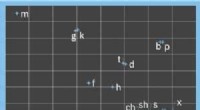
O novo modelo mede distâncias entre palavras com significados semelhantes em "embeddings de palavras, ”E, em seguida, alinha as palavras em ambos os embeddings que estão mais intimamente relacionados por distâncias relativas, o que significa que é mais provável que sejam traduções diretas um do outro. Crédito:Massachusetts Institute of Technology
Os pesquisadores do MIT desenvolveram um novo modelo de tradução de linguagem "não supervisionado" - o que significa que funciona sem a necessidade de anotações e orientações humanas - que pode levar a um processo mais rápido, traduções mais eficientes, baseadas em computador, de muito mais idiomas.
Sistemas de tradução do Google, Facebook, e a Amazon exigem modelos de treinamento para procurar padrões em milhões de documentos, como documentos legais e políticos, ou artigos de notícias - que foram traduzidos em várias línguas por humanos. Com novas palavras em um idioma, eles podem então encontrar as palavras e frases correspondentes no outro idioma.
Mas esses dados translacionais são demorados e difíceis de coletar, e simplesmente pode não existir para muitos dos 7, 000 línguas faladas em todo o mundo. Recentemente, pesquisadores têm desenvolvido modelos "monolíngues" que fazem traduções entre textos em duas línguas, mas sem informações translacionais diretas entre os dois.
Em um artigo apresentado esta semana na Conferência sobre Métodos Empíricos em Processamento de Linguagem Natural, pesquisadores do Laboratório de Ciência da Computação e Inteligência Artificial do MIT (CSAIL) descrevem um modelo que é executado de forma mais rápida e eficiente do que esses modelos monolíngues.
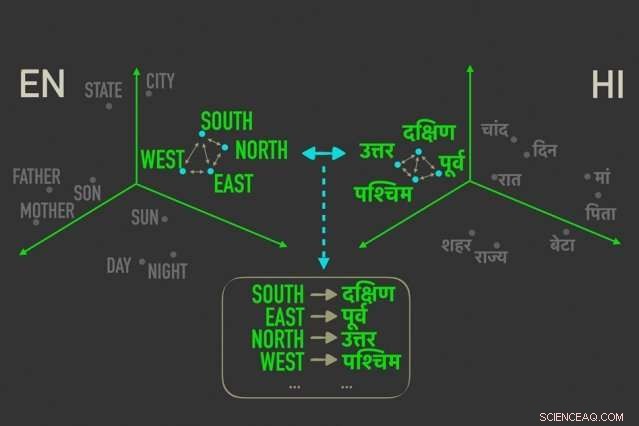
O modelo alavanca uma métrica nas estatísticas, chamada distância Gromov-Wasserstein, que essencialmente mede distâncias entre pontos em um espaço computacional e os associa a pontos com distâncias semelhantes em outro espaço. Eles aplicam essa técnica a "embeddings de palavras" de duas línguas, que são palavras representadas como vetores - basicamente, matrizes de números - com palavras de significados semelhantes agrupados mais próximos. Ao fazer isso, o modelo alinha rapidamente as palavras, ou vetores, em ambos os embeddings que estão mais intimamente relacionados por distâncias relativas, o que significa que provavelmente são traduções diretas.
Em experimentos, o modelo dos pesquisadores teve um desempenho tão preciso quanto os modelos monolíngues de última geração - e às vezes com mais precisão - mas muito mais rapidamente e usando apenas uma fração do poder de computação.
"O modelo vê as palavras nas duas línguas como conjuntos de vetores, e mapeia [esses vetores] de um conjunto para o outro essencialmente preservando as relações, "diz o co-autor do jornal, Tommi Jaakkola, um pesquisador do CSAIL e o professor Thomas Siebel do Departamento de Engenharia Elétrica e Ciência da Computação e do Institute for Data, Sistemas, e sociedade. "A abordagem pode ajudar a traduzir linguagens ou dialetos com poucos recursos, contanto que eles venham com conteúdo monolíngue suficiente. "
O modelo representa um passo em direção a um dos principais objetivos da tradução automática, que é um alinhamento de palavras totalmente não supervisionado, diz o primeiro autor David Alvarez-Melis, um CSAIL Ph.D. aluno:"Se você não tiver nenhum dado que corresponda a dois idiomas ... você pode mapear dois idiomas e, usando essas medidas de distância, alinhe-os. "
Relacionamentos são mais importantes
O alinhamento de embeddings de palavras para tradução automática não supervisionada não é um conceito novo. Um trabalho recente treina redes neurais para combinar vetores diretamente em embeddings de palavras, ou matrizes, de duas línguas juntas. Mas esses métodos requerem muitos ajustes durante o treinamento para obter os alinhamentos exatamente corretos, o que é ineficiente e demorado.
Medir e combinar vetores com base em distâncias relacionais, por outro lado, é um método muito mais eficiente que não requer muitos ajustes. Não importa onde os vetores de palavras caem em uma determinada matriz, a relação entre as palavras, significando suas distâncias, permanecerá o mesmo. Por exemplo, o vetor para "pai" pode cair em áreas completamente diferentes em duas matrizes. Mas os vetores para "pai" e "mãe" provavelmente sempre estarão próximos.
"Essas distâncias são invariáveis, "Alvarez-Melis diz." Olhando à distância, e não as posições absolutas dos vetores, então você pode pular o alinhamento e ir diretamente para a correspondência das correspondências entre os vetores. "
É aí que Gromov-Wasserstein vem a calhar. A técnica tem sido usada na ciência da computação para, dizer, ajudando a alinhar os pixels da imagem no design gráfico. Mas a métrica parecia "feita sob medida" para o alinhamento de palavras, Alvarez-Melis diz:"Se houver pontos, ou palavras, que estão juntos em um espaço, Gromov-Wasserstein vai tentar encontrar automaticamente o grupo de pontos correspondente no outro espaço. "
Para treinamento e teste, os pesquisadores usaram um conjunto de dados de embeddings de palavras publicamente disponíveis, chamado FASTTEXT, com 110 pares de idiomas. Nestes embeddings, e outros, palavras que aparecem cada vez com mais frequência em contextos semelhantes têm vetores muito próximos. "Mãe" e "pai" geralmente estarão próximos, mas ambos mais distantes, dizer, "casa."
Fornecendo uma "tradução suave"
O modelo observa vetores que estão intimamente relacionados, mas diferentes dos outros, e atribui uma probabilidade de que os vetores com distâncias semelhantes na outra incorporação corresponderão. É como uma "tradução suave, "Alvarez-Melis diz, "porque em vez de apenas retornar uma tradução de uma única palavra, diz a você 'este vetor, ou palavra, tem uma correspondência forte com esta palavra, ou palavras, no outro idioma. '"
Um exemplo seria nos meses do ano, que aparecem juntos em muitos idiomas. O modelo verá um cluster de 12 vetores agrupados em um embedding e um cluster notavelmente semelhante no outro embedding. "A modelo não sabe que são meses, "Alvarez-Melis diz." Ele só sabe que há um aglomerado de 12 pontos que se alinha com um aglomerado de 12 pontos na outra língua, mas eles são diferentes do resto das palavras, então eles provavelmente combinam bem. Ao encontrar essas correspondências para cada palavra, em seguida, alinha todo o espaço simultaneamente. "
Os pesquisadores esperam que o trabalho sirva como uma "verificação de viabilidade, "Jaakkola diz, para aplicar o método Gromov-Wasserstein a sistemas de tradução automática para rodar mais rápido, mais eficientemente, e tenha acesso a muitos outros idiomas.
Adicionalmente, uma possível vantagem do modelo é que ele produz automaticamente um valor que pode ser interpretado como quantificador, em uma escala numérica, a semelhança entre as línguas. Isso pode ser útil para estudos lingüísticos, dizem os pesquisadores. O modelo calcula a distância de todos os vetores uns dos outros em dois embeddings, que depende da estrutura da frase e de outros fatores. Se os vetores forem todos realmente próximos, eles vão pontuar perto de 0, e quanto mais distantes eles estão, quanto maior a pontuação. Línguas românicas semelhantes, como francês e italiano, por exemplo, pontuação próxima a 1, enquanto o chinês clássico pontua entre 6 e 9 em outras línguas importantes.
"Isso te dá um bom, um número simples de como as línguas são semelhantes ... e pode ser usado para extrair ideias sobre as relações entre as línguas, "Alvarez-Melis diz.
Esta história foi republicada por cortesia do MIT News (web.mit.edu/newsoffice/), um site popular que cobre notícias sobre pesquisas do MIT, inovação e ensino.