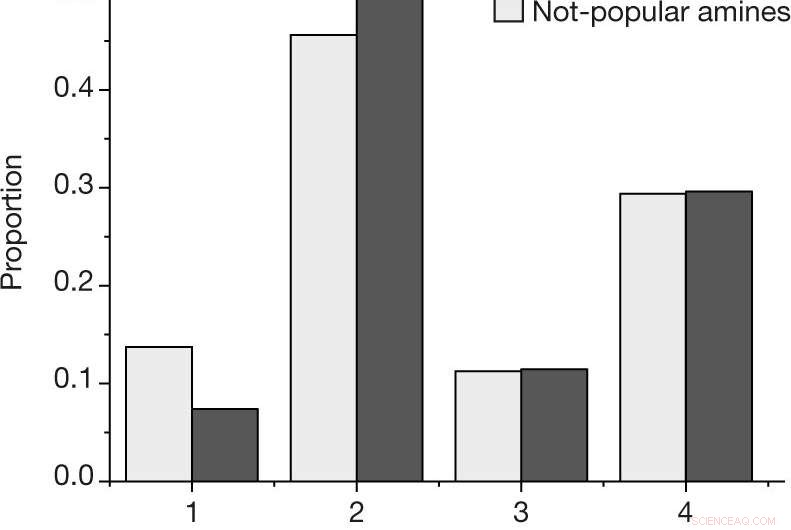
uma, A proporção por resultado para cada reação, usando a escala de resultados descrita em Métodos, para as aminas populares e não populares no conjunto de dados selecionado por humanos. b, Probabilidade estimada de observar pelo menos uma reação bem-sucedida (resultado 4) ou falha (resultados 1, 2 e 3) para uma determinada amina, para as aminas N =27 populares e N =28 não populares entre o conjunto de dados selecionado por humanos. Os valores centrais indicam a proporção observada de resultados. Barras de erro indicam uma estimativa de bootstrap do desvio padrão. Crédito: Natureza (2019). DOI:10.1038 / s41586-019-1540-5
Uma equipe de cientistas de materiais do Haverford College mostrou como o viés humano nos dados pode impactar os resultados dos algoritmos de aprendizado de máquina usados para prever novos reagentes para uso na fabricação dos produtos desejados. Em seu artigo publicado na revista Natureza , o grupo descreve o teste de um algoritmo de aprendizado de máquina com diferentes tipos de conjuntos de dados e o que eles encontraram.
Uma das aplicações mais conhecidas de algoritmos de aprendizado de máquina é o reconhecimento facial. Mas existem possíveis problemas com esses algoritmos. Um desses problemas ocorre quando um algoritmo facial destinado a procurar um indivíduo entre muitos rostos foi treinado com pessoas de apenas uma raça. Neste novo esforço, os pesquisadores se perguntaram se viés, não intencional ou não, pode estar surgindo em resultados de algoritmos de aprendizado de máquina usados em aplicativos de química projetados para procurar novos produtos.
Esses algoritmos usam dados que descrevem os ingredientes das reações que resultam na criação de um novo produto. Mas os dados nos quais o sistema é treinado podem ter um grande impacto nos resultados. Os pesquisadores observam que, atualmente, tais dados são obtidos a partir de esforços de pesquisa publicados, o que significa que são normalmente gerados por humanos. Eles observam que os dados de tais esforços podem ter sido gerados pelos próprios pesquisadores, ou por outros pesquisadores trabalhando em esforços separados. Os dados podem até vir de uma única pessoa simplesmente relatando de memória, ou por sugestão de um professor, ou um estudante de pós-graduação com uma ideia brilhante. A questão é, os dados podem ser tendenciosos em termos do contexto do recurso.
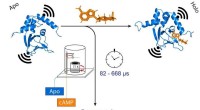
Neste novo esforço, os pesquisadores queriam saber se tais vieses poderiam ter um impacto nos resultados dos algoritmos de aprendizado de máquina usados para aplicações químicas. Descobrir, eles olharam para um conjunto específico de materiais chamados boratos de vanádio com modelo de amina. Quando eles são sintetizados com sucesso, cristais se formam - uma maneira fácil de determinar se uma reação foi bem-sucedida.
O experimento consistiu em treinar um algoritmo de aprendizado de máquina em dados que envolvem a síntese de boratos de vanádio, e então programar o sistema para criar o seu próprio. Alguns dos dados coletados pelos pesquisadores foram gerados por humanos, e algumas delas foram coletadas aleatoriamente. Eles relatam que o algoritmo treinado em dados aleatórios se saiu melhor em encontrar maneiras de sintetizar os boratos de vanádio do que quando usou dados gerados por humanos. Eles afirmam que isso mostra um claro viés nos dados criados por humanos.
© 2019 Science X Network