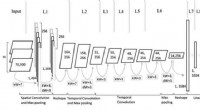
Crédito:arXiv:2002.08550 [cs.RO]
O campo da robótica deu um passo à frente, seguido por outro, depois, vários outros - quando um robô chamado Rainbow Dash recentemente aprendeu a andar. A máquina de quatro patas levou apenas algumas horas para aprender a andar para trás e para frente, e vire à direita e à esquerda ao fazer isso.
Pesquisadores do Google, A UC Berkeley e o Instituto de Tecnologia da Geórgia publicaram um artigo no servidor de pré-impressão ArXiv descrevendo uma técnica de IA estatística conhecida como aprendizado de reforço profundo que eles usaram para produzir essa realização, o que é significativo por várias razões.
A maioria das implantações de aprendizado por reforço ocorre em ambientes simulados por computador. Linha do arco-íris, Contudo, usou essa tecnologia para aprender a andar em um ambiente físico real.
Além disso, foi capaz de fazer isso sem um mecanismo de ensino dedicado, como instrutores humanos ou dados de treinamento rotulados. Finalmente, Rainbow Dash conseguiu andar em várias superfícies, incluindo um colchão de espuma macia e um capacho com reentrâncias bastante notáveis.
As técnicas de aprendizado por reforço profundo utilizadas pelo robô compreendem um tipo de aprendizado de máquina em que um agente interage com um ambiente para aprender por tentativa e erro. A maioria dos casos de uso de aprendizado por reforço envolve jogos computadorizados nos quais os agentes digitais aprendem a jogar para ganhar.
Esta forma de aprendizado de máquina é muito diferente do aprendizado tradicional supervisionado ou não supervisionado, em que os modelos de aprendizado de máquina exigem dados de treinamento rotulados para aprender. Aprendizagem por reforço profundo combina abordagens de aprendizagem por reforço com aprendizagem profunda, em que a escala do aprendizado de máquina tradicional é amplamente expandida com grande poder computacional.
Embora a equipe de pesquisa tenha creditado ao Rainbow Dash o aprendizado de andar sozinho, a intervenção humana ainda desempenhou um papel importante para atingir esse objetivo. Os pesquisadores tiveram que criar limites dentro dos quais o robô aprendeu a andar para evitar que ele deixasse a área.
Eles também tiveram que desenvolver algoritmos específicos para evitar que o robô caísse, alguns dos quais se concentraram em restringir o movimento do robô. Para evitar acidentes, como danos por queda, o aprendizado por reforço de robótica geralmente ocorre em um ambiente digital antes que os algoritmos sejam transferidos para um robô físico, a fim de preservar sua segurança.
O triunfo do Rainbow Dash ocorre aproximadamente um ano depois que os pesquisadores descobriram inicialmente como fazer os robôs aprenderem fisicamente, em oposição ao virtual, arredores.
Chelsea Finn, um professor assistente de Stanford associado ao Google que não participou da pesquisa, diz, “Remover a pessoa do processo [de aprendizagem] é muito difícil. Ao permitir que os robôs aprendam de forma mais autônoma, os robôs estão mais perto de aprender no mundo real em que vivemos. "
© 2020 Science X Network