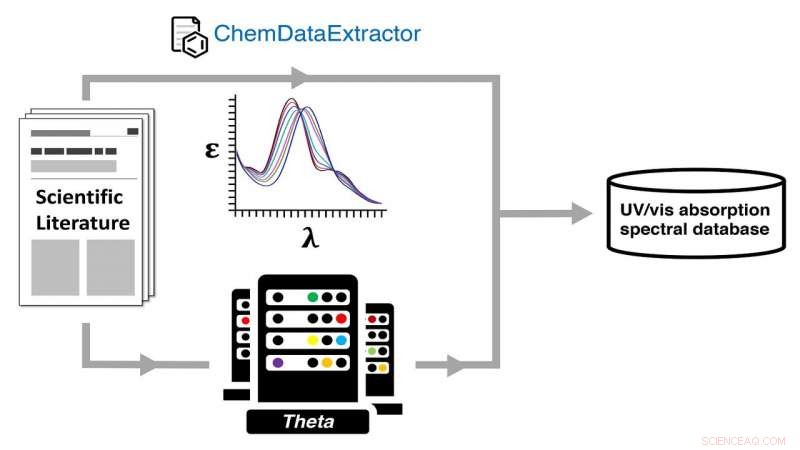
Auto-geração de um banco de dados espectral de absorção ultravioleta-visível (UV-vis) por meio de um caminho de dados químicos experimental e computacional duplo usando o supercomputador Theta do ALCF. Crédito:Jacqueline Cole e Ulrich Mayer / Universidade de Cambridge
Uma colaboração entre a Universidade de Cambridge e Argonne desenvolveu uma técnica que gera bancos de dados automáticos para apoiar campos específicos da ciência usando IA e computação de alto desempenho.
Pesquisar em resmas de literatura científica por bits e bytes de informação para apoiar uma ideia ou encontrar a chave para resolver um problema específico tem sido uma tarefa tediosa para os pesquisadores, mesmo após o início da descoberta baseada em dados.
Jacqueline Cole sabe o que fazer, tudo muito bem. Chefe de Engenharia Molecular da Universidade de Cambridge, Reino Unido, ela passou grande parte de sua carreira procurando materiais com propriedades ópticas que se prestassem a uma coleta de luz mais eficiente, como moléculas de tinta que podem um dia alimentar as janelas solares.
"Eu sabia que muitas das informações eram mantidas de forma muito fragmentada na literatura, "ela lembra." Mas se você comparar milhares e milhares de documentos, então você poderia formar seu próprio banco de dados. "
Então, Cole e colegas de Cambridge e do Laboratório Nacional de Argonne do Departamento de Energia dos EUA (DOE) fizeram exatamente isso, expondo o processo no diário Dados Científicos .
O papel, diz Cole, é uma descrição de como construir um banco de dados usando processamento de linguagem natural (PNL) e computação de alto desempenho, muito deste último realizado no Argonne Leadership Computing Facility (ALCF), um DOE Office of Science User Facility.
Entre os fatores que tornam o banco de dados único estão a escala do projeto e o fato de incluir dados experimentais e calculados em ambas as estruturas materiais, que descreve a base atômica ou química de uma coisa, e propriedades do material, a funcionalidade fornecida por essas diferentes estruturas.
"É provavelmente a primeira compilação de um banco de dados em uma escala tão grande, com 5, 380 pares iguais de dados experimentais e calculados, "diz Cole." E porque é uma quantidade tão grande, ele serve como um repositório por si só e realmente abre a porta para a previsão de novos materiais. "
Muitos novos, grandes bancos de dados são construídos puramente em cálculos, uma desvantagem inerente é que eles não são validados por dados experimentais. O último, talvez o mais significativo, fornece uma imagem precisa dos estados de excitação do material, que definem o estado dinâmico dos elétrons e são usados para calcular as propriedades funcionais de um material - propriedades ópticas, nesse caso.
Este catálogo emergente de estados excitados pode, então, ajudar a calcular as propriedades dos materiais que ainda não foram concebidos, expandindo ainda mais o banco de dados.
"Imagine que alguém deseja descobrir um novo tipo de material óptico para se adequar a uma aplicação funcional sob medida, e nosso banco de dados não contém essa propriedade ótica particular, "explica Cole." Calculamos a propriedade óptica de interesse a partir dos estados de excitação disponíveis para cada propriedade em nosso banco de dados, e criar um material com funções personalizadas. "
A equipe realizou cálculos químicos quânticos em cada estrutura para a qual extraíram dados em materiais ópticos, usando o supercomputador Theta do ALCF, criando assim o banco de dados de estruturas experimentais e calculadas emparelhadas e suas propriedades ópticas.
"Um dos maiores desafios era extrair candidatos químicos que poderiam servir como corantes para células solares de 400, 000 artigos científicos, "diz Álvaro Vázquez-Mayagoitia, um cientista da computação na divisão de Ciência da Computação da Argonne. "Desenvolvemos uma estrutura distribuída para aplicar métodos de inteligência artificial, como aqueles usados no processamento de linguagem natural, nos supercomputadores de classe mundial do ALCF. "
Para extrair automaticamente essas informações e depositá-las no banco de dados, a equipe voltou-se para o novo aplicativo de mineração de dados chamado ChemDataExtractor. Uma ferramenta de PNL, foi projetado para extrair texto especificamente da literatura química e de materiais, Onde, Cole diz, "as informações estão espalhadas por muitos milhares de papéis e estão presentes em formas altamente fragmentadas e não estruturadas."
Não é um para pesquisas manuais de artigos, Cole descreve o impulso para desenvolver o aplicativo como inovação proveniente da frustração. Inicialmente, ela tentou pacotes de PNL mais genéricos, mas observou que "eles não apenas falham, eles falham espetacularmente. "
O problema está na tradução, não tanto de uma postura de linguagem humana, mas da linguagem da ciência, embora existam algumas semelhanças.
Um escritor, por exemplo, pode usar um programa de reconhecimento de voz, uma forma de PNL, para transcrever notas ou entrevistas. O programa treina principalmente na voz do escritor, captando padrões e nuances, e começa a transcrever com bastante precisão. Agora faça uma entrevista com um sujeito com sotaque estrangeiro e as coisas começam a ficar complicadas.
No mundo de Cole, a língua estrangeira é a ciência, cada domínio é um país diferente. Atualmente, você tem que treinar o programa em apenas um "idioma, "diga química, e mesmo assim, você tem que aprender os dialetos particulares da ciência.
Químicos inorgânicos podem propor uma fórmula usando representações desconhecidas dos símbolos de elementos químicos bem conhecidos, enquanto os químicos orgânicos preferem esboços químicos numerados em uma caixa de ilustração. As informações de qualquer um deles costumam ser muito difíceis para a maioria dos programas de mineração extrair.
"E isso é apenas um pouco de química, "observa Cole." Porque a forma como as pessoas descrevem as coisas é muito diversa, a diversidade na especificidade do domínio é absolutamente crítica. "
Para esse fim, o banco de dados da equipe é um de atributos espectrais de absorção ultravioleta-visível (UV / vis), que fornece um recurso disponível abertamente para usuários que procuram encontrar materiais com cores espectrais preferidas.
Enquanto a equipe está usando o novo banco de dados para descobrir os corantes orgânicos que podem substituir os corantes metal-orgânicos tradicionais nas células solares, eles já escolheram frentes mais amplas para seu uso.
Útil como fonte de dados de treinamento para métodos de aprendizado de máquina que prevêem novos materiais ópticos, também pode ser uma opção de recuperação de dados simples para usuários de espectroscopia de absorção UV / vis, uma ferramenta amplamente utilizada em laboratórios de pesquisa em todo o mundo como uma técnica básica para caracterizar novos materiais.
“Os protocolos usados neste projeto já estão sendo implantados para tipos de projetos semelhantes, "acrescenta Vázquez-Mayagoitia." Por exemplo, a equipe recentemente aproveitou os recursos de computação ChemDataExtractor e ALCF para produzir bancos de dados expansivos de produtos químicos de bateria em potencial, e compostos magnéticos e supercondutores. "
A pesquisa em banco de dados de materiais ópticos aparece no artigo "Conjunto de dados comparativos de atributos experimentais e computacionais de espectros de absorção de UV / vis" em Scientific Data. Outros autores incluem Edward J. Beard, da Universidade de Cambridge, e Ganesh Sivaraman e Venkatram Vishwanath do Laboratório Nacional de Argonne.
Um artigo detalhando seu trabalho com materiais magnéticos e supercondutores foi publicado em npj materiais computacionais . O banco de dados de materiais da bateria contém mais de 290, 000 registros de dados foram publicados em Dados Científicos .