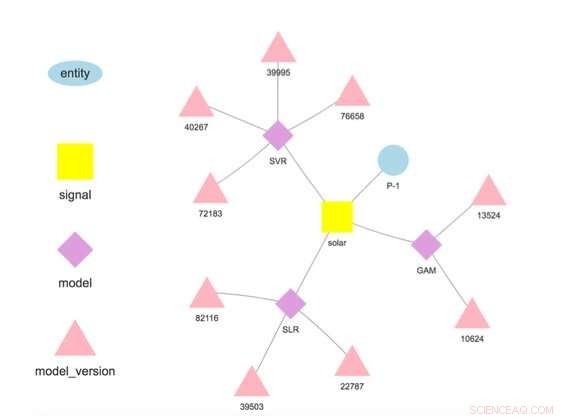
 p Figura 1. Hierarquia do modelo para uma entidade e sinal selecionados. Crédito:IBM
p Figura 1. Hierarquia do modelo para uma entidade e sinal selecionados. Crédito:IBM
p Esta semana, na Conferência Internacional de Mineração de Dados, O cientista da IBM Research-Ireland Francesco Fusco demonstrou o IBM Research Castor, um sistema para gerenciar dados e modelos de séries temporais em escala e na nuvem. Os negócios de hoje dependem de previsões. Seja um palpite do que pensamos que vai acontecer ou o produto de uma análise cuidadosamente aprimorada, temos uma imagem do que vai acontecer e agimos de acordo. O IBM Research Castor é para empresas orientadas a IoT que precisam de centenas ou milhares de previsões diferentes para séries temporais. Embora o modelo para uma previsão individual possa ser pequeno, acompanhar a proveniência e o desempenho deste número de modelos pode ser um desafio. Em contraste com os casos baseados em IA usando um pequeno número de grandes modelos para processamento de imagem ou linguagem natural, este trabalho visa as aplicações IoT que precisam de um grande número de modelos menores. p Nosso sistema fornece um conjunto rico, mas seletivo de recursos para dados e modelos de séries temporais. Ele ingere dados de dispositivos IoT ou outras fontes. Ele fornece acesso aos dados usando semântica, permitindo que os usuários recuperem dados como este:getTimeseries (myServer, "Store1234", "receita por hora").
p Ele armazena modelos escritos em R ou Python para treinamento e pontuação. Cada modelo está associado a uma entidade que descreve a origem dos dados, como "Store1234" acima, e um sinal que descreve o que é medido, como "receita por hora". Os modelos são treinados e pontuados em frequências definidas pelo usuário, e em contraste com muitas outras ofertas, as previsões são armazenadas automaticamente.
p Os cientistas de dados implantam modelos implementando um fluxo de trabalho de quatro etapas:
- Carregue os dados para treinamento ou pontuação de fontes de dados relevantes;
- Transforme esses dados em um quadro de dados para treinamento de modelo ou pontuação;
- Treine o modelo para obter uma versão adequada para fazer previsões; e
- Pontue o modelo para prever quantidades de interesse.
p Assim que o modelo for implantado, o sistema realiza o treinamento e a pontuação, armazenar automaticamente o modelo treinado e os resultados da previsão. Os dados usados no treinamento e pontuação não precisam se originar na plataforma, permitindo que os modelos usem dados de várias fontes. Na verdade, esta é a principal motivação de nosso trabalho - fazer previsões de valor agregado com base em várias fontes de dados. Por exemplo, uma empresa pode combinar alguns de seus próprios dados com dados adquiridos de terceiros, como previsões do tempo, para prever uma quantidade de interesse.
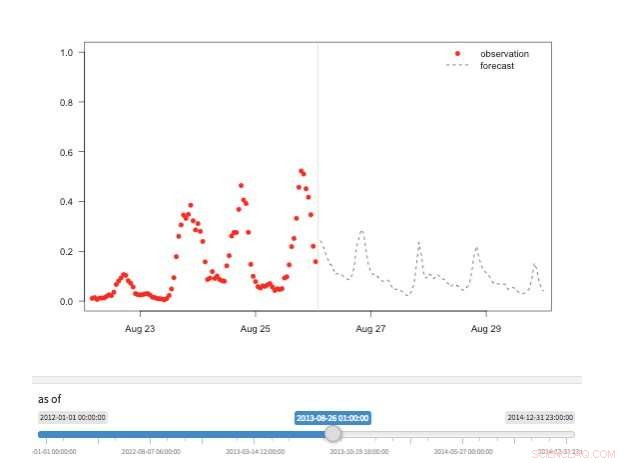 p Figura 2. Visualização da “máquina do tempo” mostrando as observações e previsões disponíveis para diferentes pontos da história. Crédito:IBM
p Figura 2. Visualização da “máquina do tempo” mostrando as observações e previsões disponíveis para diferentes pontos da história. Crédito:IBM
p Nosso sistema armazena modelos separados dos parâmetros de configuração e tempo de execução. Essa separação permite a alteração de alguns detalhes de um modelo, como a chave de API para acessar dados de terceiros ou a frequência de pontuação, sem redistribuição. Vários modelos para a mesma variável de destino são suportados e incentivados para permitir comparações de previsões de diferentes algoritmos. Os modelos podem ser encadeados de modo que a saída de um modelo forme a entrada para outro como em um conjunto. Um modelo treinado em um conjunto de dados específico representa uma versão do modelo, que também é rastreado. Assim, é possível estabelecer a proveniência dos modelos e previsões (Figura 1).
p Várias visualizações estão disponíveis para explorar os valores de previsão. É claro que os próprios valores podem ser recuperados e visualizados. Também oferecemos suporte a uma visualização de "máquina do tempo" mostrando as últimas previsões e observações (Figura 2). Nesta visão interativa, o usuário pode selecionar diferentes pontos no histórico e ver quais informações estavam disponíveis no momento. Também apoiamos uma visão da evolução das previsões mostrando previsões sucessivas para o mesmo ponto no tempo (Figura 3). Desta forma, os usuários podem ver como as previsões mudaram conforme o tempo alvo se aproximava.
p Sob o capô, O IBM Research Castor faz uso intenso de computação sem servidor para fornecer elasticidade de recursos e controle de custos. As implantações típicas veem modelos treinados todas as semanas ou todos os meses e pontuados a cada hora. No momento do treinamento ou pontuação, uma função sem servidor é criada para cada modelo, permitindo que centenas de modelos treinem ou pontuem em paralelo no momento desejado. Depois que esse trabalho acabar, o recurso de computação desaparece até que seja necessário novamente. Em um fluxo de trabalho mais convencional, máquinas virtuais ou contêineres de nuvem ficam ociosos quando não estão em uso, mas ainda assim atraem custos.
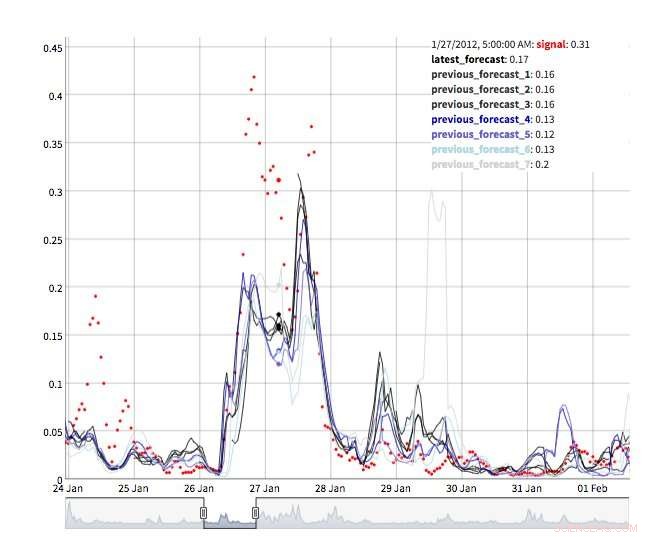 p Figura 3. Evolução da previsão. Crédito:IBM
p Figura 3. Evolução da previsão. Crédito:IBM
p O IBM Research Castor é implementado de forma nativa na IBM Cloud usando os serviços mais recentes, como o DashDB da IBM, Compor, Cloud Functions, e Kubernetes para fornecer um sistema robusto e confiável. Com uma conta autorizada no IBM Cloud, O IBM Research Castor é implantado em questão de minutos, tornando-o ideal para a prova de conceito, bem como para projetos de execução mais longa. Pacotes de cliente / SDKs para Python e R são fornecidos para que os cientistas de dados possam começar a trabalhar rapidamente em um ambiente familiar e as equipes de visualização podem aproveitar estruturas familiares como Django e Shiny. Se eles não se adequarem à sua aplicação, a API de mensagens baseada em JSON também está disponível. p
Esta história foi republicada por cortesia da IBM Research. Leia a história original aqui.