p Um sistema de "visão computacional" desenvolvido na UCLA pode identificar objetos com base apenas em vislumbres parciais, como usar esses trechos de fotos de uma motocicleta. Crédito:Universidade da Califórnia, Los Angeles
p Um sistema de "visão computacional" desenvolvido na UCLA pode identificar objetos com base apenas em vislumbres parciais, como usar esses trechos de fotos de uma motocicleta. Crédito:Universidade da Califórnia, Los Angeles
p Os engenheiros da UCLA e da Universidade de Stanford demonstraram um sistema de computador que pode descobrir e identificar os objetos do mundo real que "vê" com base no mesmo método de aprendizagem visual que os humanos usam. p O sistema é um avanço em um tipo de tecnologia chamada "visão computacional, "que permite aos computadores ler e identificar imagens visuais. Pode ser um passo importante em direção aos sistemas gerais de inteligência artificial - computadores que aprendem por conta própria, são intuitivos, tomar decisões com base no raciocínio e interagir com os humanos de uma forma muito mais humana. Embora os atuais sistemas de visão computacional de IA sejam cada vez mais poderosos e capazes, eles são específicos da tarefa, o que significa que sua capacidade de identificar o que vêem é limitada pelo quanto foram treinados e programados por humanos.
p Mesmo os melhores sistemas de visão por computador de hoje não podem criar uma imagem completa de um objeto depois de ver apenas algumas partes dele - e os sistemas podem ser enganados ao ver o objeto em um ambiente desconhecido. Os engenheiros pretendem fazer sistemas de computador com essas habilidades - assim como os humanos podem entender que estão olhando para um cachorro, mesmo que o animal esteja escondido atrás de uma cadeira e apenas as patas e a cauda sejam visíveis. Humanos, claro, também pode facilmente intuir onde a cabeça do cão e o resto do seu corpo estão, mas essa habilidade ainda foge da maioria dos sistemas de inteligência artificial.
p Os sistemas de visão computacional atuais não são projetados para aprender por conta própria. Eles devem ser treinados exatamente no que aprender, geralmente revisando milhares de imagens nas quais os objetos que eles estão tentando identificar são rotulados para eles. Computadores, claro, também não consegue explicar sua razão para determinar o que o objeto em uma foto representa:sistemas baseados em IA não constroem uma imagem interna ou um modelo de senso comum de objetos aprendidos da maneira que os humanos fazem.
p O novo método dos engenheiros, descrito no
Anais da Academia Nacional de Ciências , mostra uma maneira de contornar essas deficiências.
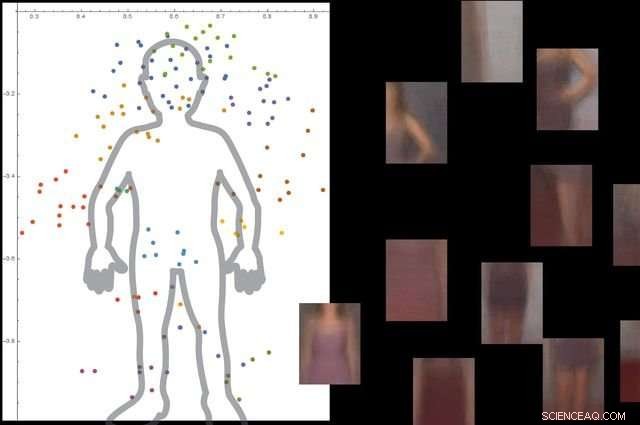 p O sistema entende o que é um corpo humano observando milhares de imagens com pessoas, e, em seguida, ignorando objetos de fundo não essenciais. Crédito:Universidade da Califórnia, Los Angeles
p O sistema entende o que é um corpo humano observando milhares de imagens com pessoas, e, em seguida, ignorando objetos de fundo não essenciais. Crédito:Universidade da Califórnia, Los Angeles
p A abordagem é composta de três grandes etapas. Primeiro, o sistema divide uma imagem em pequenos pedaços, que os pesquisadores chamam de "viewlets". Segundo, o computador aprende como esses viewlets se encaixam para formar o objeto em questão. E finalmente, olha o que outros objetos estão na área circundante, e se as informações sobre esses objetos são ou não relevantes para descrever e identificar o objeto principal.
p Para ajudar o novo sistema a "aprender" mais como os humanos, os engenheiros decidiram imergi-lo em uma réplica da internet do ambiente em que os humanos vivem.
p "Felizmente, a internet oferece duas coisas que ajudam um sistema de visão por computador inspirado no cérebro a aprender da mesma maneira que os humanos, "disse Vwani Roychowdhury, um professor de engenharia elétrica e da computação da UCLA e o principal investigador do estudo. "Um deles é uma riqueza de imagens e vídeos que retratam os mesmos tipos de objetos. O segundo é que esses objetos são mostrados de muitas perspectivas - obscurecidas, olho do pássaro, de perto - e eles são colocados em todos os diferentes tipos de ambientes. "
p Para desenvolver a estrutura, os pesquisadores extraíram ideias da psicologia cognitiva e da neurociência.
p "Começando como crianças, aprendemos o que é algo porque vemos muitos exemplos disso, em muitos contextos, "Roychowdhury disse." Esse aprendizado contextual é uma característica fundamental de nossos cérebros, e nos ajuda a construir modelos robustos de objetos que fazem parte de uma visão de mundo integrada, onde tudo está funcionalmente conectado. "
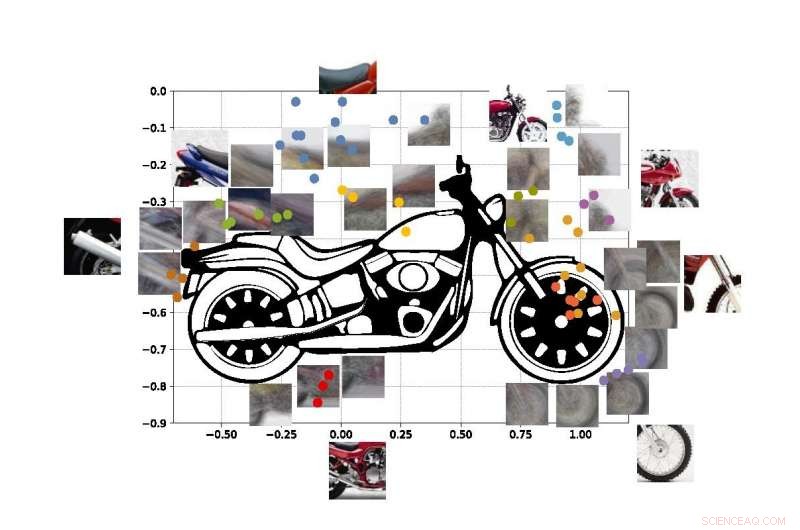 p Os pontos coloridos na figura mostram as coordenadas estimadas dos centros de alguns dos visores em nossa motocicleta SUVM. Cada representação de viewlet é uma composição de vistas / patches de exemplo que têm aparências semelhantes. Crédito:Lichao Chen, Tianyi Wang, e Vwani Roychowdhury (Universidade da Califórnia, Los Angeles).
p Os pontos coloridos na figura mostram as coordenadas estimadas dos centros de alguns dos visores em nossa motocicleta SUVM. Cada representação de viewlet é uma composição de vistas / patches de exemplo que têm aparências semelhantes. Crédito:Lichao Chen, Tianyi Wang, e Vwani Roychowdhury (Universidade da Califórnia, Los Angeles).
p Os pesquisadores testaram o sistema com cerca de 9, 000 imagens, cada um mostrando pessoas e outros objetos. A plataforma foi capaz de construir um modelo detalhado do corpo humano sem orientação externa e sem que as imagens fossem rotuladas.
p Os engenheiros fizeram testes semelhantes usando imagens de motocicletas, carros e aviões. Em todos os casos, seu sistema funcionou melhor ou pelo menos tão bem quanto os sistemas tradicionais de visão por computador que foram desenvolvidos com muitos anos de treinamento.
p O co-autor sênior do estudo é Thomas Kailath, um professor emérito de engenharia elétrica em Stanford que foi orientador de doutorado de Roychowdhury na década de 1980. Outros autores são ex-alunos de doutorado da UCLA, Lichao Chen (agora um engenheiro de pesquisa do Google) e Sudhir Singh (que fundou uma empresa que constrói companheiros de ensino robóticos para crianças).
p Singh, Roychowdhury e Kailath trabalharam juntos anteriormente para desenvolver um dos primeiros motores de busca visual automatizados para moda, o StileEye agora fechado, que deu origem a algumas das idéias básicas por trás da nova pesquisa.