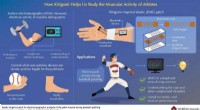
O sinal foi modificado para mudar seu significado para sistemas baseados em visão de computador de "Pare" para "Trabalho na estrada à frente". Crédito:David Kelly Crow
A capacidade das máquinas de aprender por meio do processamento de dados coletados de sensores é a base de veículos automatizados, dispositivos médicos e uma série de outras tecnologias emergentes. Mas essa capacidade de aprendizado deixa os sistemas vulneráveis a hackers de maneiras inesperadas, pesquisadores da Universidade de Princeton descobriram.
Em uma série de artigos recentes, uma equipe de pesquisa explorou como as táticas adversárias aplicadas à inteligência artificial (IA) poderiam, por exemplo, enganar um sistema de eficiência de tráfego para causar congestionamento ou manipular um aplicativo de IA relacionado à saúde para revelar o histórico médico particular dos pacientes. Como exemplo de um desses ataques, a equipe alterou a percepção de um robô dirigindo de um sinal de trânsito de um limite de velocidade para um sinal de "Pare", o que poderia fazer com que o veículo pise perigosamente nos freios em velocidades de rodovia; em outros exemplos, eles alteraram os sinais de parada para serem percebidos como uma variedade de outras instruções de tráfego.
"Se o aprendizado de máquina é o software do futuro, estamos em um ponto de partida muito básico para protegê-lo, "disse Prateek Mittal, o pesquisador principal e professor associado do Departamento de Engenharia Elétrica de Princeton. "Para que as tecnologias de aprendizado de máquina alcancem todo o seu potencial, temos que entender como o aprendizado de máquina funciona na presença de adversários. É aí que temos um grande desafio.
Assim como o software está sujeito a ser hackeado e infectado por vírus de computador, ou seus usuários alvo de golpistas por meio de phishing e outras manobras de violação de segurança, Os aplicativos com tecnologia de IA têm suas próprias vulnerabilidades. No entanto, a implantação de salvaguardas adequadas tem demorado. Até aqui, a maior parte do desenvolvimento de aprendizado de máquina ocorreu de forma benigna, ambientes fechados - um ambiente radicalmente diferente do mundo real.
Mittal é pioneira na compreensão de uma vulnerabilidade emergente conhecida como aprendizado de máquina adversário. Em essência, este tipo de ataque faz com que os sistemas de IA produzam não intencionais, resultados possivelmente perigosos por corromper o processo de aprendizagem. Em sua recente série de artigos, O grupo de Mittal descreveu e demonstrou três grandes tipos de ataques adversários de aprendizado de máquina.
Envenenando bem os dados
O primeiro ataque envolve um agente malévolo que insere informações falsas no fluxo de dados que um sistema de IA está usando para aprender - uma abordagem conhecida como envenenamento de dados. Um exemplo comum é um grande número de telefones de usuários relatando as condições do tráfego. Esses dados crowdsourced podem ser usados para treinar um sistema de IA para desenvolver modelos para melhor roteamento coletivo de carros autônomos, reduzindo o congestionamento e desperdício de combustível.
"Um adversário pode simplesmente injetar dados falsos na comunicação entre o telefone e entidades como a Apple e o Google, e agora seus modelos podem estar comprometidos, "disse Mittal." Tudo o que você aprender com dados corrompidos será suspeito.
O grupo de Mittal demonstrou recentemente uma espécie de subida de nível a partir deste envenenamento de dados simples, uma abordagem que eles chamam de "envenenamento modelo". Em AI, um "modelo" pode ser um conjunto de ideias que uma máquina formou, com base em sua análise de dados, sobre como alguma parte do mundo funciona. Por questões de privacidade, o telefone celular de uma pessoa pode gerar seu próprio modelo localizado, permitindo que os dados do indivíduo sejam mantidos em sigilo. Os modelos anônimos são então compartilhados e agrupados com os modelos de outros usuários. "Cada vez mais, as empresas estão migrando para a aprendizagem distribuída, onde os usuários não compartilham seus dados diretamente, mas, em vez disso, treine modelos locais com seus dados, "disse Arjun Nitin Bhagoji, um Ph.D. estudante no laboratório de Mittal.
Mas os adversários podem colocar um dedo na balança. Uma pessoa ou empresa com interesse no resultado pode induzir os servidores de uma empresa a pesar as atualizações de seu modelo em relação aos modelos de outros usuários. "O objetivo do adversário é garantir que os dados de sua escolha sejam classificados na classe que desejam, e não a verdadeira classe, "disse Bhagoji.
Em junho, Bhagoji apresentou um artigo sobre este tópico na Conferência Internacional de Aprendizado de Máquina (ICML) 2019 em Long Beach, Califórnia, em colaboração com dois pesquisadores da IBM Research. O artigo explorou um modelo de teste que se baseia no reconhecimento de imagem para classificar se as pessoas nas fotos estão usando sandálias ou tênis. Embora um erro de classificação induzido dessa natureza pareça inofensivo, é o tipo de subterfúgio injusto em que uma empresa inescrupulosa pode se envolver para promover seu produto em detrimento do rival.
"Os tipos de adversários que precisamos considerar na pesquisa de IA adversária variam de hackers individuais que tentam extorquir pessoas ou empresas por dinheiro, para empresas que tentam obter vantagens comerciais, para adversários em nível de estado-nação que buscam vantagens estratégicas, "disse Mittal, que também está associado ao Centro de Política de Tecnologia da Informação de Princeton.
Usar o aprendizado de máquina contra si mesmo
Uma segunda ameaça ampla é chamada de ataque de evasão. Ele pressupõe que um modelo de aprendizado de máquina tenha treinado com sucesso em dados genuínos e alcançado alta precisão em qualquer tarefa. Um adversário pode virar esse sucesso de cabeça para baixo, no entanto, manipulando as entradas que o sistema recebe assim que começa a aplicar seu aprendizado às decisões do mundo real.
Por exemplo, a IA para carros autônomos foi treinada para reconhecer limites de velocidade e sinais de parada, enquanto ignora as placas de restaurantes de fast food, Posto de gasolina, e assim por diante. O grupo de Mittal explorou uma brecha por meio da qual os sinais podem ser classificados incorretamente se forem marcados de forma que um ser humano possa não notar. Os pesquisadores fizeram placas falsas de restaurantes com cores extras, semelhantes a grafites ou manchas de paintball. As mudanças enganaram a IA do carro, fazendo-a confundir as placas do restaurante com as placas de pare.
"Adicionamos pequenas modificações que podem enganar este sistema de reconhecimento de sinais de trânsito, "disse Mittal. Um artigo sobre os resultados foi apresentado no 1º Workshop de Aprendizado Profundo e Segurança (DLS), realizada em maio de 2018 em São Francisco pelo Instituto de Engenheiros Elétricos e Eletrônicos (IEEE).
Embora menor e apenas para fins de demonstração, a perfídia da sinalização novamente revela uma maneira pela qual o aprendizado de máquina pode ser sequestrado para fins nefastos.
Não respeitando a privacidade
A terceira grande ameaça são os ataques à privacidade, que visam inferir dados sensíveis usados no processo de aprendizagem. Na sociedade atual constantemente conectada à Internet, há muita agitação por aí. Os adversários podem tentar pegar carona em modelos de aprendizado de máquina à medida que absorvem dados, obter acesso a informações protegidas, como números de cartão de crédito, registros de saúde e localização física dos usuários.
Um exemplo dessa prevaricação, estudou em Princeton, é o "ataque de inferência de associação". Ele avalia se um determinado ponto de dados se enquadra no conjunto de treinamento de aprendizado de máquina de um destino. Por exemplo, se um adversário pousar sobre os dados de um usuário enquanto seleciona o conjunto de treinamento de um aplicativo de IA relacionado à saúde, essa informação sugere fortemente que o usuário já foi um paciente no hospital. Conectar os pontos em vários desses pontos pode revelar detalhes de identificação sobre um usuário e suas vidas.
É possível proteger a privacidade, mas, neste ponto, envolve uma troca de segurança - as defesas que protegem os modelos de IA da manipulação por meio de ataques de evasão podem torná-los mais vulneráveis a ataques de inferência de associação. Essa é uma conclusão importante de um novo artigo aceito na 26ª Conferência ACM sobre Segurança de Computadores e Comunicações (CCS), a ser realizado em Londres em novembro de 2019, liderado por Liwei Song, estudante de pós-graduação de Mittal. As táticas defensivas usadas para proteger contra ataques de evasão dependem fortemente de dados confidenciais no conjunto de treinamento, o que torna esses dados mais vulneráveis a ataques de privacidade.
É o clássico debate de segurança versus privacidade, desta vez com um toque de aprendizado de máquina. Song enfatiza, assim como Mittal, que os pesquisadores terão que começar a tratar os dois domínios como inextricavelmente ligados, em vez de focar em um sem levar em conta seu impacto no outro.
"Em nosso jornal, mostrando o aumento do vazamento de privacidade introduzido pelas defesas contra ataques de evasão, destacamos a importância de pensar sobre segurança e privacidade juntos, "disse Song,
Ainda é cedo para o aprendizado de máquina e a IA de adversários - talvez cedo o suficiente para que as ameaças que inevitavelmente se materializem não tenham o controle.
"Estamos entrando em uma nova era em que o aprendizado de máquina se tornará cada vez mais integrado em quase tudo que fazemos, "disse Mittal." É fundamental que reconheçamos as ameaças e desenvolvamos contramedidas contra elas. "