Crédito CC0:domínio público
Uma equipe de pesquisadores da UC Santa Cruz desenvolveu recentemente uma nova abordagem de aprendizado de máquina para caracterizar a felicidade, chamado CruzAffect. A abordagem deles, apresentado em um artigo pré-publicado no arXiv, pode ser aplicado a diferentes modelos de classificação de conteúdo afetivo, incluindo classificadores tradicionais e redes neurais convolucionais de aprendizagem profunda (CNN).
Este estudo recente se baseia em pesquisas anteriores que exploraram como as pessoas transmitem afeto e felicidade na primeira pessoa. Em um estudo, os mesmos pesquisadores descobriram que as pessoas tendem a descrever situações, como 'meu amigo me comprou flores', ou 'Eu tenho uma multa de estacionamento', do qual outros humanos podem facilmente inferir suas reações afetivas implícitas. Eles concluíram que a semântica composicional pode fornecer fortes evidências do sentimento associado a um determinado evento.

Crédito:Wu et al.
Em outro estudo, os pesquisadores tentaram basear as descrições linguísticas dos eventos das pessoas em teorias de bem-estar e felicidade. Ao analisar um corpus de microblogs privados extraídos de um aplicativo chamado Echo, eles examinaram até que ponto diferentes relatos teóricos poderiam explicar a variação nas pontuações de felicidade que os usuários do Echo atribuíam aos eventos diários de suas vidas.
"É um desafio generalizar um evento afetivo e associá-lo a teorias de bem-estar, "Jiaqi Wu, um dos pesquisadores que realizou o estudo, disse TechXplore. "Em nossas pesquisas anteriores, percebemos que não existe uma teoria única que possa predizer o sentimento de todos os eventos afetivos. O objetivo de nosso trabalho recente foi identificar semânticas composicionais específicas que caracterizam o sentimento de eventos e tentar modelar a felicidade em um nível mais alto de generalização. Contudo, encontrar características genéricas para modelar o bem-estar continua sendo um desafio. "
O objetivo principal do estudo recente realizado por Wu e seus colegas foi investigar a eficácia de métodos tradicionais de aprendizado de máquina ricos em recursos e métodos de aprendizado profundo para classificação de conteúdo afetivo. Para alcançar isto, eles identificaram uma série de características que caracterizam a felicidade no conteúdo afetivo e as aplicaram a um classificador tradicional, Floresta XGBoosted, e uma CNN.
"Nosso projeto, chamado CruzAffect, inclui o desenvolvimento de dois modelos diferentes:um método de aprendizado de máquina tradicional (ou seja, floresta XGBoosted) e um CNN de aprendizado profundo com incorporação de GloVe, "Wu disse." Nós utilizamos recursos sintáticos, características emocionais, e recursos de perfil, e seu desempenho é estável para diferentes tarefas de classificação de conteúdo afetivo. "
Essencialmente, os pesquisadores avaliaram o desempenho de dois modelos diferentes de aprendizado de máquina para classificação de conteúdo afetivo (floresta XGBoosted e CNN), ambos analisaram o conteúdo com base nas características que haviam identificado anteriormente. Esses incluem:
Esses recursos permitiram aos pesquisadores descobrir indicadores essenciais de envolvimento social e controle que diferentes pessoas podem exercer durante os momentos felizes. Em seu estudo, eles treinaram o modelo XGBoosted e CNN com aprendizagem supervisionada em um conjunto de dados de 10, 000 trechos de texto rotulados. Eles também treinaram os modelos para gerar pseudo-rótulos para 70, 000 snippets não rotulados usando uma abordagem semi-supervisionada de bootstap, pois isso lhes permitiu ampliar seu conjunto de dados. Todos esses fragmentos textuais foram extraídos do banco de dados HappyDB.

Arquitetura CNN. Crédito:Wu et al.
"As descobertas significativas de nosso estudo incluem os padrões sintáticos interessantes que se repetem em diferentes domínios, "Disse Wu." Esses padrões linguísticos provavelmente estão associados a teorias de bem-estar. Também descobrimos que os recursos que incluem conhecimento especializado, como o dicionário LIWC pode melhorar o desempenho do modelo tradicional, bem como o modelo de aprendizagem profunda nas tarefas de classificação de conteúdo afetivo. "
Os pesquisadores avaliaram a floresta XGBoosted e os modelos CNN na classificação binária de agência e rótulos sociais, bem como na previsão multiclasse de rótulos de conceito. Suas avaliações produziram resultados promissores, sugerindo que as características por eles identificadas são particularmente eficazes para classificar o conteúdo afetivo. Embora o modelo baseado em CNN tenha um melhor desempenho em tarefas de classificação de várias classes, o modelo de aprendizado de máquina tradicional alcançou resultados comparáveis usando os recursos que eles haviam identificado anteriormente.
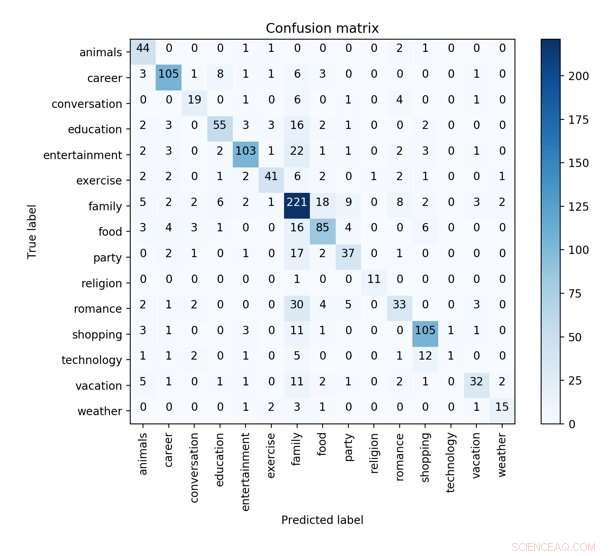
A matriz de confusão do melhor modelo da CNN com sintática, características emocionais e de perfil em validação cruzada de 10 vezes para prever as características dos conceitos. Crédito:Wu et al.
O estudo realizado por Wu e seus colegas revelou temas gerais que são recorrentes nas descrições de momentos felizes das pessoas. No futuro, suas descobertas podem informar o desenvolvimento de novos modelos para tarefas de classificação afetiva, permitindo que os pesquisadores prevejam efetivamente o bem-estar e a felicidade, analisando o conteúdo de fragmentos textuais.
"Agora explorarei a análise de eventos afetivos entre domínios, e investigar um modelo melhor para fundamentar as descrições linguísticas de eventos que os usuários vivenciam nas teorias de bem-estar e felicidade, "Disse Wu." Depois de compreender a relação entre o conteúdo afetivo e as teorias de bem-estar, podemos ser capazes de coletar eventos afetivos gerais altamente relacionados ao bem-estar. "

A equipe de pesquisadores que realizou o estudo. Crédito:Wu et al.
© 2019 Science X Network