Um modelo de pesquisadores do MIT e da Microsoft identifica casos em que carros autônomos "aprenderam" com exemplos de treinamento que não correspondem ao que realmente está acontecendo na estrada, que pode ser usado para identificar quais ações aprendidas podem causar erros do mundo real. Crédito:MIT News
Um novo modelo desenvolvido por pesquisadores do MIT e da Microsoft identifica instâncias em que sistemas autônomos "aprenderam" com exemplos de treinamento que não correspondem ao que realmente está acontecendo no mundo real. Os engenheiros podem usar este modelo para melhorar a segurança dos sistemas de inteligência artificial, como veículos sem motorista e robôs autônomos.
Os sistemas de IA que movem carros sem motorista, por exemplo, são treinados extensivamente em simulações virtuais para preparar o veículo para quase todos os eventos na estrada. Mas às vezes o carro comete um erro inesperado no mundo real porque ocorre um evento que deveria, mas não, alterar o comportamento do carro.
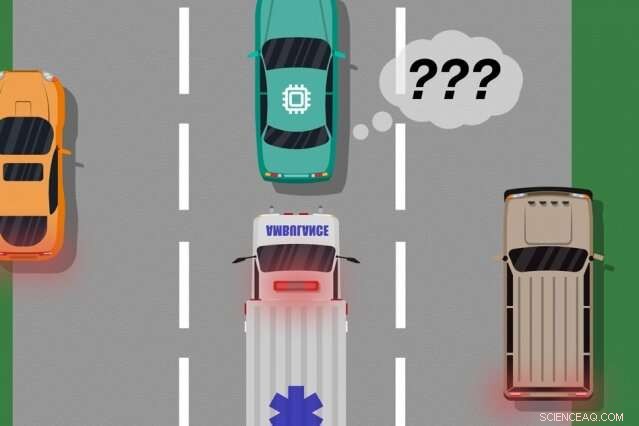
Considere um carro sem motorista que não foi treinado, e o mais importante, não tem os sensores necessários, para diferenciar entre cenários distintamente diferentes, como grande, carros brancos e ambulâncias com vermelho, luzes piscando na estrada. Se o carro está cruzando a rodovia e uma ambulância liga as sirenes, o carro pode não saber reduzir a velocidade e parar, porque não percebe a ambulância como diferente de um grande carro branco.
Em um par de artigos - apresentados na conferência de Agentes Autônomos e Sistemas Multiagentes do ano passado e na próxima conferência da Associação para o Avanço da Inteligência Artificial - os pesquisadores descrevem um modelo que usa dados humanos para descobrir esses "pontos cegos" de treinamento.
Tal como acontece com as abordagens tradicionais, os pesquisadores colocaram um sistema de IA por meio de treinamento de simulação. Mas então, um ser humano monitora de perto as ações do sistema enquanto ele age no mundo real, fornecer feedback quando o sistema fez, ou estava prestes a fazer, quaisquer erros. Os pesquisadores então combinam os dados de treinamento com os dados de feedback humano, e usar técnicas de aprendizado de máquina para produzir um modelo que identifica situações em que o sistema provavelmente precisa de mais informações sobre como agir corretamente.
Os pesquisadores validaram seu método usando videogames, com um humano simulado corrigindo o caminho aprendido de um personagem na tela. Mas o próximo passo é incorporar o modelo às abordagens tradicionais de treinamento e teste para carros e robôs autônomos com feedback humano.
"O modelo ajuda os sistemas autônomos a saberem melhor o que não sabem, "diz o primeiro autor Ramya Ramakrishnan, Pós-graduando no Laboratório de Ciência da Computação e Inteligência Artificial. "Muitas vezes, quando esses sistemas são implantados, suas simulações treinadas não correspondem à configuração do mundo real [e] eles podem cometer erros, como entrar em acidentes. A ideia é usar humanos para fazer a ponte entre a simulação e o mundo real, de uma forma segura, para que possamos reduzir alguns desses erros. "
Os co-autores em ambos os artigos são:Julie Shah, professor associado do Departamento de Aeronáutica e Astronáutica e chefe do Grupo de Robótica Interativa do CSAIL; e Ece Kamar, Debadeepta Dey, e Eric Horvitz, tudo da Microsoft Research. Besmira Nushi é um co-autor adicional no próximo artigo.
Recebendo feedback
Alguns métodos de treinamento tradicionais fornecem feedback humano durante as execuções de testes do mundo real, mas apenas para atualizar as ações do sistema. Essas abordagens não identificam pontos cegos, que pode ser útil para uma execução mais segura no mundo real.
A abordagem dos pesquisadores primeiro coloca um sistema de IA por meio de treinamento de simulação, onde produzirá uma "política" que essencialmente mapeia todas as situações para a melhor ação que pode realizar nas simulações. Então, o sistema será implantado no mundo real, onde humanos fornecem sinais de erro em regiões onde as ações do sistema são inaceitáveis.
Humanos podem fornecer dados de várias maneiras, como por meio de "demonstrações" e "correções". Em demonstrações, os atos humanos no mundo real, enquanto o sistema observa e compara as ações do ser humano com o que teria feito naquela situação. Para carros sem motorista, por exemplo, um humano controlaria manualmente o carro enquanto o sistema produz um sinal se seu comportamento planejado se desviar do comportamento humano. As correspondências e incompatibilidades com as ações humanas fornecem indicações ruidosas de onde o sistema pode estar agindo de forma aceitável ou inaceitável.
Alternativamente, o humano pode fornecer correções, com o ser humano monitorando o sistema conforme ele atua no mundo real. Um humano poderia sentar-se no banco do motorista enquanto o carro autônomo se dirige ao longo de sua rota planejada. Se as ações do carro estiverem corretas, o humano não faz nada. Se as ações do carro estiverem incorretas, Contudo, o humano pode assumir o volante, que envia um sinal de que o sistema não estava agindo de forma inaceitável naquela situação específica.
Depois que os dados de feedback do humano são compilados, o sistema tem essencialmente uma lista de situações e, para cada situação, vários rótulos dizendo que suas ações eram aceitáveis ou inaceitáveis. Uma única situação pode receber muitos sinais diferentes, porque o sistema percebe muitas situações como idênticas. Por exemplo, um carro autônomo pode ter cruzado ao lado de um carro grande muitas vezes sem diminuir a velocidade e parar. Mas, em apenas uma instância, uma ambulância, que aparece exatamente igual para o sistema, cruzeiros por. O carro autônomo não encosta e recebe um sinal de feedback de que o sistema realizou uma ação inaceitável.
"Nesse ponto, o sistema recebeu vários sinais contraditórios de um humano:alguns com um grande carro ao lado, e estava indo bem, e um onde havia uma ambulância exatamente no mesmo local, mas não estava bem. O sistema faz uma pequena observação de que fez algo errado, mas não sabe porque, "Ramakrishnan diz." Porque o agente está recebendo todos esses sinais contraditórios, a próxima etapa é compilar as informações a serem perguntadas, 'Qual a probabilidade de cometer um erro nesta situação em que recebi esses sinais confusos?' "
Agregação inteligente
O objetivo final é que essas situações ambíguas sejam rotuladas como pontos cegos. Mas isso vai além de simplesmente contabilizar as ações aceitáveis e inaceitáveis para cada situação. Se o sistema executou ações corretas nove vezes em 10 na situação de ambulância, por exemplo, uma votação por maioria simples rotularia essa situação como segura.
"Mas porque as ações inaceitáveis são muito mais raras do que as ações aceitáveis, o sistema acabará por aprender a prever todas as situações como seguras, o que pode ser extremamente perigoso, "Ramakrishnan diz.
Para esse fim, os pesquisadores usaram o algoritmo Dawid-Skene, um método de aprendizado de máquina usado comumente para crowdsourcing para lidar com o ruído do rótulo. O algoritmo recebe como entrada uma lista de situações, cada um tendo um conjunto de rótulos ruidosos "aceitável" e "inaceitável". Em seguida, ele agrega todos os dados e usa alguns cálculos de probabilidade para identificar padrões nos rótulos de pontos cegos previstos e padrões para situações seguras previstas. Usando essas informações, ele produz um único rótulo agregado "seguro" ou "ponto cego" para cada situação, juntamente com seu nível de confiança nesse rótulo. Notavelmente, o algoritmo pode aprender em uma situação em que pode ter, por exemplo, teve desempenho aceitável em 90 por cento do tempo, a situação ainda é ambígua o suficiente para merecer um "ponto cego".
No fim, o algoritmo produz um tipo de "mapa de calor, "em que cada situação do treinamento original do sistema é atribuída com probabilidade baixa a alta de ser um ponto cego para o sistema.
"Quando o sistema é implantado no mundo real, ele pode usar esse modelo aprendido para agir com mais cautela e inteligência. Se o modelo aprendido prevê que um estado é um ponto cego com alta probabilidade, o sistema pode consultar um ser humano para a ação aceitável, permitindo uma execução mais segura, "Ramakrishnan diz.
Esta história foi republicada por cortesia do MIT News (web.mit.edu/newsoffice/), um site popular que cobre notícias sobre pesquisas do MIT, inovação e ensino.