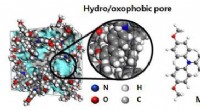
Visualização que representa a codificação fonética das iniciais Pinyin. Crédito:IBM
Realizar a ginástica mental de fazer a distinção fenética entre palavras e frases como "Ouvi" a "Estou aqui" ou "Não consigo, mas muito" a "Não consigo costurar botões, "é familiar para quem já encontrou mensagens de texto corrigidas automaticamente, posts punny de mídia social e assim por diante. Embora à primeira vista possa parecer que a semelhança fonética só pode ser quantificada para palavras audíveis, este problema está frequentemente presente em espaços puramente textuais.
As abordagens de IA para analisar e compreender o texto exigem uma entrada limpa, o que, por sua vez, implica uma quantidade necessária de pré-processamento de dados brutos. Homófonos e sinófonos incorretos, se usado por engano ou por brincadeira, deve ser corrigido como qualquer outra forma de erro ortográfico ou gramatical. No exemplo acima, transformar com precisão as palavras "ouvir" e "então" em suas contrapartes corretas foneticamente semelhantes requer uma representação robusta de semelhança fonética entre pares de palavras.
A maioria dos algoritmos de semelhança fonética são motivados por casos de uso do inglês, e projetado para idiomas indo-europeus. Contudo, muitos idiomas, como chinês, têm uma estrutura fonética diferente. O som da fala de um caractere chinês é representado por uma única sílaba em pinyin, o sistema oficial de romanização dos chineses. Uma sílaba Pinyin consiste em:uma inicial (opcional) (como 'b', 'zh', ou 'x'), um final (como 'a', 'ou', 'wai', ou 'yuan') e tom (dos quais são cinco). Mapear esses sons da fala para fonemas do inglês resulta em uma representação bastante imprecisa, e o uso de algoritmos de similaridade fonética indo-européia agrava ainda mais o problema. Por exemplo, dois algoritmos bem conhecidos, Soundex e Double Metaphone, indexe consoantes enquanto ignora vogais (e não tenha conceito de tons).
Pinyin
Como uma sílaba Pinyin representa uma média de sete caracteres chineses diferentes, a preponderância de homófonos é ainda maior do que em inglês. Enquanto isso, o uso de Pinyin para criação de texto é extremamente prevalente em aplicativos móveis e de bate-papo, tanto ao usar fala para texto quanto ao digitar diretamente, pois é mais prático inserir uma sílaba Pinyin e selecionar o caractere pretendido. Como resultado, erros de entrada com base fonética são extremamente comuns, destacando a necessidade de um algoritmo de similaridade fonética muito preciso que possa ser usado para remediar erros.
Motivado por este caso de uso, que generaliza para muitas outras línguas que não se encaixam facilmente no molde fonético do inglês, desenvolvemos uma abordagem para aprender uma codificação fonética n-dimensional para chinês, Uma característica importante do Pinyin é que os três componentes de uma sílaba (inicial, final e tom) devem ser considerados e comparados independentemente. Por exemplo, a semelhança fonética das finais "ie" e "ue" é idêntica nos pares Pinyin {"xie2, "" xue2 "} e {" lie2, "" lue2 "}, apesar das várias iniciais. Assim, a semelhança de um par de sílabas pinyin é uma agregação das semelhanças entre suas iniciais, finais, e tons.
Contudo, restringir artificialmente o espaço de codificação para uma dimensão baixa (por exemplo, indexando cada inicial para um único categórico, ou mesmo valor numérico) limita a precisão de captura das variações fonéticas. O correto, A abordagem baseada em dados é, portanto, aprender organicamente uma codificação de dimensionalidade apropriada. O modelo de aprendizagem deriva codificações precisas considerando conjuntamente as características linguísticas Pinyin, como local de articulação e métodos de pronúncia, bem como conjuntos de dados de treinamento anotados de alta qualidade.
Demonstrando uma melhoria de 7,5X em relação às abordagens de similaridade fonética existentes
As codificações aprendidas podem, portanto, ser usadas para, por exemplo, aceitar uma palavra como entrada e retornar uma lista classificada de palavras foneticamente semelhantes (classificadas por semelhança fonética decrescente). A classificação é importante porque os aplicativos posteriores não serão escalonados para considerar um grande número de candidatos substitutos para cada palavra, especialmente quando executado em tempo real. Como um exemplo do mundo real, avaliamos nossa abordagem para gerar uma lista classificada de candidatos para cada uma das 350 palavras chinesas retiradas de um conjunto de dados de mídia social, e demonstrou uma melhora de 7,5X em relação às abordagens de similaridade fonética existentes.
Esperamos que as melhorias produzidas por este trabalho para representar a similaridade fonética específica do idioma contribuam para a qualidade de vários aplicativos de processamento de linguagem natural multilíngue. Este trabalho, parte do projeto IBM Research SystemT, foi recentemente apresentado na Conferência SIGNLL 2018 sobre Aprendizagem de Linguagem Natural Computacional, e o modelo chinês pré-treinado está disponível para os pesquisadores usarem como um recurso na construção de chatbots, aplicativos de mensagens, verificadores ortográficos e quaisquer outros aplicativos relevantes.