 p Esquemático mostrando quais dados de contexto são extraídos do registro do paciente. Crédito:Peter Liu
p Esquemático mostrando quais dados de contexto são extraídos do registro do paciente. Crédito:Peter Liu
p Atualmente, os médicos passam muito tempo escrevendo notas sobre os pacientes e inserindo-as em sistemas de registros eletrônicos de saúde (EHR). De acordo com um estudo de 2016, os médicos gastam aproximadamente duas horas em trabalho administrativo para cada hora gasta com um paciente. Graças às ferramentas de inteligência artificial de ponta, este processo de escrita de notas pode em breve se tornar automatizado, ajudando os médicos a gerenciar melhor seus turnos e livrando-os dessa tarefa tediosa. p Peter Liu, um pesquisador do Google Brain, desenvolveu recentemente uma nova tarefa de modelagem de linguagem que pode prever o conteúdo de novas anotações analisando registros médicos de pacientes, que incluem dados como dados demográficos, medições de laboratório, medicamentos e notas anteriores. Em seu estudo, pré-publicado no arXiv, ele treinou modelos generativos usando o conjunto de dados EHR MIMIC-III (Medical Information Mart for Intensive Care), e então comparou as notas geradas pelos modelos com notas reais do conjunto de dados.
p Métodos comumente adotados para reduzir o tempo que os médicos gastam em anotações incluem o uso de serviços de ditado e o emprego de assistentes que podem escrever anotações para eles. Ferramentas de inteligência artificial podem ajudar a resolver esse problema, reduzindo os custos gastos com pessoal e recursos adicionais.
p "Recursos de escrita auxiliar para anotações, como preenchimento automático ou verificação de erros, se beneficiar de modelos de linguagem, "Liu escreve em seu artigo." Quanto mais forte o modelo, provavelmente, mais eficazes esses recursos seriam. Assim, o foco deste artigo é a construção de modelos de linguagem para anotações clínicas. "
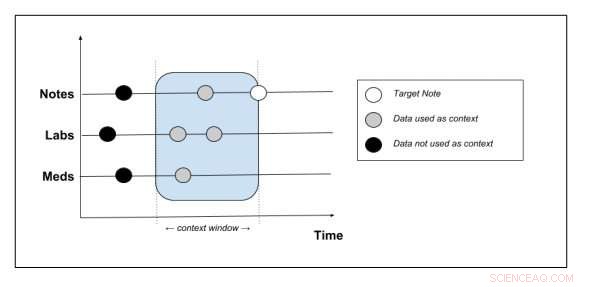
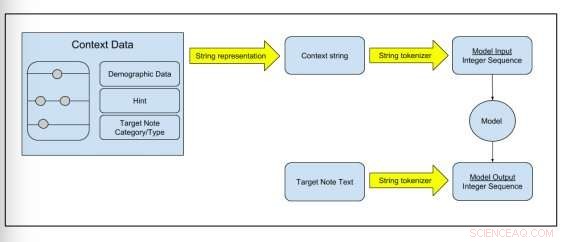 p Figura 2:Esquema mostrando como os dados brutos são transformados em dados de treinamento do modelo. Crédito:Peter Liu
p Figura 2:Esquema mostrando como os dados brutos são transformados em dados de treinamento do modelo. Crédito:Peter Liu
p Liu empregou dois modelos de linguagem:o primeiro é chamado de arquitetura de transformador, e foi apresentado em um estudo publicado no ano passado no
Avanços em sistemas de processamento de informação neural Diário. Como este modelo funciona melhor com textos mais curtos, como frases individuais, ele também testou um modelo baseado em transformador introduzido recentemente, chamado de transformador com atenção comprimida de memória (T-DMCA), que se mostrou mais eficaz para sequências mais longas.
p Ele treinou esses modelos no conjunto de dados MIMIC-III, contendo EHR desidentificado de 39, 597 pacientes da unidade de terapia intensiva de um hospital terciário. Este é atualmente o conjunto de dados EHR mais abrangente que está publicamente disponível e pode ser facilmente acessado online.
p "Introduzimos uma nova tarefa de modelagem de linguagem para notas clínicas com base em dados HER e mostramos como representar o contexto de dados multimodais para o modelo, "Liu explicou em seu artigo." Propusemos métricas de avaliação para a tarefa e apresentamos resultados encorajadores que mostram o poder preditivo de tais modelos. "
p Os modelos foram efetivamente capazes de prever muito do conteúdo das anotações dos médicos. No futuro, eles poderiam ajudar no desenvolvimento de recursos de verificação ortográfica e autocompletar mais sofisticados. Esses recursos podem ser integrados a ferramentas que auxiliam os médicos na conclusão do trabalho administrativo. Embora os resultados deste estudo sejam promissores, alguns desafios ainda precisam ser superados antes que os modelos possam ser empregados em uma escala maior.
p "Em muitos casos, o contexto máximo fornecido pelo RES é insuficiente para prever totalmente a nota, "Liu explica em seu artigo." O caso mais óbvio é a falta de dados de imagem no MIMIC-III para relatórios de radiologia. Para anotações que não são de imagem, também faltam informações sobre as últimas interações paciente-provedor. Trabalhos futuros podem tentar aumentar o contexto da nota com dados além do EHR, por exemplo. dados de imagem, ou transcrições de interações médico-paciente. Embora tenhamos discutido a correção de erros e os recursos de autocompletar no software EHR, seus efeitos na produtividade do usuário não foram medidos no contexto clínico, que deixamos como trabalho futuro. " p © 2018 Tech Xplore