processo de integração pode levar à perda de informações, pois muitos parâmetros são ajustados manualmente. Com a pesquisa rápida de aprendizado profundo, esse problema pode ser resolvido treinando um único modelo de IA com maneiras de ponta a ponta e multitarefa. Assim, o modelo pode fornecer controles de navegação apenas com base nas observações fornecidas por um conjunto de sensores. Como a configuração manual não é mais necessária, o modelo pode gerenciar as informações sozinho.
O desafio que permanece para um modelo de ponta a ponta é como extrair informações úteis para que o controlador possa estimar os controles de navegação adequadamente. Isso pode ser resolvido fornecendo muitos dados ao módulo de percepção para melhor perceber o ambiente ao redor. Além disso, uma técnica de fusão de sensores pode ser usada para melhorar o desempenho, pois funde diferentes sensores para capturar vários aspectos dos dados.
No entanto, uma enorme carga de computação é inevitável, pois é necessário um modelo maior para processar mais dados. Além disso, uma técnica de pré-processamento de dados é necessária, pois sensores variados geralmente vêm com diferentes modalidades de dados. Além disso, o aprendizado de desequilíbrio durante o processo de treinamento pode ser outro problema, pois o modelo executa tarefas de percepção e controle simultaneamente.

Alguns registros de condução feitos pelo modelo AI. Colunas (da esquerda para a direita):imagem colorida, imagem de profundidade, resultado da segmentação semântica, mapa Birds-eye-view (BEV), comando de controle. O tempo e a hora para cada cena são os seguintes:(1) meio-dia claro, (2) pôr do sol nublado, (3) meio-dia chuvoso, (4) pôr do sol com chuva forte, (5) pôr do sol úmido. Crédito:Universidade de Tecnologia de Toyohashi
Para responder a esses desafios, a equipe propõe um modelo de IA treinado com modos de ponta a ponta e multitarefa. O modelo é constituído por dois módulos principais, nomeadamente módulos de percepção e controladores. A fase de percepção começa pelo processamento de imagens RGB e mapas de profundidade fornecidos por uma única câmera RGBD.
Em seguida, as informações extraídas do módulo de percepção, juntamente com a medição da velocidade do veículo e as coordenadas do ponto de rota, são decodificadas pelo módulo controlador para estimar os controles de navegação. Para garantir que todas as tarefas possam ser executadas igualmente, a equipe emprega um algoritmo chamado de normalização de gradiente modificado (MGN) para equilibrar o sinal de aprendizado durante o processo de treinamento.
A equipe considera o aprendizado por imitação, pois permite que o modelo aprenda com um conjunto de dados em grande escala para corresponder a um padrão quase humano. Além disso, a equipe projetou o modelo para usar um número menor de parâmetros do que outros para reduzir a carga computacional e acelerar a inferência em um dispositivo com recursos limitados.
Com base no resultado experimental em um simulador de condução autônomo padrão, CARLA, é revelado que a fusão de imagens RGB e mapas de profundidade para formar um mapa semântico de visão panorâmica (BEV) pode aumentar o desempenho geral. Como o módulo de percepção tem uma melhor compreensão geral da cena, o módulo controlador pode alavancar informações úteis para estimar os controles de navegação adequadamente. Além disso, a equipe afirma que o modelo proposto é preferível para implantação, pois alcança melhor dirigibilidade com menos parâmetros do que outros modelos.
A pesquisa foi publicada em
IEEE Transactions on Intelligent Vehicles , e a equipe está atualmente trabalhando em modificações e melhorias no modelo para resolver vários problemas ao dirigir em condições de pouca iluminação, como à noite, sob chuva forte, etc. Como hipótese, a equipe acredita que adicionar um sensor que não é afetado por mudanças no brilho ou iluminação, como o LiDAR, melhorará os recursos de compreensão da cena do modelo e resultará em melhor dirigibilidade. Outra tarefa futura é aplicar o modelo proposto à condução autônoma no mundo real.
+ Explorar mais Novo modelo de base melhora a precisão para interpretação de imagens de sensoriamento remoto