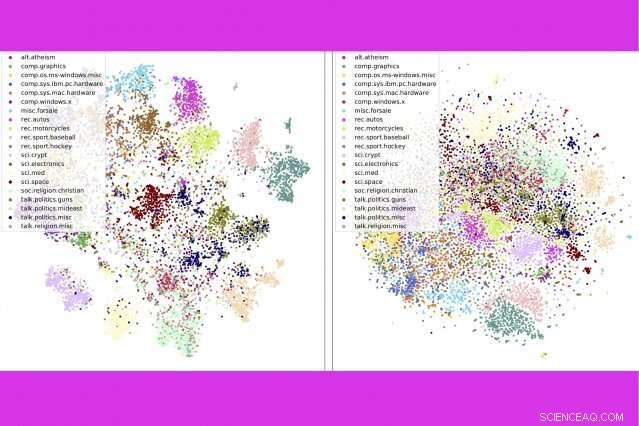
Em um novo estudo, pesquisadores do MIT e da IBM combinam três ferramentas populares de análise de texto - modelagem de tópicos, embeddings de palavras, e transporte ideal - para comparar milhares de documentos por segundo. Aqui, eles mostram que seu método (à esquerda) agrupa as postagens do newsgroup por categoria de forma mais precisa do que um método concorrente. Crédito:Massachusetts Institute of Technology
Com bilhões de livros, histórias de notícias, e documentos online, nunca houve um momento melhor para ler - se você tiver tempo para peneirar todas as opções. "Há uma tonelada de texto na internet, "diz Justin Solomon, professor assistente do MIT. "Qualquer coisa para ajudar a cortar todo esse material é extremamente útil."
Com o MIT-IBM Watson AI Lab e seu Grupo de Processamento de Dados Geométricos no MIT, Solomon apresentou recentemente uma nova técnica para cortar grandes quantidades de texto na Conferência sobre Sistemas de Processamento de Informação Neural (NeurIPS). Seu método combina três ferramentas populares de análise de texto - modelagem de tópicos, embeddings de palavras, e transporte ideal - para entregar melhor, resultados mais rápidos do que métodos concorrentes em um benchmark popular para classificação de documentos.
Se um algoritmo sabe do que você gostou no passado, ele pode examinar os milhões de possibilidades de algo semelhante. À medida que as técnicas de processamento de linguagem natural melhoram, aquelas sugestões do tipo "talvez você também goste" estão ficando mais rápidas e relevantes.
No método apresentado no NeurIPS, um algoritmo resume uma coleção de, dizer, livros, em tópicos com base em palavras comumente usadas na coleção. Em seguida, divide cada livro em seus cinco a 15 tópicos mais importantes, com uma estimativa de quanto cada tópico contribui para o livro como um todo.
Para comparar livros, os pesquisadores usam duas outras ferramentas:embeddings de palavras, uma técnica que transforma palavras em listas de números para refletir sua semelhança no uso popular, e transporte ideal, uma estrutura para calcular a maneira mais eficiente de mover objetos - ou pontos de dados - entre vários destinos.
Os embeddings de palavras permitem aproveitar o transporte ideal duas vezes:primeiro, para comparar os tópicos da coleção como um todo, e então, dentro de qualquer par de livros, para medir a proximidade da sobreposição de temas comuns.
A técnica funciona especialmente bem ao digitalizar grandes coleções de livros e documentos extensos. No estudo, os pesquisadores oferecem o exemplo de "The Great War Syndicate, de Frank Stockton, "um romance americano do século 19 que antecipou o surgimento das armas nucleares. Se você está procurando um livro semelhante, um modelo de tópico ajudaria a identificar os temas dominantes compartilhados com outros livros - neste caso, náutico, elementar, e marcial.
Mas um modelo de tópico sozinho não identificaria a palestra de Thomas Huxley de 1863, "The Past Condition of Organic Nature, "como uma boa combinação. O escritor foi um campeão da teoria da evolução de Charles Darwin, e sua palestra, salpicado de menções a fósseis e sedimentação, refletiu ideias emergentes sobre geologia. Quando os temas da palestra de Huxley são combinados com o romance de Stockton por meio de transporte ideal, alguns motivos transversais emergem:a geografia de Huxley, flora / fauna, e os temas do conhecimento são próximos aos náuticos de Stockton, elementar, e temas marciais, respectivamente.
Modelos de livros por seus tópicos representativos, ao invés de palavras individuais, torna possíveis comparações de alto nível. "Se você pedir a alguém para comparar dois livros, eles dividem cada um em conceitos fáceis de entender, e depois compare os conceitos, "diz o autor principal do estudo, Mikhail Yurochkin, pesquisador da IBM.
O resultado é mais rápido, comparações mais precisas, o estudo mostra. Os pesquisadores compararam 1, 720 pares de livros no conjunto de dados do Projeto Gutenberg em um segundo - mais de 800 vezes mais rápido que o próximo melhor método.
A técnica também faz um trabalho melhor de classificar documentos com precisão do que métodos rivais - por exemplo, agrupar livros no conjunto de dados de Gutenberg por autor, análises de produtos na Amazon por departamento, e as histórias de esportes da BBC por esporte. Em uma série de visualizações, os autores mostram que seu método agrupa ordenadamente os documentos por tipo.
Além de categorizar documentos com mais rapidez e precisão, o método oferece uma janela para o processo de tomada de decisão do modelo. Por meio da lista de tópicos que aparecem, os usuários podem ver porque o modelo está recomendando um documento.
Esta história foi republicada por cortesia do MIT News (web.mit.edu/newsoffice/), um site popular que cobre notícias sobre pesquisas do MIT, inovação e ensino.