Pesquisadores do MIT desenvolveram um baixo custo, luva com sensor que captura os sinais de pressão à medida que os humanos interagem com os objetos. A luva pode ser usada para criar conjuntos de dados táteis de alta resolução que os robôs podem aproveitar para identificar melhor, pesar, e manipular objetos. Crédito:Massachusetts Institute of Technology
Usar uma luva com sensor ao manusear uma variedade de objetos, Os pesquisadores do MIT compilaram um enorme conjunto de dados que permite a um sistema de IA reconhecer objetos apenas pelo toque. As informações podem ser aproveitadas para ajudar os robôs a identificar e manipular objetos, e pode auxiliar no projeto de próteses.
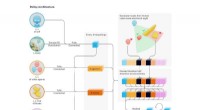
Os pesquisadores desenvolveram uma luva de malha de baixo custo, chamada de "luva tátil escalável" (STAG), equipado com cerca de 550 sensores minúsculos em quase toda a mão. Cada sensor captura sinais de pressão conforme os humanos interagem com os objetos de várias maneiras. Uma rede neural processa os sinais para "aprender" um conjunto de dados de padrões de sinais de pressão relacionados a objetos específicos. Então, o sistema usa esse conjunto de dados para classificar os objetos e prever seus pesos apenas por sentir, sem necessidade de entrada visual.
Em um artigo publicado em Natureza , os pesquisadores descrevem um conjunto de dados que compilaram usando STAG para 26 objetos comuns, incluindo uma lata de refrigerante, tesoura, bola de tênis, colher, caneta, e caneca. Usando o conjunto de dados, o sistema previu as identidades dos objetos com até 76 por cento de precisão. O sistema também pode prever os pesos corretos da maioria dos objetos em cerca de 60 gramas.
Luvas baseadas em sensores semelhantes usadas hoje custam milhares de dólares e geralmente contêm apenas cerca de 50 sensores que capturam menos informações. Embora STAG produza dados de alta resolução, é feito de materiais disponíveis comercialmente, totalizando cerca de US $ 10.
O sistema de detecção tátil pode ser usado em combinação com a visão computacional tradicional e conjuntos de dados baseados em imagens para dar aos robôs uma compreensão mais humana da interação com objetos.
"Os humanos podem identificar e manusear bem os objetos porque temos feedback tátil. À medida que tocamos os objetos, sentimos ao redor e percebemos o que são. Os robôs não têm esse feedback rico, "diz Subramanian Sundaram Ph.D. '18, ex-aluno de pós-graduação do Laboratório de Ciência da Computação e Inteligência Artificial (CSAIL). "Sempre quisemos que os robôs fizessem o que os humanos podem fazer, como lavar a louça ou outras tarefas. Se você quiser que os robôs façam essas coisas, eles devem ser capazes de manipular objetos muito bem. "
Os pesquisadores também usaram o conjunto de dados para medir a cooperação entre as regiões da mão durante as interações de objetos. Por exemplo, quando alguém usa a junta do meio do dedo indicador, raramente usam o polegar. Mas as pontas dos dedos indicador e médio sempre correspondem ao uso do polegar. "Nós mostramos de forma quantificável, pela primeira vez, naquela, se estou usando uma parte da minha mão, qual a probabilidade de eu usar outra parte da minha mão, " ele diz.
Os fabricantes de próteses podem potencialmente usar informações para, dizer, escolha os locais ideais para colocar sensores de pressão e ajude a personalizar próteses para as tarefas e objetos com os quais as pessoas interagem regularmente.
Participaram do trabalho de Sundaram:os pós-docs do CSAIL Petr Kellnhofer e Jun-Yan Zhu; O estudante de pós-graduação do CSAIL Yunzhu Li; Antonio Torralba, professor do EECS e diretor do MIT-IBM Watson AI Lab; e Wojciech Matusik, professor associado de engenharia elétrica e ciência da computação e chefe do grupo de fabricação computacional.
O STAG como plataforma para aprender com a compreensão humana. Crédito: Natureza (2019). DOI:10.1038 / s41586-019-1234-z
STAG é laminado com um polímero eletricamente condutor que altera a resistência à pressão aplicada. Os pesquisadores costuraram fios condutores através de orifícios no filme de polímero condutor, da ponta dos dedos à base da palma. Os fios se sobrepõem de uma maneira que os transforma em sensores de pressão. Quando alguém usando a luva sente, elevadores, segura, e deixa cair um objeto, os sensores registram a pressão em cada ponto.
Os fios se conectam da luva a um circuito externo que traduz os dados de pressão em "mapas táteis, "que são essencialmente vídeos breves de pontos crescendo e diminuindo em um gráfico de uma mão. Os pontos representam a localização dos pontos de pressão, e seu tamanho representa a força - quanto maior o ponto, quanto maior a pressão.
A partir desses mapas, os pesquisadores compilaram um conjunto de dados de cerca de 135, 000 frames de vídeo de interações com 26 objetos. Esses quadros podem ser usados por uma rede neural para prever a identidade e o peso dos objetos, e fornecer informações sobre a compreensão humana.
Para identificar objetos, os pesquisadores projetaram uma rede neural convolucional (CNN), que geralmente é usado para classificar imagens, para associar padrões de pressão específicos a objetos específicos. Mas o truque era escolher molduras de diferentes tipos de preensão para obter uma imagem completa do objeto.
A ideia era imitar a maneira como os humanos podem segurar um objeto de algumas maneiras diferentes para reconhecê-lo, sem usar sua visão. De forma similar, a CNN dos pesquisadores escolhe até oito quadros semi-aleatórios do vídeo que representam as compreensões mais diferentes - digamos, segurando uma caneca do fundo, principal, e manuseio.
Mas a CNN não pode simplesmente escolher quadros aleatórios entre os milhares de cada vídeo, ou provavelmente não escolherá punhos distintos. Em vez de, ele agrupa frames semelhantes, resultando em clusters distintos correspondentes a agarres únicos. Então, ele puxa um quadro de cada um desses clusters, garantindo que tem uma amostra representativa. Em seguida, a CNN usa os padrões de contato que aprendeu no treinamento para prever uma classificação de objeto a partir dos quadros escolhidos.
"Queremos maximizar a variação entre os frames para dar a melhor entrada possível para nossa rede, "Kellnhofer diz." Todos os quadros dentro de um único cluster devem ter uma assinatura semelhante que representa as formas semelhantes de agarrar o objeto. A amostragem de vários clusters simula um ser humano tentando interativamente encontrar diferentes pegadas enquanto explora um objeto. "
Para estimativa de peso, os pesquisadores construíram um conjunto de dados separado de cerca de 11, 600 quadros de mapas táteis de objetos sendo pegos com o dedo e o polegar, guardado, e caiu. Notavelmente, a CNN não foi treinada em nenhum quadro em que foi testada, o que significa que não poderia aprender a apenas associar o peso a um objeto. Em teste, um único quadro foi inserido na CNN. Essencialmente, a CNN identifica a pressão em torno da mão causada pelo peso do objeto, e ignora a pressão causada por outros fatores, como o posicionamento da mão para evitar que o objeto escorregue. Em seguida, ele calcula o peso com base nas pressões apropriadas.
O sistema pode ser combinado com os sensores já nas articulações do robô que medem o torque e a força para ajudá-los a prever melhor o peso do objeto. "As juntas são importantes para prever o peso, mas também existem componentes importantes de peso nas pontas dos dedos e na palma da mão que capturamos, "Diz Sundaram.
Esta história foi republicada por cortesia do MIT News (web.mit.edu/newsoffice/), um site popular que cobre notícias sobre pesquisas do MIT, inovação e ensino.