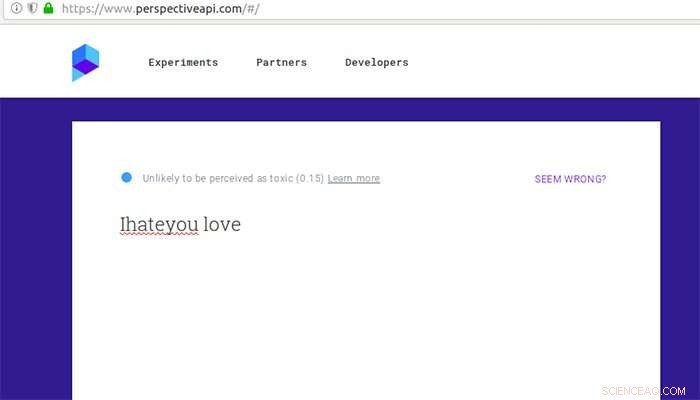
Como o Google Perspective avalia um comentário considerado tóxico após alguns erros de digitação e um pouco de amor. Crédito:Aalto University
Textos e comentários odiosos são um problema cada vez maior em ambientes online, ainda assim, resolver o problema galopante depende de ser capaz de identificar o conteúdo tóxico. Um novo estudo do grupo de pesquisa de Sistemas Seguros da Universidade Aalto descobriu pontos fracos em muitos detectores de aprendizado de máquina usados atualmente para reconhecer e manter o discurso de ódio sob controle.
Muitas mídias sociais populares e plataformas online usam detectores de discurso de ódio que uma equipe de pesquisadores liderada pelo professor N. Asokan agora mostrou ser frágil e fácil de enganar. Gramática incorreta e ortografia inadequada - intencionais ou não - podem tornar os comentários tóxicos das redes sociais mais difíceis de serem detectados pelos detectores de IA.
A equipe testou sete detectores de discurso de ódio de última geração. Todos eles falharam.
As técnicas modernas de processamento de linguagem natural (PNL) podem classificar o texto com base em caracteres individuais, palavras ou frases. Quando confrontados com dados textuais que diferem daqueles usados em seu treinamento, eles começam a se atrapalhar.
"Inserimos erros de digitação, alterou os limites das palavras ou adicionou palavras neutras ao discurso de ódio original. Remover espaços entre as palavras foi o ataque mais poderoso, e uma combinação desses métodos foi eficaz mesmo contra a Perspectiva do sistema de classificação de comentários do Google, "diz Tommi Gröndahl, estudante de doutorado na Aalto University.
A Perspectiva do Google classifica a 'toxicidade' dos comentários usando métodos de análise de texto. Em 2017, pesquisadores da Universidade de Washington mostraram que o Google Perspective pode ser enganado pela introdução de erros de digitação simples. Gröndahl e seus colegas descobriram que o Perspective desde então se tornou resistente a erros de digitação simples, mas ainda pode ser enganado por outras modificações, como remover espaços ou adicionar palavras inócuas como 'amor'.
Uma frase como "Eu te odeio" escapou pela peneira e se tornou não odiosa quando modificada para "Eu te odeio, ama".
Os pesquisadores observam que, em diferentes contextos, o mesmo enunciado pode ser considerado odioso ou meramente ofensivo. O discurso do ódio é subjetivo e específico do contexto, o que torna as técnicas de análise de texto insuficientes como soluções autônomas.
Os pesquisadores recomendam que mais atenção seja dada à qualidade dos conjuntos de dados usados para treinar modelos de aprendizado de máquina - em vez de refinar o design do modelo. Os resultados indicam que a detecção baseada em caracteres pode ser uma maneira viável de melhorar os aplicativos atuais.
O estudo foi realizado em colaboração com pesquisadores da Universidade de Pádua, na Itália. Os resultados serão apresentados no workshop ACM AISec em outubro.
O estudo faz parte de um projeto em andamento denominado "Detecção de fraude por meio de análise de texto em sistemas seguros" na Aalto University.