Crédito:KTH The Royal Institute of Technology
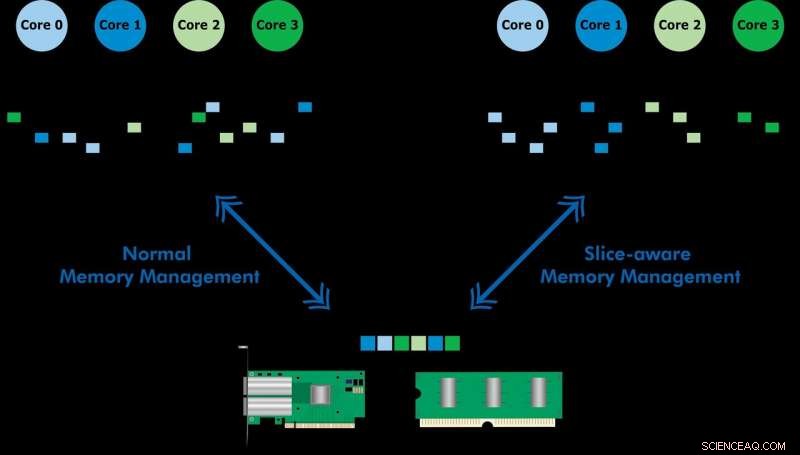
Desenvolvido com Ericsson Research, o esquema de gerenciamento de memória com reconhecimento de fatia permite que os dados usados com frequência sejam acessados mais rapidamente por meio do cache de memória de último nível (LLC) de uma CPU Intel Xeon. Ao estabelecer um armazenamento de valor-chave e alocar memória de uma forma que mapeie para a fatia LLC mais apropriada, eles demonstraram processamento de pacotes de alta velocidade e desempenho aprimorado de um armazenamento de valor-chave. A equipe usou o esquema proposto para implementar uma ferramenta chamada CacheDirector, que torna o Data Direct I / O (DDIO) ciente de slice e publicou um artigo de conferência, Aproveite ao máximo o cache de último nível nos processadores Intel, que foi apresentado na EuroSys 2019 na primavera.
"No momento, um servidor que recebe pacotes de 64 bytes a 100 Gbps tem apenas 5,12 nanossegundos para processar cada pacote antes que o próximo chegue, "diz o co-autor Alireza Farshin, um aluno de doutorado no Network Systems Laboratory do KTH. Mas se os dados forem roteados para a fatia de cache certa na CPU, ele pode ser acessado mais rápido, permitindo um processamento mais rápido de mais pacotes, em menos de 5 nanossegundos.
Data Direct I / O (DDIO) envia pacotes para fatias aleatórias, o que está longe de ser eficiente. Dada a arquitetura de cache não uniforme de hoje (NUCA), a solução de gerenciamento de cache é inestimável, diz KTH Professor Dejan Kostic, quem liderou a pesquisa.
"Quando combinado com a introdução de headroom dinâmico no Data Plane Development Kit (DPDK), o cabeçalho do pacote pode ser colocado na fatia do LLC que está mais próxima do núcleo de processamento relevante. Como resultado, o núcleo pode acessar os pacotes mais rapidamente, ao mesmo tempo que reduz o tempo de enfileiramento, " ele diz.
"Nosso trabalho demonstra que tirar proveito de melhorias de nanossegundos na latência pode ter um grande impacto no desempenho de aplicativos executados em sistemas de computador já altamente otimizados, "Farshin diz. A equipe descobriu que, para uma CPU rodando a 3,2 GHz, CacheDirector pode economizar até cerca de 20 ciclos por acesso ao LLC, o que equivale a 6,25 nanossegundos. Isso acelera o processamento de pacotes e reduz as latências de cauda de cadeias de serviços de Network Function Virtualization (NFV) otimizadas em execução a 100 Gbps em até 21,5 por cento.