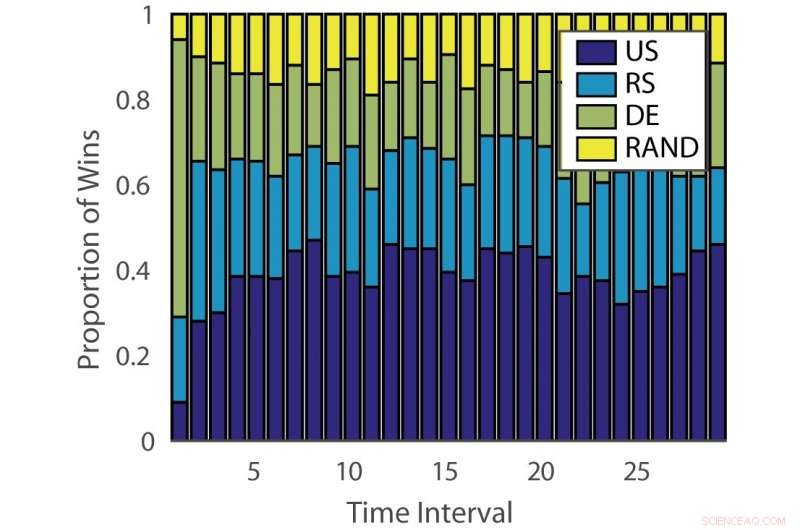
Proporção de vitórias:“ILPD”. Crédito:Pang et al.
Pesquisadores da Universidade de Edimburgo, A University College London (UCL) e o Nara Institute of Science and Technology desenvolveram uma nova abordagem de aprendizado ativo baseado em um bandido multi-armado não estacionário e um algoritmo de aconselhamento especializado. Seu método, apresentado em um artigo pré-publicado no arXiv, poderia reduzir o tempo e o esforço investidos na anotação manual de dados.
"O aprendizado de máquina supervisionado convencional consome muitos dados, e dados rotulados podem ser um gargalo quando a anotação de dados é cara, "Timothy Hospedales, um dos pesquisadores que realizaram o estudo disse ao Tech Xplore. "O aprendizado ativo oferece suporte ao aprendizado supervisionado, prevendo os pontos de dados mais informativos a serem anotados para que bons modelos possam ser treinados com um orçamento de anotação reduzido."
O aprendizado ativo é uma área específica do aprendizado de máquina em que um algoritmo de aprendizado pode escolher ativamente os dados com os quais deseja aprender. Isso normalmente resulta em melhor desempenho, com conjuntos de dados de treinamento significativamente menores.
Os pesquisadores desenvolveram uma variedade de algoritmos de aprendizagem ativa que podem reduzir os custos de anotação, Mas por enquanto, nenhuma dessas soluções provou ser eficaz para todos os problemas. Outros estudos, portanto, usaram algoritmos de bandit para identificar o melhor algoritmo de aprendizado ativo para um determinado conjunto de dados.
"O termo 'bandido' refere-se a uma máquina caça-níqueis multi-bandidos, que é uma abstração matemática conveniente para problemas de exploração / exploração, "Hospedales explicou." Um algoritmo de bandido encontra um bom equilíbrio entre o esforço gasto em explorar todas as máquinas caça-níqueis para descobrir qual está pagando mais, com esforço gasto na exploração da melhor máquina caça-níqueis encontrada até agora. "
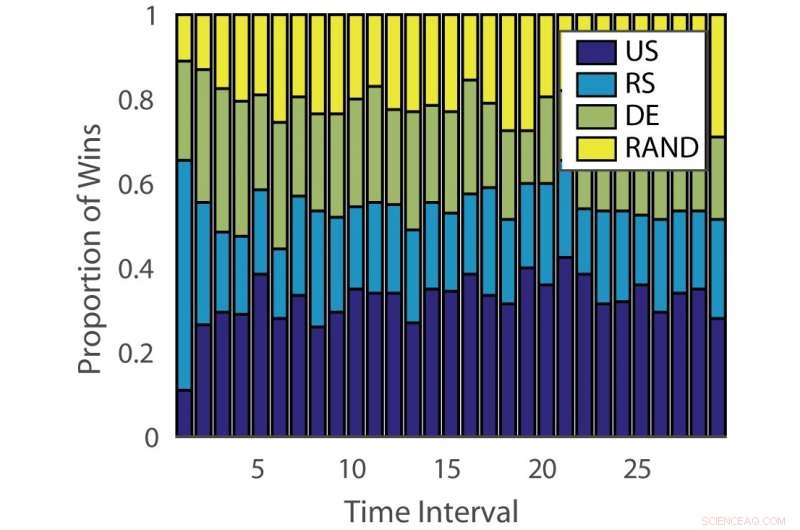
Proporção de vitórias:“alemão”. Crédito:Pang et al.
A eficácia dos algoritmos de aprendizagem ativa varia entre os problemas e ao longo do tempo em diferentes estágios de aprendizagem. Essa observação é análoga a jogar caça-níqueis, onde a probabilidade de pagamento muda com o tempo.
"O objetivo do nosso estudo era desenvolver um novo algoritmo de bandido que melhora o desempenho levando em consideração este aspecto do problema de aprendizagem ativa, "Disse Hospedales.
Para lidar com essa limitação, os pesquisadores propuseram um aluno ativo de conjunto dinâmico (DEAL) baseado em um bandido não estacionário. Este aluno constrói uma estimativa da eficácia de cada algoritmo de aprendizagem ativa online, com base na recompensa (precisão ponderada por importância) obtida após cada anotação de dados.
"Ele faz isso usando a preferência expressa para aquele ponto por cada algoritmo de aprendizado ativo, "Kunkun Pang, outro pesquisador que realizou o estudo, disse Tech Xplore. "Para lidar com a questão da mudança na eficácia dos alunos ativos ao longo do tempo, periodicamente, reiniciamos o algoritmo de aprendizagem para atualizar sua preferência de aluno ativo. Com esse recurso, se o algoritmo de aprendizagem ativa mais eficaz muda entre os estágios iniciais e finais de aprendizagem, podemos nos adaptar rapidamente a essa mudança. "
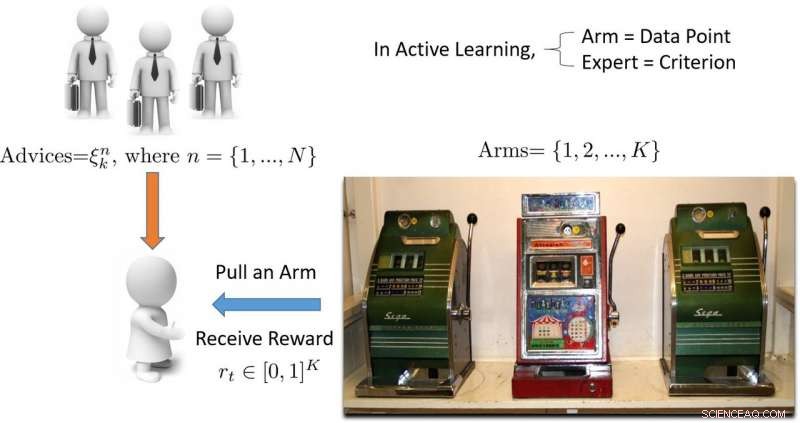
Ilustração da abordagem de aprendizagem ativa baseada em bandidos multi-armados. Crédito:Pang et al.
Os pesquisadores testaram sua abordagem em 13 conjuntos de dados populares, alcançando resultados altamente encorajadores. Seu algoritmo DEAL tem uma garantia de desempenho matemática, o que significa que há um alto grau de confiança em quão bem funcionará.
"A garantia está relacionada ao desempenho do nosso algoritmo, que é o de um oráculo ideal que sempre sabe a escolha certa para o aluno ativo, "Hospedales explicou." Ele fornece um limite sobre a lacuna de desempenho entre esse algoritmo de melhor caso e o nosso. "
A avaliação empírica realizada por Hospedales e seus colegas confirmou que seu algoritmo DEAL melhora o desempenho do aprendizado ativo em um conjunto de benchmarks. Ele faz isso identificando continuamente o algoritmo de aprendizado ativo mais eficaz para diferentes tarefas e em diferentes estágios de treinamento.
"Hoje, enquanto a aprendizagem ativa é atraente, seu impacto nas práticas de aprendizado de máquina é limitado devido ao incômodo de combinar algoritmos com problemas e estágios de aprendizagem, "Disse Hospedales." O DEAL elimina essa dificuldade e fornece uma abordagem para lidar com muitos problemas e todos os estágios de aprendizagem. Ao tornar o aprendizado ativo mais fácil de usar, esperamos que tenha um impacto maior na redução do custo de anotação na prática de aprendizado de máquina. "
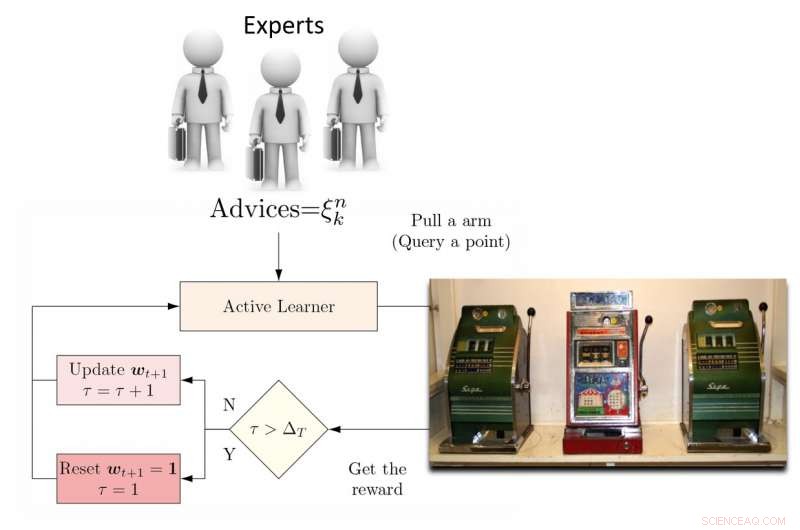
Ilustração do algoritmo DEAL REXP4. Crédito:Pang et al.
Apesar dos resultados muito promissores, a técnica idealizada pelos pesquisadores ainda apresenta uma limitação significativa. A DEAL faz todo o aprendizado dentro de um único problema e isso resulta em uma 'inicialização a frio, 'significando que o algoritmo aborda todos os novos problemas com uma folha em branco.
"Em trabalho contínuo, estamos aprendendo a fazer anotações em muitos problemas diferentes e, eventualmente, transferir esse conhecimento para um novo problema, a fim de realizar anotações eficazes imediatamente, sem requisitos de aquecimento, "Pang disse." Nosso trabalho preliminar neste tópico foi publicado e também ganhou o prêmio de Melhor Artigo no workshop ICML 2018 AutoML. "
© 2018 Science X Network