
Prompt mostrado aos médicos para anotações. Crédito:IBM
Tempos recentes testemunharam um progresso significativo na compreensão da linguagem natural por IA, como tradução automática e resposta a perguntas. Uma razão vital por trás desses desenvolvimentos é a criação de conjuntos de dados, que usam modelos de aprendizado de máquina para aprender e executar uma tarefa específica. A construção de tais conjuntos de dados em domínio aberto geralmente consiste em texto originado de artigos de notícias. Isso normalmente é seguido por uma coleção de anotações humanas de plataformas de crowdsourcing, como Crowdflower, ou Amazon Mechanical Turk.
Contudo, a linguagem usada em domínios especializados, como a medicina, é totalmente diferente. O vocabulário usado por um médico ao escrever uma nota clínica é bastante diferente das palavras de um artigo de notícias. Assim, as tarefas de linguagem nesses domínios de conhecimento intensivo não podem ser terceirizadas, uma vez que essas anotações exigem especialização no domínio. Contudo, coletar anotações de especialistas de domínio também é muito caro. Além disso, os dados clínicos são sensíveis à privacidade e, portanto, não podem ser compartilhados facilmente. Esses obstáculos inibiram a contribuição de conjuntos de dados de linguagem no domínio médico. Devido a esses desafios, a validação de algoritmos de alto desempenho de domínio aberto em dados clínicos permanece sem investigação.
Para resolver essas lacunas, trabalhamos com o Instituto de Tecnologia de Massachusetts para construir o MedNLI, um conjunto de dados anotado por médicos, realizando uma tarefa de inferência em linguagem natural (NLI) e fundamentada no histórico médico dos pacientes. Mais importante, nós o disponibilizamos publicamente para que os pesquisadores avancem no processamento da linguagem natural na medicina.
Trabalhamos com os laboratórios de pesquisa de Dados Críticos do MIT para construir um conjunto de dados para inferência de linguagem natural na medicina. Usamos notas clínicas de seu banco de dados "Medical Information Mart for Intensive Care" (MIMIC), que é indiscutivelmente o maior banco de dados publicamente disponível de registros de pacientes. Os médicos de nossa equipe sugeriram que a história médica pregressa de um paciente contém informações vitais das quais inferências úteis podem ser tiradas. Portanto, extraímos a história médica pregressa de anotações clínicas no MIMIC e apresentamos uma frase dessa história como premissa a um clínico. Eles foram então solicitados a usar seus conhecimentos médicos e gerar três frases:uma frase que era definitivamente verdadeira sobre o paciente, dada a premissa; uma frase que era definitivamente falsa, e, finalmente, uma frase que possivelmente pode ser verdadeira.
Ao longo de alguns meses, nós amostramos 4 aleatoriamente, 683 dessas instalações e trabalharam com quatro médicos para construir o MedNLI, um conjunto de dados de 14, 049 pares premissa-hipótese. No domínio aberto, outros exemplos de conjuntos de dados construídos de forma semelhante incluem o conjunto de dados Stanford Natural Language Inference, que foi organizado com a ajuda de 2, 500 trabalhadores no Amazon Mechanical Turk e consiste em 0,5 milhões de pares premissa-hipótese em que as sentenças premissas foram extraídas de legendas de fotos do Flickr. MultiNLI é outro e consiste em textos de premissas de gêneros específicos, como ficção, blogs, conversas telefônicas, etc.
O Dr. Leo Anthony Celi (Cientista Principal do MIMIC) e o Dr. Alistair Johnson (Cientista Pesquisador) do MIT Critical Data trabalharam conosco para tornar o MedNLI publicamente disponível. Eles criaram o repositório MIMIC Derived Data, para o qual MedNLI atuou como a primeira contribuição do conjunto de dados de processamento de linguagem natural. Qualquer pesquisador com acesso ao MIMIC também pode baixar o MedNLI deste repositório.
Embora de tamanho modesto em comparação com os conjuntos de dados de domínio aberto, O MedNLI é grande o suficiente para informar os pesquisadores à medida que eles desenvolvem novos modelos de aprendizado de máquina para inferência de linguagem na medicina. Mais importante, apresenta desafios interessantes que exigem ideias inovadoras. Considere alguns exemplos do MedNLI:
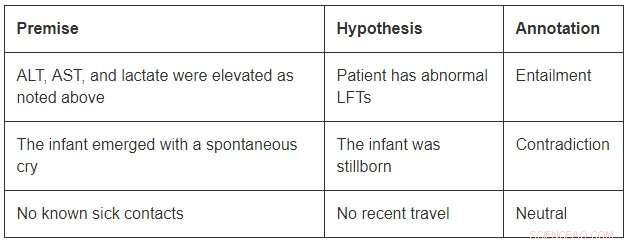
A fim de concluir a vinculação no primeiro exemplo, deve-se ser capaz de expandir as abreviações ALT, AST, e LFTs; entender que eles estão relacionados; e ainda concluem que uma medição elevada é anormal. O segundo exemplo descreve uma inferência sutil de concluir que o surgimento de um bebê é uma descrição de seu nascimento. Finalmente, o último exemplo mostra como o conhecimento do mundo comum é usado para derivar inferências.
Algoritmos de aprendizado profundo de última geração podem ter um alto desempenho em tarefas de linguagem porque têm o potencial de se tornarem muito bons em aprender um mapeamento preciso de entradas a saídas. Assim, treinar em um grande conjunto de dados anotado usando anotações de origem coletiva é frequentemente uma receita para o sucesso. Contudo, eles ainda carecem de capacidade de generalização em condições diferentes das encontradas durante o treinamento. Isso é ainda mais desafiador em domínios especializados e intensivos em conhecimento, como a medicina, onde os dados de treinamento são limitados e o idioma é muito mais matizado.
Finalmente, embora grandes avanços tenham sido feitos no aprendizado de uma tarefa de linguagem de ponta a ponta, ainda há necessidade de técnicas adicionais que possam incorporar bases de conhecimento com curadoria de especialistas nesses modelos. Por exemplo, SNOMED-CT é uma terminologia médica com curadoria de especialistas com mais de 300 mil conceitos e relações entre os termos em seu conjunto de dados. Dentro da MedNLI, fizemos modificações simples em arquiteturas de redes neurais profundas existentes para infundir conhecimento de bases de conhecimento como SNOMED-CT. Contudo, uma grande quantidade de conhecimento ainda permanece inexplorada.
Esperamos que o MedNLI abra novas direções de pesquisa na comunidade de processamento de linguagem natural.
Esta história foi republicada por cortesia da IBM Research. Leia a história original aqui.














