Um algoritmo está apenas seguindo regras projetadas direta ou indiretamente por um ser humano. Crédito:Shutterstock / bilhões de fotos
O papel dos algoritmos em nossas vidas está crescendo rapidamente, de simplesmente sugerir resultados de pesquisa online ou conteúdo em nosso feed de mídia social, para questões mais críticas, como ajudar os médicos a determinar nosso risco de câncer.
Mas como sabemos que podemos confiar na decisão de um algoritmo? Em junho, quase 100 motoristas nos Estados Unidos aprenderam da maneira mais difícil que às vezes os algoritmos podem errar muito.
O Google Maps deixou todos presos em uma estrada privada lamacenta em um desvio fracassado para escapar de um engarrafamento em direção ao Aeroporto Internacional de Denver, no Colorado.
À medida que nossa sociedade se torna cada vez mais dependente de algoritmos para aconselhamento e tomada de decisão, está se tornando urgente enfrentar a espinhosa questão de como podemos confiar neles.
Os algoritmos são regularmente acusados de preconceito e discriminação. Eles atraíram a preocupação de políticos dos EUA, em meio a alegações, temos homens brancos desenvolvendo algoritmos de reconhecimento facial treinados para funcionar bem apenas para homens brancos.
Mas os algoritmos nada mais são do que programas de computador que tomam decisões com base em regras:sejam as regras que demos a eles, ou regras que eles próprios descobriram com base nos exemplos que demos a eles.
Em ambos os casos, os humanos estão no controle desses algoritmos e de como eles se comportam. Se um algoritmo é falho, é nossa ação.
Então, antes que todos nós terminemos em um engarrafamento metafórico (ou literal!) Enlameado, há uma necessidade urgente de revisitar como nós, humanos, escolhemos testar essas regras e ganhar confiança nos algoritmos.
Algoritmos postos à prova, tipo de
Os humanos são criaturas naturalmente suspeitas, mas a maioria de nós pode ser convencida por evidências.
Dados exemplos de teste suficientes - com respostas corretas conhecidas - desenvolvemos confiança se um algoritmo dá consistentemente a resposta correta, e não apenas para exemplos fáceis e óbvios, mas para os desafiadores, exemplos realistas e diversos. Então, podemos estar convencidos de que o algoritmo é imparcial e confiável.
Parece fácil, direito? Mas é assim que os algoritmos geralmente são testados? É mais difícil do que parece garantir que os exemplos de teste sejam imparciais e representativos de todos os cenários possíveis que podem ser encontrados.
Mais comumente, exemplos de benchmarks bem estudados são usados porque estão facilmente disponíveis em sites. (A Microsoft tinha um banco de dados de rostos de celebridades para testar algoritmos de reconhecimento facial, mas foi excluído recentemente devido a questões de privacidade.)
A comparação de algoritmos também é mais fácil quando testada em benchmarks compartilhados, mas esses exemplos de teste raramente são examinados quanto a seus preconceitos. Pior ainda, o desempenho dos algoritmos é normalmente relatado em média nos exemplos de teste.
Infelizmente, saber que um algoritmo tem um bom desempenho, em média, não nos diz nada sobre se podemos confiar nele em casos específicos.
Não é surpreendente ler que os médicos são céticos em relação ao algoritmo do Google para diagnóstico de câncer, que oferece uma precisão de 89% em média. Como um médico sabe se seu paciente é um dos 11% azarados com um diagnóstico incorreto?
Com o aumento da demanda por medicina personalizada sob medida para o indivíduo (não apenas Sr. / Sra. Média), e com médias conhecidas por esconder todos os tipos de pecados, os resultados médios não conquistam a confiança humana.
A necessidade de novos protocolos de teste
Claramente não é rigoroso o suficiente para testar um monte de exemplos - benchmarks bem estudados ou não - sem provar que eles são imparciais, e, em seguida, tirar conclusões sobre a confiabilidade de um algoritmo em média.
E ainda assim, paradoxalmente, esta é a abordagem da qual os laboratórios de pesquisa em todo o mundo dependem para flexionar seus músculos algorítmicos. O processo de revisão acadêmica por pares reforça esses procedimentos de teste herdados e raramente questionados.
Um novo algoritmo é publicável se for melhor, em média, do que os algoritmos existentes em exemplos de benchmarks bem estudados. Se não for competitivo dessa forma, ou está oculto de mais escrutínio de revisão por pares, ou novos exemplos são apresentados para os quais o algoritmo parece útil.
Desta maneira, um calor, luz lisonjeira brilha em cada algoritmo recém-publicado, com poucas tentativas de testar seus pontos fortes e fracos, e apresentá-lo com verrugas e tudo. É a versão da ciência da computação de pesquisadores médicos que não publicam os resultados completos dos testes clínicos.
À medida que a confiança algorítmica se torna mais crucial, Precisamos urgentemente atualizar esta metodologia para examinar se os exemplos de teste escolhidos são adequados para o propósito. Até aqui, pesquisadores foram impedidos de análises mais rigorosas devido à falta de ferramentas adequadas.
Construímos um melhor teste de estresse
Depois de mais de uma década de pesquisa, minha equipe lançou uma nova ferramenta de análise de algoritmo online chamada MATILDA:Melbourne Algorithm Test Instance Library with Data Analytics.
Ajuda algoritmos de teste de estresse de forma mais rigorosa, criando visualizações poderosas de um problema, mostrando todos os cenários ou exemplos que um algoritmo deve considerar para testes abrangentes.
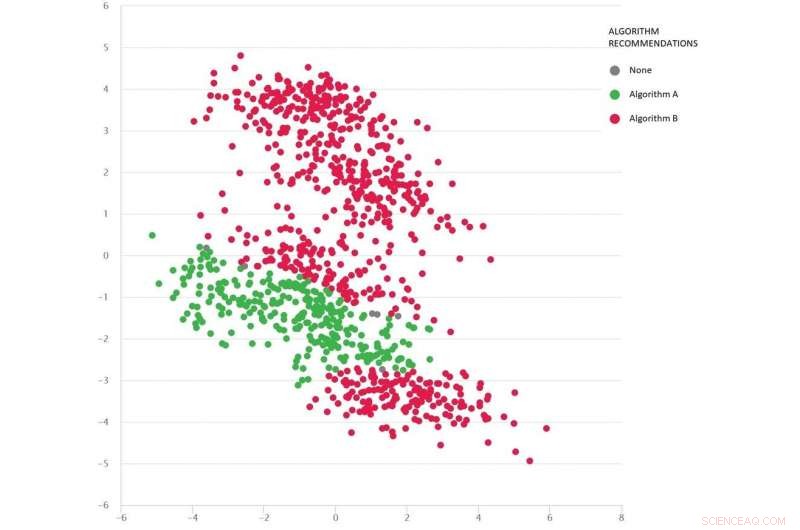
Um problema do tipo Google Maps com diversos cenários de teste como pontos:Algoritmo B (vermelho) é o melhor em média, mas o Algoritmo A (verde) é melhor em muitos casos. Crédito:MATILDA, Autor fornecido
MATILDA identifica os pontos fortes e fracos de cada algoritmo, recomendar quais algoritmos disponíveis usar em diferentes cenários e por quê.
Por exemplo, se a chuva recente transformou estradas não pavimentadas em lama, alguns algoritmos de "caminho mais curto" podem não ser confiáveis, a menos que possam prever o provável impacto do tempo nos tempos de viagem ao aconselhar a rota mais rápida. A menos que os desenvolvedores testem esses cenários, eles nunca saberão dessas fraquezas até que seja tarde demais e estejamos presos na lama.
MATILDA nos ajuda a ver a diversidade e abrangência dos benchmarks, e onde novos exemplos de teste devem ser projetados para preencher cada canto e recanto do espaço possível no qual o algoritmo poderia ser solicitado a operar.
A imagem abaixo mostra um conjunto diversificado de cenários (pontos) para um tipo de problema do Google Maps. Cada cenário varia as condições - como os locais de origem e destino, a rede rodoviária disponível, condições do tempo, tempos de viagem em várias estradas - e todas essas informações são matematicamente capturadas e resumidas pelas coordenadas bidimensionais de cada cenário no espaço.
Dois algoritmos são comparados (vermelho e verde) para ver qual deles pode encontrar a rota mais curta. Cada algoritmo é comprovado como o melhor (ou não confiável) em diferentes regiões, dependendo de seu desempenho nesses cenários testados.
Também podemos adivinhar qual algoritmo provavelmente será o melhor para os cenários ausentes (lacunas) que ainda não testamos.
A matemática por trás do MATILDA ajuda a criar essa visualização, analisando os dados de confiabilidade do algoritmo de cenários de teste, e encontrar uma maneira de ver os padrões facilmente.
Os insights e as explicações significam que podemos escolher o melhor algoritmo para o problema em questão, em vez de cruzar os dedos e esperar que possamos confiar no algoritmo que tem o melhor desempenho em média.
Por meio de algoritmos de teste de estresse rigorosos dessa forma - com verrugas e tudo - devemos reduzir o risco de decisões de algoritmos desonestos, garantindo a confiança do Sr. / Sra. Average, e talvez até os humanos mais céticos.
Este artigo foi republicado de The Conversation sob uma licença Creative Commons. Leia o artigo original.