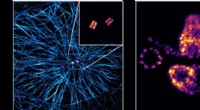
p Amostra de quadros consecutivos processados com o mecanismo de empacotamento ROI. Crédito:Athindran et al.
p Amostra de quadros consecutivos processados com o mecanismo de empacotamento ROI. Crédito:Athindran et al.
p Pesquisadores do Centro Robert Bosch para Ciência de Dados e Inteligência Artificial e Centro de Pesquisa do Cérebro Computacional, Instituto Indiano de Tecnologia Madras, e a Purdue University desenvolveram recentemente um novo método para reduzir os requisitos computacionais para a detecção de objetos em vídeos usando redes neurais. Sua técnica, chamado Pack and Detect (PaD), foi descrito em um artigo pré-publicado no arXiv. p A detecção de objetos é um aspecto fundamental de muitos aplicativos de visão computacional, como rastreamento de objetos, resumo de vídeo, e pesquisa de vídeo. Embora os avanços recentes no aprendizado de máquina tenham levado ao desenvolvimento de ferramentas cada vez mais precisas para concluir essa tarefa, os métodos existentes ainda são muito intensivos em termos de computação. Por exemplo, processar um vídeo com resolução de 300 x 300 usando a rede de detecção de objeto SSD300, com VGG16 como backbone e a 30 fps requer 1,87 trilhão de operações de ponto flutuante por segundo (FLOPS).
p Os pesquisadores observaram que, em alguns casos, Contudo, a maioria das regiões em um quadro de vídeo são meramente plano de fundo, com objetos salientes ocupando apenas uma pequena fração da área no quadro. Além disso, eles descobriram que há uma forte correlação temporal entre quadros consecutivos. Eles alavancaram essas observações e propuseram uma nova técnica para detecção de objetos em vídeos que poderia reduzir os requisitos computacionais para tarefas de detecção de objetos.
p "Fomos inspirados pelo mecanismo foveal nos sistemas de visão biológica e artificial, "Athindran Ramesh Kumar, um dos pesquisadores que realizou o estudo, disse TechXplore. "Esforços anteriores relativos aos mecanismos de atenção foveal em sistemas de visão artificial se concentram em apenas uma região da imagem ou em um objeto por vez. Nos perguntamos como seria um sistema de visão se pudesse se concentrar em todas as regiões salientes da cena ao mesmo tempo . "
p O método de detecção de objetos desenvolvido pelos pesquisadores é, portanto, inspirado por sistemas de visão biológica. Contudo, ao contrário das tentativas anteriores, seu sistema reúne todas as regiões de interesse em um único quadro, em vez de processá-los sequencialmente.
p "O objetivo do nosso trabalho era acelerar a detecção de objetos em vídeos, focando apenas nas regiões salientes no quadro e eliminando a confusão de fundo, "Balaraman Ravindran, outro pesquisador que realizou o estudo, disse TechXplore. "Para eliminar a confusão de fundo, exploramos a correlação temporal entre quadros adjacentes em um vídeo. Esta é uma propriedade que as técnicas de compressão de vídeo usam para reduzir os requisitos de armazenamento e largura de banda; nós o usamos para acelerar a computação. "
p Almofada, o método de detecção de objetos proposto por Ravindran e seus colegas funciona processando quadros em intervalos regulares em tamanho real. Esses quadros são chamados de "quadros de âncora". Em todos os outros quadros, por outro lado, a ferramenta identifica regiões de interesse com base no local em que os objetos estavam situados no quadro anterior.
p "Essas regiões de interesse são organizadas juntas como em uma colagem, que é usado como entrada para o detector de objetos, "Anand Raghunathan, um dos pesquisadores que realizou o estudo, disse TechXplore. "As detecções são mapeadas de volta para os locais na imagem original. Este método é mais rápido porque as imagens de colagem são de tamanho menor do que os quadros completos. Aproveitamos a flexibilidade dos detectores de objetos populares, como SSD300, para processar imagens em tamanho real e tamanhos menores. "
p Os pesquisadores avaliaram seu método no conjunto de dados ImageNet VID e descobriram que ele aumentou o tempo em 1,25x, com menos de 1,6% de queda na precisão. Além disso, eles observaram que o tempo necessário para processar frames de tamanho inferior era quase três vezes menor, com a contagem FLOP reduzida em quatro vezes.
p Além disso, seu estudo destacou dois aspectos importantes que podem informar o desenvolvimento de métodos mais rápidos e menos intensivos em computação para detectar objetos em vídeos. Primeiro, objetos de interesse geralmente ocupam apenas uma pequena fração de pixels em um quadro; segundo, há uma correlação entre quadros adjacentes em um vídeo.
p "Nosso trabalho pode ajudar a tornar a análise de vídeo possível em dispositivos com recursos limitados na borda da Internet das Coisas, reduzindo os requisitos computacionais, ou pode melhorar o número de streams de vídeo que podem ser processados por um servidor na nuvem, "Disse Athindran.
p O estudo realizado por esta equipe de pesquisadores é um passo inicial para o desenvolvimento de ferramentas de detecção de objetos mais eficazes. Eles agora estão planejando novas investigações que poderiam melhorar ainda mais seu método.
p Por exemplo, Atualmente, O PaD seleciona quadros de âncora em intervalos regulares, ainda assim, os pesquisadores poderiam desenvolver um mecanismo que identifica dinamicamente esses quadros-chave. Eles também planejam testar sua técnica em hardware com recursos mais limitados, como smartphones, dispositivos vestíveis e eletrodomésticos inteligentes.
p "Criamos um algoritmo para inferir as regiões de interesse e formar uma imagem de colagem, "Disse Ravindran." Mas um sistema totalmente neural teria redes neurais que geram a imagem de colagem com base no quadro anterior. Esta é uma linha mais ambiciosa de trabalho futuro. " p © 2018 Tech Xplore