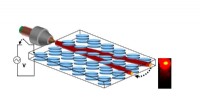
p Manuelli usa o sistema DON e o robô Kuka para pegar uma xícara. Crédito:Tom Buehler
p Manuelli usa o sistema DON e o robô Kuka para pegar uma xícara. Crédito:Tom Buehler
p Os humanos há muito tempo são mestres da destreza, uma habilidade que pode ser creditada em grande parte para a ajuda de nossos olhos. Robôs, Enquanto isso, ainda estão se atualizando. Certamente houve algum progresso:por décadas, robôs em ambientes controlados como linhas de montagem foram capazes de pegar o mesmo objeto repetidamente. p Mais recentemente, avanços na visão computacional permitiram aos robôs fazer distinções básicas entre objetos, mas mesmo assim, eles realmente não entendem as formas dos objetos, então há pouco que eles possam fazer após uma coleta rápida.
p Em um novo jornal, pesquisadores do Laboratório de Ciência da Computação e Inteligência Artificial do MIT (CSAIL), dizem que fizeram um desenvolvimento fundamental nesta área de trabalho:um sistema que permite que robôs inspecionem objetos aleatórios, e entendê-los visualmente o suficiente para realizar tarefas específicas sem nunca tê-los visto antes.
p O sistema, apelidado de "Redes de objetos densos" (DON), olha para os objetos como coleções de pontos que servem como uma espécie de "roteiro visual". Essa abordagem permite que os robôs entendam e manipulem melhor os itens, e, mais importante, permite que eles até mesmo peguem um objeto específico entre uma confusão de objetos semelhantes - uma habilidade valiosa para os tipos de máquinas que empresas como a Amazon e o Walmart usam em seus depósitos.
p Por exemplo, alguém pode usar o DON para fazer um robô agarrar-se a um ponto específico de um objeto - digamos, a língua de um sapato. A partir desse, pode olhar para um sapato que nunca viu antes, e agarrar sua língua com sucesso.
p "Muitas abordagens de manipulação não conseguem identificar partes específicas de um objeto nas muitas orientações que o objeto pode encontrar, "diz o estudante de doutorado Lucas Manuelli, que escreveu um novo artigo sobre o sistema com o autor principal e colega Ph.D. estudante Pete Florence, ao lado do professor Russ Tedrake do MIT. "Por exemplo, algoritmos existentes seriam incapazes de segurar uma caneca pela alça, especialmente se a caneca puder ter várias orientações, como vertical, ou de lado. "
p A equipe vê as aplicações potenciais não apenas em configurações de manufatura, mas também nas casas. Imagine dar ao sistema a imagem de uma casa arrumada, e deixá-lo limpar enquanto você está no trabalho, ou usando uma imagem de pratos para que o sistema guarde seus pratos durante as férias.
p O que também é digno de nota é que nenhum dos dados foi realmente rotulado por humanos; em vez, o sistema é "auto-supervisionado, "portanto, não requer nenhuma anotação humana.
p
Tornando mais fácil de entender
p Duas abordagens comuns para a compreensão do robô envolvem aprendizagem específica para tarefas, ou criando um algoritmo de compreensão geral. Ambas as técnicas têm obstáculos:métodos específicos de tarefas são difíceis de generalizar para outras tarefas, e a compreensão geral não é específica o suficiente para lidar com as nuances de tarefas particulares, como colocar objetos em locais específicos.
p O sistema DON, Contudo, essencialmente cria uma série de coordenadas em um determinado objeto, que servem como uma espécie de "roteiro visual" dos objetos, para dar ao robô uma melhor compreensão do que ele precisa entender, e onde.
p A equipe treinou o sistema para ver os objetos como uma série de pontos que constituem um sistema de coordenadas maior. Ele pode, então, mapear diferentes pontos juntos para visualizar a forma 3D de um objeto, semelhante a como as fotos panorâmicas são agrupadas a partir de várias fotos. Após o treinamento, se uma pessoa especifica um ponto em um objeto, o robô pode tirar uma foto desse objeto, e identificar e combinar pontos para poder pegar o objeto naquele ponto especificado.
p Isso é diferente de sistemas como o DexNet da UC-Berkeley, que pode compreender muitos itens diferentes, mas não pode satisfazer um pedido específico. Imagine uma criança de 18 meses, que não entende com qual brinquedo você quer brincar, mas ainda pode pegar muitos itens, versus uma criança de quatro anos que pode responder "vá pegar seu caminhão pela extremidade vermelha".
p Em um conjunto de testes feito em um brinquedo macio de lagarta, um braço robótico Kuka alimentado por DON poderia agarrar a orelha direita do brinquedo em uma variedade de configurações diferentes. Isso mostrou que, entre outras coisas, o sistema tem a capacidade de distinguir a esquerda da direita em objetos simétricos.
p Ao testar em uma caixa de bonés de beisebol diferentes, DON poderia escolher um chapéu de destino específico, apesar de todos os chapéus terem designs muito semelhantes - e nunca ter visto fotos dos chapéus em dados de treinamento antes.
p "Nas fábricas, os robôs muitas vezes precisam de alimentadores de peças complexas para trabalhar de forma confiável, "diz Manuelli." Mas um sistema como este que pode entender as orientações dos objetos poderia simplesmente tirar uma foto e ser capaz de agarrar e ajustar o objeto de acordo. "
p No futuro, a equipe espera melhorar o sistema para um lugar onde possa realizar tarefas específicas com uma compreensão mais profunda dos objetos correspondentes, como aprender a agarrar um objeto e movê-lo com o objetivo final de, digamos, limpar uma mesa.
p A equipe apresentará seu artigo sobre o sistema no próximo mês na Conferência sobre Aprendizado de Robôs em Zurique, Suíça.