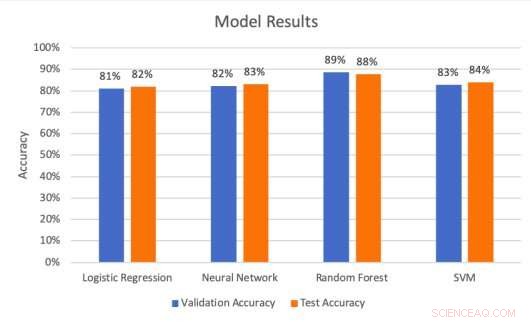
Resultados do modelo nos conjuntos de validação e teste. Crédito:Middlebrook &Sheik.
Dois estudantes e pesquisadores da Universidade de São Francisco (USF) recentemente tentaram prever acertos em outdoors usando modelos de aprendizado de máquina. Em seu estudo, pré-publicado no arXiv, eles treinaram quatro modelos em dados relacionados à música extraídos usando a API da Web do Spotify, e então avaliou seu desempenho ao prever quais músicas se tornariam sucessos.
"Sou um grande fã de música, e ouço música o dia todo; durante meu trajeto, no trabalho, e com amigos, "Kai Middlebrook, um dos pesquisadores que realizou o estudo, disse TechXplore. "Última primavera, Comecei um projeto de pesquisa sobre classificação automática de gênero musical com o professor David Guy Brizan da Universidade de San Francisco (USF). O projeto exigiu uma grande quantidade de dados musicais, e os serviços de streaming de música populares têm exatamente o tipo de dados de que eu precisava. "
Enquanto ele estava trabalhando em um projeto relacionado à classificação automática de gênero musical, Middlebrook aprendeu que o Spotify permite que os desenvolvedores acessem seus dados musicais. Isso o encorajou a começar a experimentar a API da Web do Spotify para coletar dados para seus estudos. Depois de concluir a pesquisa relacionada à classificação de gênero, Contudo, ele deixou a API de lado por algum tempo.
"Alguns meses depois, meu amigo Kian, que também é cientista de dados e adora música, e eu tive uma discussão sobre música, "Middlebrook disse." Em algum ponto durante a conversa, a ideia geralmente sustentada de que "todas as canções de sucesso têm o mesmo som" foi levantada. Não acreditamos necessariamente que fosse verdade, mas a ideia nos fez pensar:e se os hits tivessem algumas semelhanças? Parecia possivel, então Kian e eu decidimos investigar mais. "
Middlebrook e Sheik, que já havia colaborado no projeto de classificação de gênero, decidiu realizar uma investigação adicional usando dados extraídos do Spotify. Este novo projeto também seria a tarefa final de seu curso de mineração de dados na USF.
“Estávamos colaborando em vários outros projetos para vários cursos, então fazia sentido ficarmos juntos, "Kian Sheik, outro pesquisador envolvido no estudo, disse TechXplore. O hit de "Lil Nas X" Old Town Road "surgiu do nada, e estava no topo da Billboard Hot 100. Kai e eu nos perguntamos se um computador poderia ter previsto sua ascensão, ou se foi apenas um single de sucesso que saiu do campo esquerdo. O que começou como um projeto final simples terminou com a gente exaurindo todos os modelos de aprendizado supervisionado de última geração em um grande conjunto de dados para responder a uma pergunta simples:Essa música será um sucesso? "
Em seu estudo, Middlebrook e Sheik usaram a API da Web do Spotify para coletar dados de 1,8 milhões de músicas, que incluía recursos como o tempo de uma música, chave, valência, Em seguida, eles também coletaram dados de aproximadamente 30 anos do gráfico Billboard Hot 100.
"Nosso objetivo era ver se as canções de sucesso compartilhavam características semelhantes, e se, se esses recursos podem ser usados para prever quais músicas seriam sucessos no futuro, "Middlebrook disse.
Os pesquisadores treinaram e avaliaram quatro modelos diferentes:uma regressão logística, uma rede neural, uma máquina de vetores de suporte (SVM) e uma arquitetura de floresta aleatória (RF). Durante o treinamento, esses modelos analisaram uma variedade de recursos de música, incluindo tempo, chave, valência, energia, acústico, danceabilidade e volume.
"Quando dada uma música, nossos modelos o rotulariam com um ou zero, "Middlebrook explicou." Uma música marcada com um significa que a modelo está prevendo que a música foi um sucesso. Uma música marcada com um zero significa que a modelo está prevendo que a música não foi um sucesso. "
O modelo de regressão logística treinado pelos pesquisadores assume que os dados da música podem ser linearmente separados em duas categorias:hits e não hits. O modelo atribui um peso a cada recurso da música, e então usa esses pesos para prever se uma música se enquadra na categoria "hit" ou "não hit".
Os modelos de regressão logística têm duas vantagens importantes:interpretabilidade e velocidade. Em outras palavras, este tipo de arquitetura torna mais fácil interpretar a relação entre as variáveis explicativas (ou seja, os recursos da música) e a variável de resposta (ou seja, hit ou não hit), e também pode ser treinado com relativa rapidez.
O segundo modelo treinado pelos pesquisadores foi uma arquitetura de RF. Este modelo funciona combinando uma grande quantidade de blocos de construção conhecidos como árvores de decisão.
"Essencialmente, uma árvore de decisão pode ser pensada como um modelo que usa uma série de perguntas sim / não para separar os dados, "Middlebrook disse." Eles são interpretáveis, mas propenso a overfitting dos dados. Overfitting significa que um modelo memoriza os dados de treinamento ajustando-os muito próximos. O problema com o overfitting é que o modelo pode não estar aprendendo a relação real entre os recursos da música e a popularidade da música, porque os dados geralmente contêm ruído irrelevante. "
Para evitar o problema de overfitting, o modelo de floresta aleatório usado por Middlebrook e Sheik combina centenas de milhares de árvores de decisão, cada um dos quais é treinado em um subconjunto diferente dos dados de treinamento e um subconjunto diferente dos recursos da música. O modelo então faz uma previsão (ou seja, decide se uma música é um sucesso ou não) calculando a média da previsão de cada árvore e combinando esses resultados.
"Em nosso caso de uso, a vantagem do modelo de floresta aleatória é sua flexibilidade, "Middlebrook disse." É mais flexível do que um modelo linear (por exemplo, regressão logística). "
O terceiro e o quarto modelos treinados pelos pesquisadores, ou seja, o SVM e arquiteturas de rede neural, são não lineares e, portanto, mais difíceis de interpretar. O modelo SVM funciona tentando encontrar o "hiperplano" que melhor separa os dados nas duas categorias (ou seja, hits ou não hits). A arquitetura da rede neural, por outro lado, usa uma camada oculta com dez filtros para aprender com os dados da música.
Entre os quatro modelos usados por Middlebrook e Sheik, o modelo de regressão logística é o mais fácil de interpretar, enquanto o baseado em rede neural é o mais difícil. Os outros dois modelos ficam em algum lugar no meio.
"Geralmente, esses modelos irão prever com base nas restrições que desenvolvem por meio de treinamento, "Sheik disse." Cada modelo foi treinado no mesmo conjunto de classificadores sônicos. A saída dos modelos é testada em relação à verdade histórica da API Billboard, se a faixa fornecida já apareceu ou não na lista Billboard Hot 100. Usamos uma frota de computadores na USF para fazer cálculos numéricos e, após algumas semanas de computação pura, calculamos os parâmetros ideais para cada modelo. "
Os pesquisadores realizaram uma série de avaliações para testar o quão bem os quatro modelos podem prever acertos em outdoors. Eles descobriram que a arquitetura SVM alcançou a maior taxa de precisão (99,53 por cento), enquanto o modelo de floresta aleatória atingiu a melhor taxa de precisão (88 por cento) e taxa de recall (85,51 por cento).
"Recall expressa a capacidade de encontrar todas as instâncias relevantes em um conjunto de dados, enquanto a precisão expressa a proporção de dados que nosso modelo diz serem relevantes e realmente relevantes, "Middlebrook explicou." Em outras palavras, Lembre-se de nos dizer a probabilidade de nosso modelo prever com precisão um acerto real como um acerto. A precisão nos diz a proporção de acertos previstos que foram de fato acertos. "
De acordo com os pesquisadores, se as gravadoras usassem qualquer um desses modelos para prever quais músicas teriam mais sucesso, eles provavelmente escolheriam um modelo com uma alta taxa de precisão do que um com uma alta taxa de precisão. Isso ocorre porque um modelo que atinge alta precisão assume menos risco, já que é menos provável que uma música sem sucesso se torne um sucesso.
"As gravadoras têm recursos limitados, "Middlebrook disse." Se eles derramarem esses recursos em uma música que a modelo prevê que será um sucesso e essa música nunca se tornará um, então a gravadora pode perder muito dinheiro. Então, se uma gravadora quiser se arriscar um pouco mais com a possibilidade de lançar mais discos de sucesso, eles podem escolher usar nosso modelo de floresta aleatório. Por outro lado, se uma gravadora quiser assumir menos riscos e ainda lançar alguns sucessos, eles devem usar nosso modelo SVM. "
Middlebrook e Sheik descobriram que prever um hit de outdoor com base nos recursos de áudio de uma música é, na verdade, possível. Em suas pesquisas futuras, os pesquisadores planejam investigar outros fatores que podem contribuir para o sucesso da música, como presença na mídia social, experiência do artista, e influência do rótulo.
"Podemos imaginar um mundo onde as gravadoras que estão constantemente em busca de novos talentos são inundadas com mix-tapes e demos dos" próximos artistas da moda, "" Sheik disse. "As pessoas têm pouco tempo para ouvir música com ouvidos humanos, então "orelhas artificiais, "como nossos algoritmos, pode permitir que as gravadoras treinem um modelo para o tipo de som que procuram e reduzem muito o número de canções que elas próprias devem considerar. "
Classificadores como os desenvolvidos por Middlebrook e Sheik podem ajudar as gravadoras a decidir em quais músicas investir. Embora a ideia de usar o aprendizado de máquina para ler as demos possa ser do interesse da indústria musical, Sheik avisa que também pode ter consequências indesejáveis.
"Embora este possa ser um futuro conveniente, a perspectiva de um proverbial "bloco de corte" que os artistas têm de atingir tem o potencial de se tornar uma câmara de eco, ou uma situação em que uma nova música deve soar como velha para ser lançada no rádio, "Sheik disse." Criadores de conteúdo em plataformas como o YouTube, que também usa algoritmos para decidir quais vídeos são exibidos para as massas, condenaram as armadilhas de forçar artistas a trabalhar para uma máquina. "
De acordo com Sheik, se empresas e produtores começarem a usar algoritmos para tomar decisões artísticas, esses modelos devem ser projetados de uma forma que não atrapalhe o progresso da arte. As arquiteturas desenvolvidas pelos dois pesquisadores da USF, Contudo, ainda não são capazes de alcançar isso.
"O viés da novidade e outras características não ortodoxas terão que ser introduzidas e inventadas para que a música como um todo não se aproxime de uma singularidade cultural nas mãos da conveniência, "Sheik concluiu.
© 2019 Science X Network