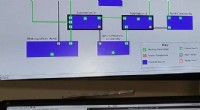
Crédito:Matti Ahlgren, Aalto University
Se os profissionais de saúde pudessem prever com precisão como seus serviços seriam usados, eles poderiam economizar grandes somas de dinheiro por não terem que alocar fundos desnecessariamente. Modelos de inteligência artificial de aprendizado profundo podem ser bons para prever o futuro, dado o comportamento anterior, e pesquisadores sediados na Finlândia desenvolveram um que pode prever quando e por que os idosos usarão os serviços de saúde.
Pesquisadores do Centro Finlandês de Inteligência Artificial (FCAI), Aalto University, a Universidade de Helsinque, e o Instituto Finlandês de Saúde e Bem-Estar (THL) desenvolveu um modelo de ajuste de risco para prever com que frequência os idosos procuram tratamento em um centro de saúde ou hospital. Os resultados sugerem que o novo modelo é mais preciso do que os modelos de regressão tradicionais comumente usados para esta tarefa, e pode prever com segurança como a situação muda ao longo dos anos.
Os modelos de ajuste de risco usam dados de anos anteriores, e são usados para alocar fundos de saúde de forma justa e eficaz. Esses modelos já são usados em países como a Alemanha, Os Países Baixos, e os EUA. Contudo, esta é a primeira prova de conceito de que as redes neurais profundas têm o potencial de melhorar significativamente a precisão de tais modelos.
“Sem um modelo de ajuste de risco, profissionais de saúde cujos pacientes estão doentes com mais frequência do que a média das pessoas seriam tratados de forma injusta, "Pekka Marttinen, Professor assistente na Aalto University e FCAI diz. Os idosos são um bom exemplo desse grupo de pacientes. O objetivo do modelo é levar essas diferenças entre os grupos de pacientes em consideração ao tomar decisões de financiamento.
De acordo com Yogesh Kumar, o principal autor do artigo de pesquisa e doutorando na Aalto University e FCAI, os resultados mostram que o aprendizado profundo pode ajudar a projetar modelos de ajuste de risco mais precisos e confiáveis. "Ter um modelo preciso tem o potencial de economizar vários milhões de dólares, "Kumar aponta.
Os pesquisadores treinaram o modelo usando dados do Registro de Visitas de Atenção Primária à Saúde do THL. Os dados consistem em informações de visitas ambulatoriais para cada cidadão finlandês com 65 anos ou mais. Os dados foram pseudonimizados, o que significa que as pessoas individuais não podem ser identificadas. Esta foi a primeira vez que os pesquisadores usaram esse banco de dados para treinar um modelo de aprendizado de máquina profundo.
Os resultados mostram que treinar um modelo profundo não requer necessariamente um enorme conjunto de dados para produzir resultados confiáveis. Em vez de, o novo modelo funcionou melhor do que o mais simples, modelos baseados em contagem, mesmo quando fazia uso de apenas um décimo de todos os dados disponíveis. Em outras palavras, fornece previsões precisas, mesmo com um conjunto de dados relativamente pequeno, que é uma descoberta notável, pois adquirir grandes quantidades de dados médicos é sempre difícil.
"Nosso objetivo não é colocar o modelo desenvolvido nesta pesquisa em prática como tal, mas integrar recursos de modelos de aprendizagem profunda aos modelos existentes, combinando os melhores lados de ambos. No futuro, o objetivo é fazer uso desses modelos para apoiar a tomada de decisões e alocar recursos de forma mais razoável, "explica Marttinen.
As implicações desta pesquisa não se limitam a prever com que frequência os idosos visitam um centro de saúde ou hospital. Em vez de, de acordo com Kumar, o trabalho dos pesquisadores pode ser facilmente estendido de muitas maneiras, por exemplo, concentrando-se apenas em grupos de pacientes diagnosticados com doenças que requerem tratamentos altamente caros ou centros de saúde em locais específicos em todo o país.
Os resultados da pesquisa foram publicados na série de publicações científicas de Proceedings of Machine Learning Research .