Brookhaven Lab colaborou com a Columbia University, Universidade de Edimburgo, e Intel para otimizar o desempenho de um computador paralelo de 144 nós construído a partir dos processadores Intel Xeon Phi e da rede de comunicação de alta velocidade Omni-Path. O computador está instalado no Centro de Dados Científicos e Computação de Brookhaven, como visto acima com o engenheiro de tecnologia Costin Caramarcu. Crédito:Laboratório Nacional de Brookhaven
A computação de alto desempenho (HPC) - o uso de supercomputadores e técnicas de processamento paralelo para resolver grandes problemas computacionais - é de grande utilidade na comunidade científica. Por exemplo, cientistas do Laboratório Nacional Brookhaven do Departamento de Energia dos EUA (DOE) confiam na HPC para analisar os dados que coletam nas instalações experimentais de grande escala no local e para modelar processos complexos que seriam muito caros ou impossíveis de demonstrar experimentalmente.
Aplicações da ciência moderna, como simular interações de partículas, muitas vezes requerem uma combinação de poder de computação agregado, redes de alta velocidade para transferência de dados, grandes quantidades de memória, e recursos de armazenamento de alta capacidade. Avanços no hardware e software HPC são necessários para atender a esses requisitos. Cientistas da computação e da computação e matemáticos da Iniciativa de Ciência da Computação do Laboratório Brookhaven (CSI) estão colaborando com físicos, biólogos, e outros cientistas de domínio para entender suas necessidades de análise de dados e fornecer soluções para acelerar o processo de descoberta científica.
Um líder da indústria de HPC
Por décadas, A Intel Corporation tem sido uma das líderes no desenvolvimento de tecnologias HPC. Em 2016, a empresa lançou os processadores Intel Xeon PhiTM (anteriormente com o codinome "Knights Landing"), sua arquitetura HPC de segunda geração que integra muitas unidades de processamento (núcleos) por chip. O mesmo ano, A Intel lançou a rede de comunicação de alta velocidade Intel Omni-Path Architecture. Para o 5, 000 a 100, 000 computadores individuais, ou nós, em supercomputadores modernos para trabalhar juntos para resolver um problema, eles devem ser capazes de se comunicar rapidamente entre si, ao mesmo tempo em que minimizam os atrasos na rede.
Logo após esses lançamentos, Brookhaven Lab e RIKEN, A maior instituição de pesquisa abrangente do Japão, reuniram seus recursos para comprar um pequeno computador paralelo de 144 nós construído com processadores Xeon Phi e duas conexões de rede independentes, ou trilhos, usando a arquitetura Omni-Path da Intel. O computador foi instalado no Centro de Dados Científicos e Computação do Brookhaven Lab, que faz parte do CSI.
Uma imagem da matriz do processador Xeon Phi Knights Landing. Um dado é um padrão em uma placa de material semicondutor que contém o circuito eletrônico para executar uma função específica. Crédito:Intel
Com a instalação concluída, o físico Chulwoo Jung e o cientista computacional de CSI Meifeng Lin, do Laboratório Brookhaven; físico teórico Christoph Lehner, um nomeado conjunto no Brookhaven Lab e na Universidade de Regensburg, na Alemanha; Norman Christ, o professor Ephraim Gildor de Física Teórica Computacional na Universidade de Columbia; e o físico teórico de partículas Peter Boyle, da Universidade de Edimburgo, trabalharam em estreita colaboração com engenheiros de software da Intel para otimizar o software de rede para duas aplicações científicas:física de partículas e aprendizado de máquina.
"A CSI estava muito interessada na arquitetura Intel Omni-Path desde que foi anunciada em 2015, "disse Lin." A experiência dos engenheiros da Intel foi crítica para implementar as otimizações de software que nos permitiram tirar o máximo proveito dessa rede de comunicação de alto desempenho para nossas necessidades específicas de aplicativos. "
Requisitos de rede para aplicações científicas
Para muitas aplicações científicas, executar uma classificação (um valor que distingue um processo de outro) ou possivelmente algumas classificações por nó em um computador paralelo é muito mais eficiente do que executar várias classificações por nó. Cada classificação normalmente executa como um processo independente que se comunica com as outras classificações usando um protocolo padrão conhecido como Message Passing Interface (MPI).
Por exemplo, físicos que buscam entender como o universo inicial formado executam simulações numéricas complexas de interações de partículas com base na teoria da cromodinâmica quântica (QCD). Esta teoria explica como as partículas elementares chamadas quarks e glúons interagem para formar as partículas que observamos diretamente, como prótons e nêutrons. Os físicos modelam essas interações usando supercomputadores que representam as três dimensões do espaço e a dimensão do tempo em uma rede quadridimensional (4-D) de pontos igualmente espaçados, semelhante ao de um cristal. A estrutura é dividida em sub-volumes idênticos menores. Para cálculos QCD de rede, os dados precisam ser trocados nas fronteiras entre os diferentes subvolumes. Se houver várias classificações por nó, cada classificação hospeda um subvolume 4-D diferente. Assim, dividir os subvolumes cria mais limites onde os dados precisam ser trocados e, portanto, transferências de dados desnecessárias que tornam os cálculos mais lentos.
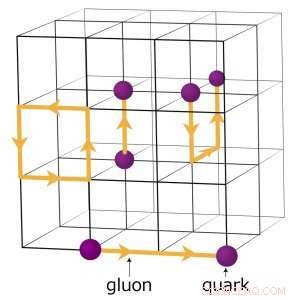
Um esquema da rede para cálculos cromodinâmicos quânticos. Os pontos de interseção na grade representam valores de quark, enquanto as linhas entre eles representam os valores do glúon. Crédito:Laboratório Nacional de Brookhaven
Otimizações de software para o avanço da ciência
Para otimizar o software de rede para uma aplicação científica de computação intensiva, a equipe se concentrou em aumentar a velocidade de uma única classificação.
"Fizemos o código para uma única classificação MPI rodar mais rápido para que uma proliferação de classificações MPI não fosse necessária para lidar com a grande carga de comunicação presente para cada nó, "explicou Cristo.
O software dentro da classificação MPI explora o paralelismo encadeado disponível nos nós Xeon Phi. Paralelismo encadeado se refere à execução simultânea de vários processos, ou tópicos, que seguem as mesmas instruções enquanto compartilham alguns recursos de computação. Com o software otimizado, a equipe foi capaz de criar vários canais de comunicação em uma única classificação e conduzir esses canais usando diferentes threads.
O software MPI agora foi configurado para que os aplicativos científicos sejam executados mais rapidamente e aproveitem ao máximo o hardware de comunicação Intel Omni-Path. Mas depois de implementar o software, os membros da equipe encontraram outro desafio:em cada corrida, alguns nós inevitavelmente se comunicariam lentamente e impediriam os outros.
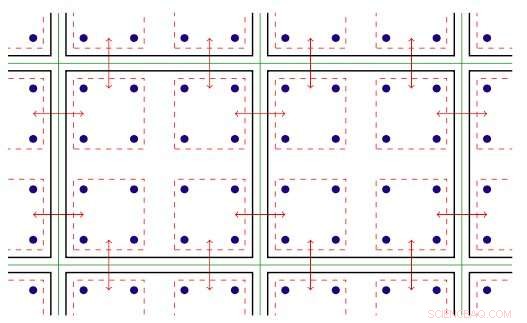
Ilustração bidimensional de paralelismo roscado. Chave:as linhas verdes separam os nós de computação físicos; linhas pretas separam as fileiras MPI; linhas vermelhas são os contextos de comunicação, com as setas denotando comunicação entre nós ou cópia de memória em um nó por meio do hardware Intel Omni-Path. Crédito:Laboratório Nacional de Brookhaven
Eles atribuíram esse problema à maneira como o Linux - o sistema operacional usado pela maioria das plataformas HPC - gerencia a memória. Em seu modo padrão, O Linux divide a memória em pequenos pedaços chamados páginas. Ao reconfigurar o Linux para usar páginas de memória grandes ("enormes"), eles resolveram o problema. Aumentar o tamanho da página significa que menos páginas são necessárias para mapear o espaço de endereço virtual que um aplicativo usa. Como resultado, a memória pode ser acessada muito mais rapidamente.
Com os aprimoramentos de software, os membros da equipe analisaram o desempenho da arquitetura Intel Omni-Path e dos nós de computação do processador Intel Xeon Phi instalados no cluster "Diamond" de trilho duplo da Intel e no cluster de trilho único de pesquisa distribuída usando computação avançada (DiRAC) no Reino Unido. Para sua análise, eles usaram duas classes diferentes de aplicações científicas:física de partículas e aprendizado de máquina. Para ambos os códigos de aplicativo, eles alcançaram desempenho próximo à velocidade do fio - a taxa máxima teórica de transferência de dados. Essa melhoria representa um aumento no desempenho da rede entre quatro e dez vezes o dos códigos originais.
"Por causa da estreita colaboração entre Brookhaven, Edimburgo, e Intel, essas otimizações foram disponibilizadas em todo o mundo em uma nova versão da implementação Intel Omni-Path MPI e um protocolo de prática recomendada para configurar o gerenciamento de memória do Linux, "disse Cristo." O fator de cinco acelerou a execução do código de física no computador Xeon Phi no Laboratório de Brookhaven - e no novo da Universidade de Edimburgo, computador "hipercubo" ainda maior de 800 nós da Hewlett Packard Enterprise - agora está sendo bem utilizado em estudos contínuos de questões fundamentais em física de partículas. "