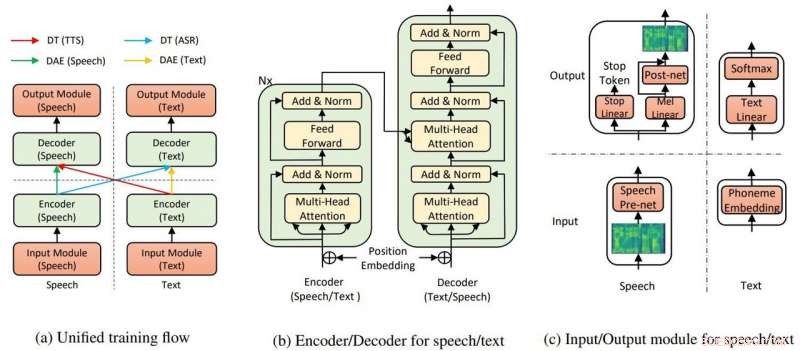
A estrutura geral do modelo para TTS e ASR. Crédito:Yi Ren, Xu Tan et al.
A Microsoft Research Asia tem recebido aplausos por transformar texto em fala, exigindo pouco treinamento - e mostrando resultados "incrivelmente" realistas.
Kyle Wiggers em VentureBeat ditos algoritmos de conversão de texto em voz não eram novos e outros bastante capazes, mas, ainda, o esforço da equipe na Microsoft ainda tem uma vantagem.
Abdullah Matloob em Mundo da Informação Digital :"A conversão de texto em voz está ficando inteligente com o tempo, mas a desvantagem é que ainda levará uma quantidade excessiva de tempo de treinamento e recursos para construir um produto de som natural. "
Procurando uma maneira de livrar-se da carga de tempo e recursos de treinamento para criar resultados que pareçam naturais, A Microsoft Research e os pesquisadores chineses descobriram outra maneira de converter texto em fala.
Fabienne Lang em Engenharia Interessante :A resposta deles acabou sendo um texto-para-fala AI usando 200 amostras de voz (apenas 200) para criar um discurso de som realista para coincidir com as transcrições. Lang disse, "Isso significa aproximadamente 20 minutos."
O fato de a exigência ser de apenas 200 clipes de áudio e as transcrições correspondentes impressionou Wiggers em VentureBeat . Ele também observou que os pesquisadores desenvolveram um sistema de IA "que aproveita o aprendizado não supervisionado - um ramo do aprendizado de máquina que coleta conhecimento dos não rotulados, não classificado, e dados de teste não categorizados. "
O artigo deles está em arXiv. "Texto para fala quase sem supervisão e reconhecimento automático de fala" é de Yi Ren, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, Tie-Yan Liu. As afiliações do autor são a Universidade de Zhejiang, Microsoft Research e Microsoft Search Technology Center (STC) Ásia.
Em seu jornal, a equipe disse que o TTS AI utiliza dois componentes principais, um transformador e codificador automático de eliminação de ruído, para fazer tudo funcionar.
"Por meio dos transformadores, A inteligência artificial text-to-speech da Microsoft foi capaz de reconhecer fala ou texto como entrada ou saída, "disse um artigo em Nervoso por Rechelle Fuertes.
Tyler Lee em Ubergizmo forneceu uma definição de transformador:"Transformadores ... são redes neurais profundas projetadas para emular os neurônios em nosso cérebro."
MathWorks tinha uma definição para autoencoder. "Um autoencoder é um tipo de rede neural artificial usada para aprender dados eficientes (codificações) de uma maneira não supervisionada. O objetivo de um codificador automático é aprender uma representação (codificação) para um conjunto de dados, Denoising autoencoders é tipicamente um tipo de autoencoders treinados para ignorar 'ruído' em amostras de entrada corrompidas. "
Os resultados de seu experimento mostraram que vale a pena perseguir sua ideia? "Nosso método atinge 99,84% em termos de taxa de inteligibilidade em nível de palavra e 2,68 MOS para TTS, e 11,7% PER para ASR [reconhecimento automático de fala] no conjunto de dados LJSpeech, aproveitando apenas 200 vozes emparelhadas e dados de texto (cerca de 20 minutos de áudio), junto com dados extras de fala e texto não pareados. "
Por que isso é importante:essa abordagem pode tornar o texto em fala mais acessível, disse relatórios.
"Os pesquisadores estão trabalhando continuamente para melhorar o sistema, e temos esperança de que, no futuro, vai dar ainda menos trabalho para gerar um discurso realista, "disse Lang.
O artigo será apresentado na Conferência Internacional sobre Aprendizado de Máquina, em Long Beach, Califórnia, no final deste ano, e a equipe planeja lançar o código nas próximas semanas, disse Wiggers.
Enquanto isso, os pesquisadores ainda não estão se afastando de seu trabalho ao apresentar transformações com poucos dados emparelhados.
"Nesse trabalho, propusemos o método quase não supervisionado para conversão de texto em fala e reconhecimento automático de fala, que aproveita apenas alguns dados de voz e texto emparelhados e dados extra desemparelhados ... Para trabalhos futuros, vamos empurrar em direção ao limite da aprendizagem não supervisionada, aproveitando puramente a fala e os dados de texto não pareados, com a ajuda de outros métodos de pré-treinamento. "
© 2019 Science X Network














