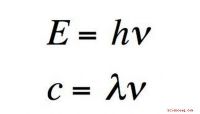
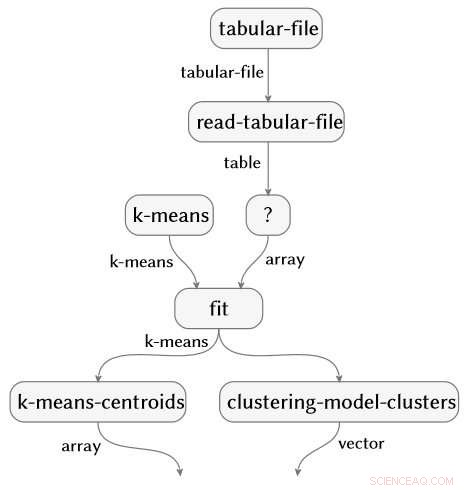
Representação de gráfico de fluxo semântico produzida automaticamente a partir de uma análise de dados de artrite reumatóide. Crédito:IBM
Vimos um progresso recente significativo na análise de padrões e inteligência de máquina aplicada a imagens, sinais de áudio e vídeo, e texto em linguagem natural, mas não tanto se aplica a outro artefato produzido por pessoas:o código-fonte do programa de computador. Em um artigo a ser apresentado no Workshop FEED no KDD 2018, apresentamos um sistema que avança na análise semântica do código. Ao fazê-lo, nós fornecemos a base para que as máquinas realmente raciocinem sobre o código do programa e aprendam com ele.
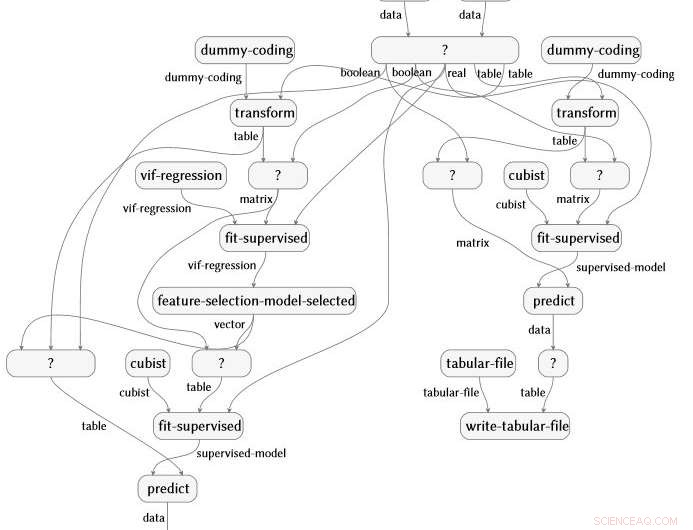
O trabalho, também recentemente demonstrado no IJCAI 2018, foi concebido e liderado pelo IBM Science for Social Good, Evan Patterson, e se concentra especificamente em software de ciência de dados. Os programas de ciência de dados são um tipo especial de código de computador, frequentemente bastante curto, mas cheio de conteúdo semanticamente rico que especifica uma sequência de transformação de dados, análise, modelagem, e operações de interpretação. Nossa técnica executa uma análise de dados (imagine um script R ou Python) e captura todas as funções que são chamadas na análise. Em seguida, conecta essas funções a uma ontologia de ciência de dados que criamos, executa várias etapas de simplificação, e produz uma representação gráfica de fluxo semântico do programa. Como um exemplo, o gráfico de fluxo abaixo é produzido automaticamente a partir de uma análise dos dados da artrite reumatóide.
A técnica é aplicável em todas as opções de linguagem de programação e pacote. Os três trechos de código abaixo são escritos em R, Python com os pacotes NumPy e SciPy, e Python com os pacotes Pandas e Scikit-learn. Todos produzem exatamente o mesmo gráfico de fluxo semântico.
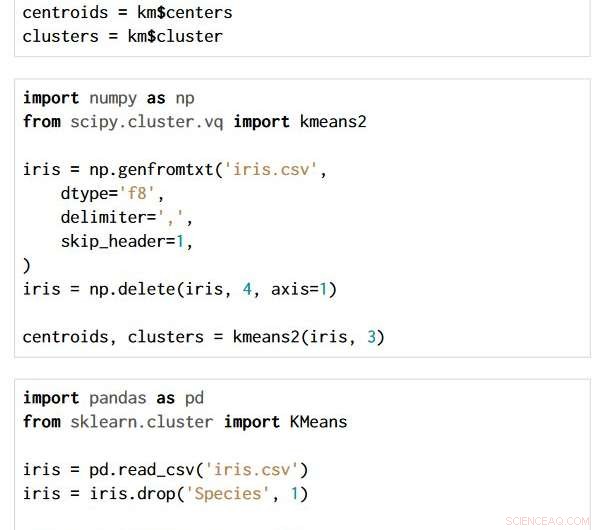
Crédito:IBM
Crédito:IBM
Podemos pensar no gráfico de fluxo semântico que extraímos como um único ponto de dados, assim como uma imagem ou um parágrafo de texto, no qual realizar outras tarefas de nível superior. Com a representação que desenvolvemos, podemos habilitar várias funcionalidades úteis para a prática de cientistas de dados, incluindo pesquisa inteligente e conclusão automática de análises, recomendação de análises semelhantes ou complementares, visualização do espaço de todas as análises realizadas em um determinado problema ou conjunto de dados, tradução ou transferência de estilo, e até mesmo a geração de máquina de novas análises de dados (ou seja, criatividade computacional) - tudo baseado na compreensão verdadeiramente semântica do que o código faz.
A Data Science Ontology é escrita em uma nova linguagem de ontologia que desenvolvemos, chamada Monoidal Ontology and Computing Language (Monocl). Essa linha de trabalho foi iniciada em 2016 em parceria com o Projeto Cura Acelerada da Esclerose Múltipla.
Esta história foi republicada por cortesia da IBM Research. Leia a história original aqui.